Real-Time Data Collection with AI Agents
AI agents collecting live data via CDC, streaming, and context stores for low-latency, accurate decisions.

Real-time data collection transforms how businesses make decisions by enabling instant insights. Unlike traditional batch processing, it processes data as events occur, reducing delays and improving decision-making accuracy. AI agents play a key role in this process, autonomously gathering, processing, and acting on live data without human intervention. By building multi-agent teams, businesses can scale these autonomous operations across complex research and data tasks.
Here’s what you need to know:
- What is it? Real-time data collection captures and processes data in milliseconds, ensuring decisions are based on the latest information.
- Why it matters: Outdated data leads to poor decisions. For example, a fraud detection system relying on old data might miss critical threats.
- AI agents' role: These systems continuously observe, reason, and act using live data feeds, ensuring relevance and precision.
- Tools and technologies: Platforms like Apache Kafka, AWS Kinesis, and Redpanda handle data streaming, while CDC techniques and Model Context Protocol (MCP) streamline integration and processing.
- Industry applications: From fraud detection in finance to dynamic pricing in retail and clinical data extraction in healthcare, real-time systems deliver measurable improvements.
To succeed, businesses need efficient pipelines, reliable tools, and expert guidance to navigate the complexities of real-time systems. Investing in these systems today positions companies to thrive in a fast-paced, data-driven world.
Key Components of Real-Time AI Data Collection
Data Source Integration
For AI agents to function effectively, they need access to reliable and up-to-date data. The first step is connecting them to the right data sources without overwhelming those systems.
Techniques like Change Data Capture (CDC) and webhook receivers make this process smoother. CDC works by monitoring transaction logs (like PostgreSQL's WAL or MySQL's binlog) to capture every insert, update, or delete in real time. On the other hand, webhook receivers are best set up to immediately store incoming payloads in a durable queue - such as Redis Streams or Amazon SQS - before returning a 200 OK response. This approach ensures asynchronous processing and prevents duplicate events caused by retries from the sender.
A newer option is the Model Context Protocol (MCP), which has emerged as a game-changer by securely bridging AI models with enterprise data sources. By 2026, MCP hit 97 million monthly SDK downloads, showcasing its rapid adoption. Teams using MCP can cut integration times dramatically, shrinking what used to take months down to just minutes - a huge advantage for organizations juggling multiple data sources.
Once the connection is established, the focus shifts to streaming the data efficiently to make the most of its real-time potential.
Streaming and Processing Technologies
After data starts flowing, the next challenge is managing it at scale and speed. Three platforms stand out for this purpose:
| Platform | Key Advantage | Best For |
|---|---|---|
| Apache Kafka | Exactly-once semantics; broad ecosystem | High-scale, parallel processing workloads |
| AWS Kinesis | Fully managed, serverless; sub-second latency | Teams already embedded in the AWS ecosystem |
| Redpanda | C++ engine; up to 10x faster tail latencies vs. Kafka | Low-latency AI inference pipelines |
For instance, in March 2026, recruitment firm InHire used Streamkap’s CDC pipeline from DynamoDB to deliver ultra-accurate candidate matches. This meant they avoided recommending candidates who had just accepted other offers or roles that had been filled moments earlier.
"With Confluent, we are giving clients the ability to move trusted data continuously across their entire operation so their AI models and agents can act on what is happening right now, not on data that is hours old." - Rob Thomas, Senior Vice President, IBM Software
But even the fastest data streams are only as good as the reliability and accuracy of the data they deliver.
Ensuring Reliability and Data Integrity
For AI agents to make correct, real-time decisions, the data pipelines feeding them must be dependable and consistent. Speed alone isn’t enough - accuracy is key.
Tools like schema registries (e.g., Confluent Schema Registry) play a crucial role by enforcing consistent data formats. This prevents downstream AI models from breaking silently when a source system changes its structure. Additionally, reconciliation jobs periodically compare record counts and checksums between the source database and the AI's vector store, ensuring no data is lost due to network issues or queue overflows.
In systems with multiple data sources writing simultaneously, conflict resolution strategies such as Last-Write-Wins (LWW) or Conflict-Free Replicated Data Types (CRDTs) help maintain consistent records.
