5 Trends in Multilingual Voice AI for Enterprises
Multilingual voice AI succeeds when translation, accent‑aware ASR, LLM orchestration, and deployment controls work together.

Multilingual voice AI is now a core business system, not a side feature. In 2026, the main pattern is clear: companies get the fastest return when they focus on support automation, accent-aware ASR, speech-to-speech translation, LLM-led response control, and deployment rules like latency, security, and AI disclosure.
I’d sum up the article this way: if you serve more than one language, your results now depend on five things working together. You need live translation that stays under about 600 ms, speech recognition that can deal with code-switching and accents, self-service flows that can finish common requests, language-specific response handling that sounds natural, and rollout controls that track quality by language. The business case is strong too: the conversational AI market hit $17.97 billion in 2026, 67% of Fortune 500 companies already use voice AI in production, and multilingual support can cut payback from 14 months to 9 months.
Here’s the short version:
-
Trend 1: Real-time speech-to-speech translation
Best for live support and meeting translation, with cost as low as $0.034 per minute. -
Trend 2: Accent- and dialect-aware ASR
Needed for markets where callers mix languages or speak with strong regional variation. -
Trend 3: Global customer support automation
The clearest near-term ROI, especially for 24/7 self-service. -
Trend 4: LLM orchestration for multilingual agents
Helps one knowledge base serve many languages with the right tone and wording. -
Trend 5: Deployment, security, and scaling
Covers latency, routing, compliance, token cost, and language-level monitoring.
How ElevenLabs is Solving Multi-Language Voice Development Challenges
sbb-itb-f123e37
Quick Comparison
| Trend | What it solves | Best fit | Readiness | Main rollout issue |
|---|---|---|---|---|
| Real-time speech-to-speech translation | Live language gaps | Support, meetings, webinars | High for major languages | Latency and routing design |
| Accent & dialect-aware ASR | Misheard speech | Code-switching and regional markets | Medium | Testing on live call audio |
| Global customer support | End-to-end self-service | High-volume service tasks | High | Flow design and resolution rate |
| LLM orchestration | Tone, wording, and task quality | Regulated and multi-market support | Emerging | Fixed text for legal language |
| Deployment & security | Scale, compliance, cost | Enterprise-wide rollout | High | Regional hosting and monitoring |
If I were planning a rollout with an expert partner, I’d start with Trend 3 and Trend 5 first, then layer in the rest based on language volume and call complexity.
1. Real-Time Speech-to-Speech Translation
Real-time speech-to-speech translation is replacing the old multi-step flow of ASR, translation, and TTS with a single streaming model that manages the whole conversation. That shift matters in live customer interactions, where even a short delay can hurt satisfaction and conversion.
Enterprise Operational Impact
A UK-based motor insurer used multilingual voice AI to serve Urdu, Polish, and Bengali speakers, who made up about 12% of its market, and cut handle times by 4x while removing language-specific queues. On a broader level, multilingual coverage can shorten voice AI payback from 14 months to 9 months by reaching markets that were out of reach before.
Production Readiness
As of May 2026, GPT-Realtime-Translate supports continuous speech-to-speech translation across 70+ input languages and 13 output languages for $0.034 per minute. For smooth conversation, end-to-end latency should stay under 600 ms. Once delay goes past 1.2 seconds, callers start to notice it.
That bar is within reach for high-volume languages like English, Spanish, and French. Lower-resource languages such as Swahili and Tagalog often land closer to 800 ms to 1,200 ms.
That level of performance is why customer support is the first big enterprise use case.
Primary Enterprise Use Case
The main use case is multilingual customer support for FAQs, order status, and service requests. It can also handle live translation for webinars and meetings at about $2.04 per hour.
Implementation Complexity
The core workflow - ASR, language detection, translation, and TTS - sounds simple on paper. In practice, architecture choices shape speed and call quality.
A pivot-language setup translates speech into English for reasoning, then translates it back into the target language. That approach adds 300–600 ms of latency and can flatten prosody and nuance. Native multilingual models avoid that extra delay, but they cover fewer languages.
That’s why a hybrid setup makes sense for most enterprises: Working with an AI consulting agency can help navigate these architectural trade-offs.
- Native models for high-traffic language pairs
- Pivot-language routing for long-tail languages
Per-utterance detection is also more resilient than call-start detection because it handles code-switching - when callers switch languages mid-sentence - more effectively.
Even then, translation solves only part of the problem. The next bottleneck is how well systems deal with accents and dialects.
2. Accent- and Dialect-Aware Speech Recognition
Translation falls apart when speech recognition misses the accent underneath the words. For English voice AI, one “standard” model isn’t enough. A system that works on standard American English can still stumble badly with callers from Atlanta or Mumbai.