A critical best practice when updating a vector store is to delete old chunks before inserting new ones. Skipping this step can lead to duplicate embeddings, which quietly degrade the quality of your AI agent’s data retrieval over time. For proactive monitoring, combining Prometheus and Grafana offers visibility into key metrics like sync duration, transaction counts, and error rates - allowing you to address issues before they impact AI performance.
sbb-itb-f123e37
Designing Real-time Data Architectures patterns for AI Agents | Let's Talk About Data
Designing Real-Time Data Pipelines with AI Agents
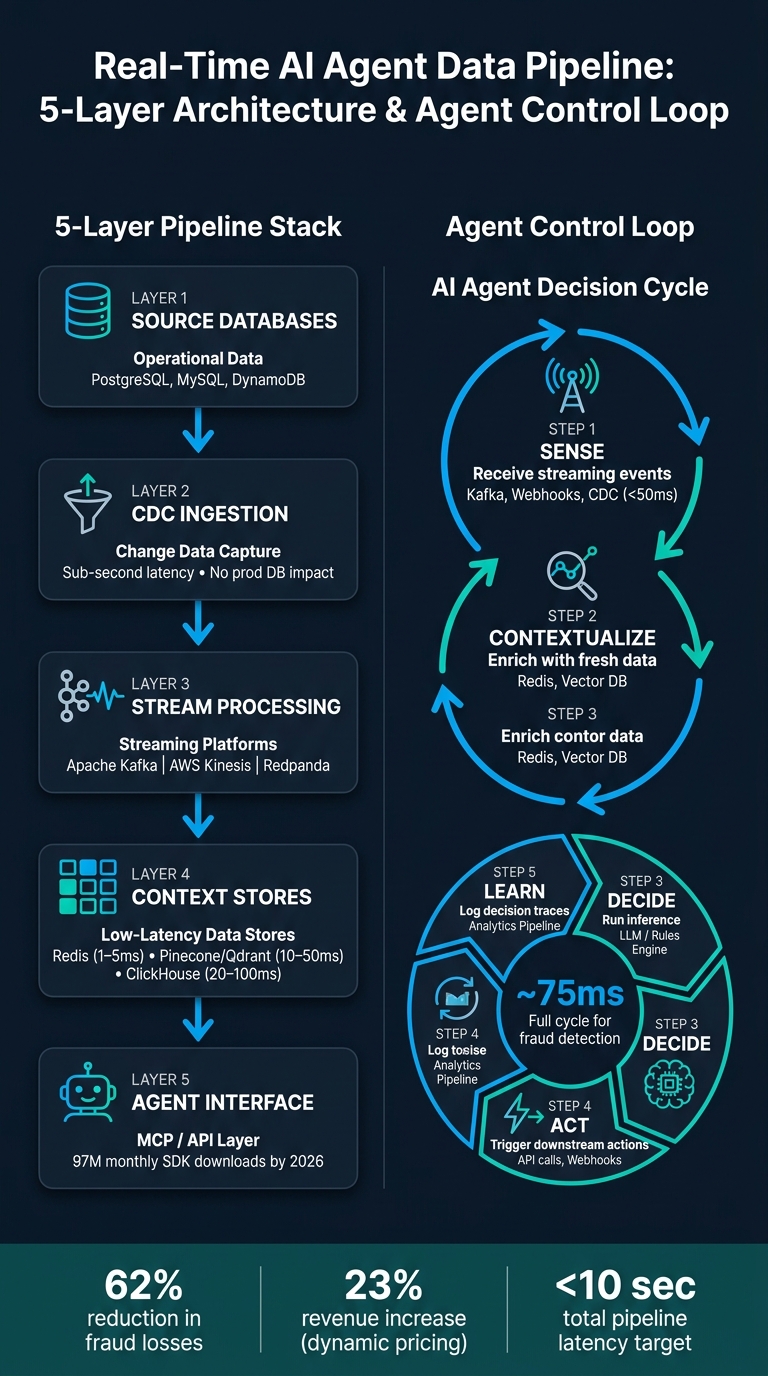
How Real-Time AI Agent Data Pipelines Work: 5-Layer Architecture
Architectural Patterns for Data Pipelines
A real-time data pipeline relies on a structured, layered approach, where each component has a specific role. Most production-grade AI agent pipelines are built on a five-layer infrastructure stack: source databases (holding operational data), CDC-based ingestion, stream processing, context stores, and agent interfaces like MCP or APIs. This design allows each layer to scale independently, making it ideal for systems that need to grow over time. The modular setup ensures the low-latency performance that AI agents demand.
The deployment pattern you choose depends on where your data is stored. For example, edge-to-cloud configurations process data close to its source, which is perfect when low latency is a must and sending raw data to the cloud would slow things down. Hybrid on-premise/cloud setups are common in industries like healthcare or finance, where some data needs to stay local. Meanwhile, multicloud architectures distribute workloads across multiple providers, improving system resilience and avoiding dependence on a single vendor.
One golden rule applies across all these patterns: don’t let AI agents interact directly with production databases. Instead, route data through dedicated low-latency stores. Tools like Redis can handle key-value lookups in 1–5ms, [vector databases like Pinecone or Qdrant enable semantic searches](https://blog.naitive.cloud/unlocking-the-potential-of-vector-databases-for-ai-agents-66e9fb2f24828d001b357321/) in 10–50ms, and ClickHouse processes time-series queries in 20–100ms. Pairing the right data store with the appropriate access pattern ensures fast inference while keeping your core systems running smoothly.
Let’s break down the stages that make this architecture work.
Stages of a Real-Time Data Pipeline
Real-time pipelines are built around three main stages: ingestion, transformation, and feature extraction. Getting these stages right is what separates a reliable production pipeline from one that only works in a demo.
Ingestion is the entry point for data. Event-driven triggers like CDC, Kafka topics, or webhooks push changes into the pipeline as soon as they happen, ensuring updates reach an agent in under 50ms. Polling, on the other hand, adds unnecessary strain to source systems and can introduce delays of several minutes.
Transformation converts raw data into actionable insights. Stream processors enrich incoming events by merging them with historical data in real time. Different windowing strategies - such as tumbling windows for fixed metrics, hopping windows for trend analysis, or session windows for tracking user interactions - help optimize how data is grouped.
Feature extraction is the final step before data is delivered to the agent. One critical optimization here is to use a buffer to consolidate multiple rapid updates to the same record into a single embedding operation. Without this step, frequent changes to a record could trigger multiple embedding calls, driving up API costs and creating unnecessary churn in your vector index. In production, systems aim for feature retrieval latencies under 100ms, with total pipeline latency (from source commit to agent access) kept under 10 seconds.
Agent-Driven Control Loops
Once the pipeline is running efficiently, AI agents can use it to complete continuous decision cycles. These cycles consist of five stages:
| Agent Loop Stage | Action | Infrastructure Component |
|---|---|---|
| Sense | Receive streaming events | Kafka, Webhooks, CDC |
| Contextualize | Enrich with fresh data | Redis, Vector DB, Stream Processing |
| Decide | Run inference or reasoning | LLM (e.g., GPT-4, Claude), Rules Engine |
| Act | Trigger downstream actions | API calls, Webhook pushes, Topic publishing |
| Learn | Log decision traces | Analytics Pipeline, Feedback Loop |
The speed of this loop is what makes real-time agents so effective. For instance, a fraud detection agent must complete the entire cycle - from sensing a transaction to taking action - in about 75ms to block fraudulent activity before it’s finalized. Every part of the pipeline, from ingestion to action, needs to be optimized to hit this speed.
"An agent that receives a streaming event within 50 milliseconds of a database row changing, enriches it with fresh context, runs inference, and takes action - that is a real-time AI agent." - Streamkap
Each pass through the loop generates a decision trace - a log of what the agent sensed, how it reasoned, and the action it took. These traces are essential for auditing and fine-tuning the system.
Real-Time Data Collection Use Cases by Industry
Real-time data collection isn't just a buzzword - it’s a game-changer across multiple industries. By building on the agent-driven control loops mentioned earlier, NAITIVE AI Consulting helps businesses solve specific challenges while unlocking measurable outcomes. Here’s how this technology plays out in key sectors.
Financial Services
Few industries feel the pressure of timely data like financial services. When it comes to fraud detection, even a slight delay can turn into significant losses.
Real-time AI agents have transformed fraud detection from periodic batch reviews to immediate, event-driven processes. For instance, a fintech company handling 12,000 transactions per minute used a CDC-based agent to enrich payment events with spending patterns and device fingerprints. This process, which takes just 75 milliseconds, led to a 62% reduction in fraud losses during the first quarter. Supporting this, the Federal Reserve Bank of Chicago reports that real-time AI fraud detection can lower fraudulent transactions by up to 30%.
But fraud prevention isn’t the only application. Real-time agents also monitor trading signals like SMA, RSI, and OBV, providing actionable "BUY/HOLD/SELL" recommendations. This shift underscores the broader advantage: enabling AI to act on current data rather than outdated snapshots.