Enterprise Operational Impact
When ASR gets a regional accent wrong, the damage spreads fast. Calls get sent to the wrong queue, intent matching falls apart, and key details disappear. On code-switched audio, monolingual ASR can see a 30–50% WER jump, which pushes up handle time and hurts first-call resolution.
Regional word choice adds another layer of risk. A small difference like “let” versus “rent” in UK English can route a caller to the wrong team.
Production Readiness
As of 2026, unified multilingual models are the production standard for real-time code-switching. They can handle language shifts in the middle of a sentence in a single forward pass, which removes the separate language ID step that adds 70–200 ms of latency.
A June 2026 ServiceNow-AI benchmark named ElevenLabs Scribe V2 and AssemblyAI Universal-3 Pro as top performers across HR and IT support scenarios. The study also found that errors were concentrated out of proportion on the English parts of code-switched utterances. For live calls, the target is under 5% WER.
Even with that progress, regional variants such as Scottish English, Singaporean Mandarin, and Caribbean Spanish still need dialect-specific testing. If you skip that step, performance can drop off a cliff.
Primary Enterprise Use Case
Markets with heavy code-switching offer the best ROI, especially US-Hispanic (Spanglish) and Indian (Hinglish) use cases. In early 2026, a bilingual English/Spanish intake agent for personal injury law firms reached a 95% case capture rate. That result came from dialect-aware recognition across Mexican, Caribbean, and Central American callers.
Accent-aware ASR also supports real-time agent assist and post-call compliance analytics in banking and healthcare.
Implementation Complexity
Test on your own call audio, not polished benchmark sets. A clean lab result doesn’t mean much if your live traffic sounds different.
Use at least six months of production recordings, group them by dialect, and run candidate engines against that mix. Adding the top 500 domain-specific terms to a custom vocabulary can cut errors on those terms by 40–60%. And when volume passes 10,000 calls per language per year, use dedicated localization.
Once ASR works across accents and dialects, multilingual support gets a lot easier to run without splitting teams and workflows.
3. Voice AI for Global Customer Support
Once ASR can handle accents with a high success rate, the focus changes. The issue is no longer Can the system understand the caller? It becomes: Can it finish the job from start to finish? That’s the point where multilingual voice AI stops being a transcription tool and starts working like a service channel.
Enterprise Operational Impact
Multilingual voice AI gives companies more coverage across languages and time zones without building separate call centers for each region. That matters because non-primary-language speakers often spend 4x longer on calls than English speakers when they’re pushed through standard queues. Cutting that delay helps on both sides: customers get answers faster, and support costs drop.
It also scales better than running separate bots for each language. Supporting ten languages is closer to 1.2x the maintenance effort, not 10x. That changes the math in a big way. Enterprises using agentic voice AI report 55% to 71% lower global support costs than teams using old staffing models.
Production Readiness
Language coverage alone doesn’t mean much if the system still has to hand the call to a person. The real benchmark is whether routine requests can be finished without human help.
Tier 1 languages - English, Spanish, French, German, Japanese, Mandarin, and Portuguese - are ready for business use, with ASR accuracy at 95% to 98%. Even so, there’s an important line here: structured tasks like appointment booking and order status checks work far better end to end than messy, open-ended investigations.
The big production move is from legacy IVR to agentic IVR. Instead of just pushing callers through menus, these systems can authenticate users, pull CRM records, process payments or identity changes, and confirm the result without a handoff. Teams that reach 70%+ full-resolution rates often see payback in 12 to 18 months.
Primary Enterprise Use Case
The clearest ROI case is 24/7 multilingual self-service for high-volume, repetitive work. Think:
- Order status
- Account management
- Scheduling
- Policy FAQs
This isn’t just about routing callers to the right language line. It’s about end-to-end self-service in that language. That difference is where a lot of the value shows up.
Market growth is the other major driver. Companies that add native-language support see 15% to 25% higher conversion rates in those markets in the first quarter. On top of that, customers served in their preferred language show 30% higher retention rates.
Implementation Complexity
A 90-day rollout pattern has started to look like a solid starting point. The flow is simple:
- First 30 days: segment inbound call audio by dialect and language
- Next 30 days: finalize the architecture
- Final 30 days: pilot the hardest language pair first
One compliance detail can slip through the cracks if teams aren’t careful. Disclosures - such as EU AI Act Article 50 requirements - should be built directly into product logic so the right disclosure triggers automatically in the caller’s detected language.