While financial services depend on split-second decisions, retail and e-commerce leverage real-time insights to adapt to ever-changing market conditions.
Retail and E-Commerce
In retail, the lag between market trends and system updates can directly impact revenue. Real-time agents bridge this gap by optimizing dynamic pricing, inventory management, and demand sensing - all using the same principles that drive fraud detection.
- Dynamic Pricing: These agents continuously analyze competitor prices, demand signals (like weather patterns or social media trends), and live inventory levels. This approach has driven revenue per unit up by 23% during demand surges.
- Inventory Management: One e-commerce business achieved sub-500ms stock updates across 14 warehouses, reducing misrouted orders from 8% to just 0.3%. This not only cuts operational costs but also improves customer satisfaction.
- Demand Sensing: By processing real-time inputs from POS systems, search trends, and social sentiment, agents can predict demand spikes as they happen. This allows operations teams to shift their focus from manual data retrieval - once consuming 40% of their time - to more impactful tasks.
While retail thrives on market responsiveness, healthcare applications require real-time processing to handle critical, often unstructured, clinical data.
Healthcare and Life Sciences
Healthcare faces unique challenges, with as much as 80% of clinical data existing in unstructured formats like free-text notes, scanned documents, and even faxes. Without real-time agents to process this data, crucial patient information could be overlooked.
Modern clinical AI agents use NLP pipelines to extract structured data from these unstructured sources. They achieve impressive accuracy, with F1 scores of 85–95% for identifying medications, conditions, and procedures. Additionally, they excel at negation detection, discerning statements like "no history of diabetes" from actual diagnoses with 90–95% accuracy. A well-designed system completes this process in under two seconds: 500ms for OCR, 800ms for NLP, 200ms for FHIR structuring, and 500ms for vector indexing.
On the research side, these agents dramatically accelerate timelines. Tasks such as defining patient cohorts, locating clinical tables, and running survival analyses - once requiring weeks of prep - can now be completed in days using natural language prompts. To ensure reliability, every NLP-derived data point is tagged with a confidence score, helping clinicians differentiate between machine-extracted and manually entered records. Moreover, all processing must comply with HIPAA regulations, requiring a Business Associate Agreement (BAA) before any Protected Health Information enters cloud-based NLP services.
"The unstructured data pipeline is what separates a proof-of-concept AI agent from a production-grade one. Without it, your agent is blind to 80% of the clinical picture." - Nirmitee.io
How to Build and Deploy Real-Time AI Data Systems
Now that we’ve covered system components and pipeline architecture, it’s time to dive into the practical steps for building and deploying these systems effectively.
Assessing Business Requirements
Before jumping into development, it’s essential to define your system’s needs. Start by answering these three key questions: How fresh does the data need to be? How much data will the system handle? And what’s the plan if something goes wrong?
Latency requirements can vary a lot depending on the use case. For example, fraud detection systems may need decisions in under 100 milliseconds, while inventory updates can handle a few seconds of delay. A good benchmark is a maximum 10-second latency from database commit to AI data access. If your system needs faster responses, this will influence every tool you choose.
Compliance is another critical piece. Healthcare systems must meet HIPAA standards and include a BAA for handling Protected Health Information, while financial systems must comply with regulatory audits. Laying out these requirements in advance can save you from expensive redesigns later.
Once you’ve nailed down these requirements, you can start selecting the right tools for ingestion, processing, and storage.
Choosing and Integrating the Right Tools
A production-ready system typically consists of five layers: source databases, CDC ingestion, stream processing, context stores, and the agent interface. Each layer has a specific role, and the tools you choose will depend on your workload.
For data ingestion, a Change Data Capture (CDC) approach is ideal. It streams database changes with sub-second latency and doesn’t affect the performance of your production database . Managed CDC services typically start at $600/month for basic plans and can go up to $1,800/month for advanced features like data transformations.
When it comes to context storage, choosing the right tool is critical to avoid unnecessary expenses. Your decision should be based on the access patterns of your system:
| Context Store | Latency | Best For | Cost per Lookup |
|---|---|---|---|
| Redis (cache.m5.large) | 1–5ms | Key-value lookups | ~$0.000001 |
| Elasticsearch (3-node) | 5–20ms | Full-text search | ~$0.00001 |
| Pinecone / Qdrant | 10–50ms | Semantic similarity / Finetuning vs. RAG | ~$0.00001 |
| Snowflake (XS warehouse) | 500ms+ | Analytical queries | ~$0.001 |
The cost differences can be dramatic. For instance, a Redis lookup is roughly 1,000 times cheaper than a Snowflake query. If your AI agent makes dozens of lookups for each decision, these costs can add up quickly. A good rule of thumb: don’t let AI agents query production databases directly. Instead, use a dedicated context store fed through a streaming pipeline.