4. Multilingual Voice Agents with LLM Orchestration
Once support flows work from start to finish, the next limit is response quality. Speaking Spanish is one thing. Sounding natural in Spanish is another.
Formality, terminology, and brand tone need to match the caller's language. Basic translation layers tend to stay literal. They miss social register, drop domain terms, and often sound robotic. LLM-orchestrated agents handle this with per-language prompt overlays. That means the system can shift tone and form by language - formal Japanese versus casual US English, for example - while still pulling from one canonical knowledge base, usually in English, to produce accurate, context-aware replies in the caller's language.
That setup also cuts translation drift. Instead of keeping separate localized documents aligned over time, teams can work from one source of truth.
Enterprise Operational Impact
This changes day-to-day operations in a big way. One orchestration layer can push policy updates across every language at the same time, a key benefit of multilingual voice agents. That helps keep enforcement aligned across markets and supports 24/7 regional coverage without adding more local headcount.
The next pressure point is different: how the system deals with accents, dialects, and speech that moves between languages.
Production Readiness
Modern realtime APIs such as GPT-4o and Gemini Live now reach sub-second turn-taking latency, roughly 600–800 ms. That's fast enough to feel natural in a live conversation.
The hard part is not raw speed. It's handling mixed-language speech and keeping key terms fixed for industry vocabulary. In the UK, more than 50% of bilingual conversations include at least one language switch inside a single utterance. So for production systems, code-switching is not some rare corner case. It's a core requirement.
Primary Enterprise Use Case
The best ROI tends to come from a few clear use cases:
- Self-service resolution for Tier 1 interactions
- After-hours regional support
- Regulated sectors such as finance and healthcare, where native-level linguistic fidelity is required
Common examples include healthcare appointment confirmations, fintech collections in Spanglish-heavy markets, and insurance claims intake for non-native speakers.
Implementation Complexity
A smart first move is shifting from menu-based routing to passive language detection. The goal is to identify the caller's language within the first 1–3 seconds of speech at 95%+ accuracy. It cuts friction right away.
LLM orchestration can tailor responses, but regulated language should stay fixed. High-stakes disclosures - like HIPAA notices or Mini-Miranda warnings - should be stored as fixed, professionally translated text, not generated live.
Once orchestration is stable, the next challenge is security and rollout discipline.
5. Enterprise Deployment, Security, and Scaling
Orchestration is only half the job. The other half is making sure the system doesn’t fall apart when you run it across regions, under compliance rules, and with thousands of calls hitting it at the same time.
At this point, the question changes. It’s not “Can this work?” anymore. It becomes: What does it cost? How fast is it? Does it meet compliance rules? Can we see problems before customers do?
Enterprise Operational Impact
At scale, multilingual voice AI can cut per-call cost from $7–$17 to $0.30–$0.50 per call. That kind of drop changes the math of global support in a big way. Adding three or more languages can also shorten payback because coverage expands faster.
Production Readiness
Pilot results don’t tell you enough. Production performance depends on language-level monitoring.
That means teams need per-language dashboards, dialect-specific tests, and KPI reporting for each language on its own. Task Completion Rate, Mean Time to Resolution, and Sentiment should be tracked separately by language so a failure in one market doesn’t get buried inside blended reporting.
The same code-switching and accent issues that hurt recognition also affect rollout plans, monitoring, and routing. In production, those details aren’t edge cases. They shape the whole setup.
Natural conversation needs sub-600–800 ms end-to-end latency. If EU caller audio gets routed through US-hosted infrastructure, that alone adds about 1,000 ms of round-trip latency. That’s enough to make the call feel broken. So at scale, regional co-location with telephony infrastructure isn’t optional.
Secure audio, transcripts, and prompts with role-based access, encryption, and region-specific retention rules.
Once latency is under control, compliance usually becomes the next choke point.
Primary Enterprise Use Case
The biggest volume gains come from predictable, high-frequency intents like:
- order taking
- FAQ answering
- sales support
- lead qualification
- appointment scheduling
These are the most practical places to start for global self-service.
Starting August 2, 2026, EU AI Act Article 50 requires callers to be told when they’re speaking with AI, and that disclosure has to be given in a language they understand. That turns disclosure routing into a procurement issue, not just a legal footnote.
Implementation Complexity
Deployment success depends on routing, governance, and cost control, not just model accuracy.
A 90-day rollout can help teams segment audio, lock down routing, and pilot the hardest language pair first. That approach gives you a better read on what breaks early, before the system is pushed into a larger launch.
One cost issue that gets missed all the time is tokenization. The same sentence may use 5 tokens in English and up to 16 in Hebrew. That has a direct effect on LLM inference cost at scale. So before signing any usage-based contract, benchmark token use against actual target-language audio, not lab assumptions.