On the agent interface side, the Model Context Protocol (MCP) is emerging as the industry standard. By 2026, it had reached 97 million monthly SDK downloads and is supported by major players like OpenAI, Anthropic, and Microsoft. MCP separates data access from agent logic, allowing agents to securely query real-time sources without requiring custom integrations for every data source.
Given the complexity of these systems, working with experienced professionals can simplify the process.
Working with a Consulting Partner
Building a system like this in-house isn’t easy. The challenges of integration, meeting latency requirements, and ensuring governance and reliability can overwhelm teams that are still gaining experience in this area.
This is where specialized consulting firms like NAITIVE AI Consulting Agency can help. NAITIVE focuses exclusively on designing and deploying autonomous AI agent systems. They cover everything from defining latency and compliance needs to selecting the right tools for ingestion and processing, all the way to building agent interfaces. Unlike firms that simply hand over a plan, NAITIVE stays involved through deployment and offers ongoing support, ensuring your production system runs smoothly - even when things behave differently than in staging environments.
"An autonomous agent without the right data infrastructure is an expensive random number generator." - Streamkap
Ultimately, the organizations that succeed aren’t necessarily those with the biggest engineering teams. Instead, they’re the ones that combine their internal expertise with partners who have already solved these infrastructure challenges.
Conclusion: Getting the Most from Real-Time AI Agents
Real-time data collection through AI agents is delivering impressive results across various industries. For instance, fraud detection systems are identifying suspicious transactions in just 200 milliseconds, cutting fraud losses by 62%. Dynamic pricing agents are boosting revenue per unit by 23% during demand surges. Meanwhile, customer support agents leveraging live data have increased CSAT scores by 34% while reducing escalation rates from 22% to 7%. These advancements are reshaping how businesses operate, emphasizing the importance of using real-time data to drive AI actions.
The effectiveness of an AI agent depends entirely on having access to current, real-time data. Agents relying on outdated data snapshots risk making decisions that fail to align with present conditions. However, when connected to live, continuously updated data streams, they evolve into powerful tools capable of taking meaningful actions rather than just offering advice.
"Real-time data access... is what separates a useful agent from a liability." - Airbyte
The technical roadmap - incorporating CDC pipelines, stream processing, context stores, and MCP interfaces - is well-defined but undeniably complex. Navigating these challenges often requires guidance from experienced professionals. Working with specialists like NAITIVE AI Consulting Agency, which focuses on autonomous AI agent systems, can help ensure smooth operations even when unexpected issues arise.
The agentic AI market is expected to grow significantly, from $8.5 billion in 2026 to $45 billion by 2030. Businesses that invest now in building solid foundations - such as reliable pipelines, clean data, and well-managed agent interfaces - will be well-positioned to scale as the technology continues to advance. Once these foundations are in place, the next critical step is execution.
FAQs
When should I choose CDC instead of webhooks for real-time data?
Choose Change Data Capture (CDC) when you require real-time data with continuous, low-latency updates directly from your databases. CDC captures and streams changes as they occur, ensuring AI systems stay updated without putting unnecessary strain on production systems. While webhooks work well for event-driven setups, they often fall short in providing the consistent and detailed data flow needed for AI applications that demand high accuracy and immediate responsiveness.
How can I keep real-time pipelines reliable when schemas change?
To keep real-time pipelines running smoothly during schema changes, rely on change data capture (CDC) and event-driven architectures. These methods allow you to track and process updates as they happen. Set up infrastructure that supports incremental syncs and real-time ingestion - this could include tools like webhook receivers or stream processing frameworks. Regularly validating schemas, implementing version control, and designing flexible data models are key to handling schema changes effectively. This approach helps maintain data integrity while reducing the risk of pipeline interruptions.
What’s the simplest way to stop AI agents from querying production databases?
Preventing AI agents from directly accessing live data streams or production databases is a straightforward yet effective approach. Instead, you can rely on methods like Change Data Capture (CDC) or streaming pipelines to keep a separate, dedicated data store updated. This setup allows agents to query this intermediate data layer, ensuring they only access the information they need. At the same time, this approach safeguards your production database from potential overload or unintended modifications.