Comparing the 5 Trends at a Glance
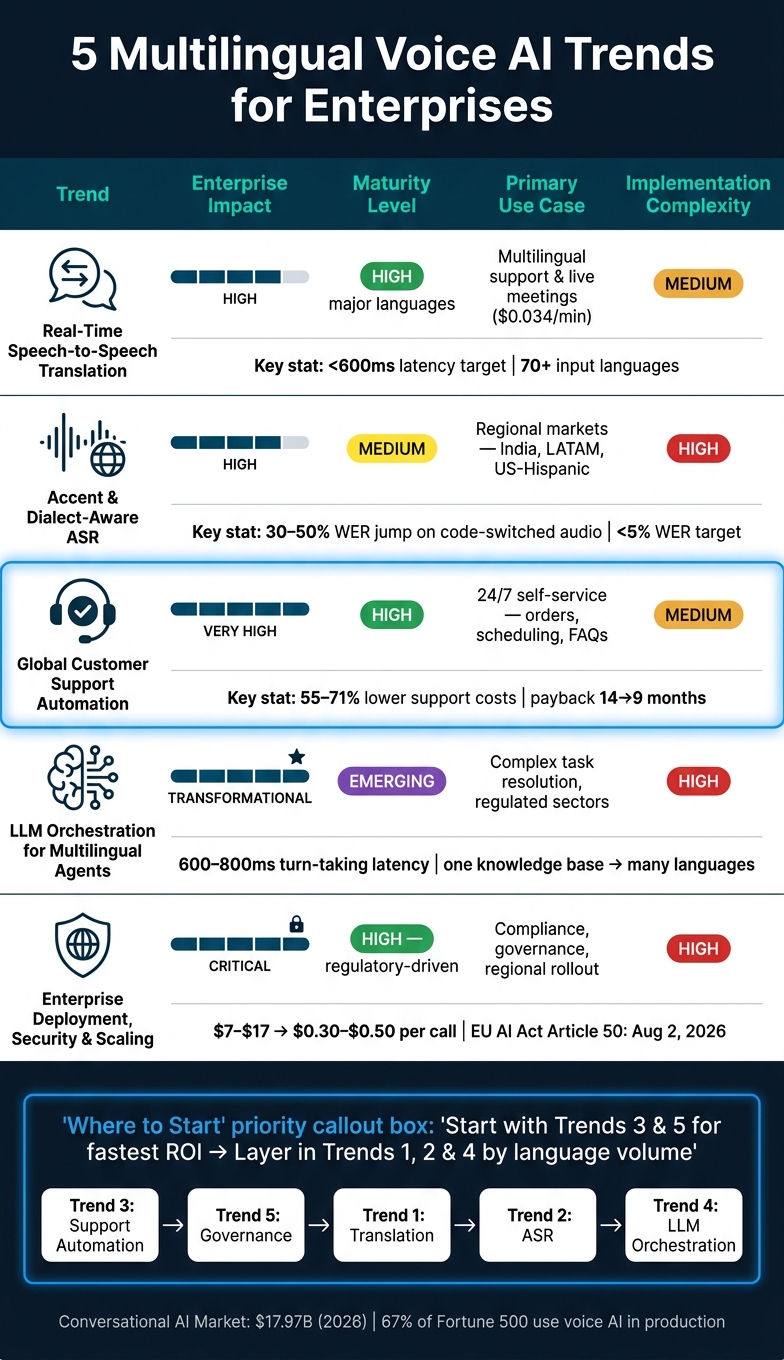
5 Multilingual Voice AI Trends for Enterprises: Impact, Maturity & ROI
These five trends address different enterprise bottlenecks: translation, recognition, service completion, response quality, and compliance. This comparison helps tie each trend to business impact, maturity, use case, and rollout complexity.
| Trend | Enterprise Impact | Maturity Level | Primary Use Case | Implementation Complexity |
|---|---|---|---|---|
| 1. Real-Time Speech-to-Speech Translation | High | High (high-volume language pairs) | Intermittent multilingual use and long-tail languages | Medium |
| 2. Accent & Dialect Awareness | High | Medium | Regional markets (e.g., India, LATAM) | High |
| 3. Global Customer Support | Very High | High | Scaling CX without regional headcount | Medium |
| 4. LLM orchestration | Transformational | Emerging | Complex task resolution and autonomy | High |
| 5. Enterprise Deployment & Security | Critical | High (regulatory-driven) | Compliance and governance | High |
The main split here is simple: some trends drive near-term operating gains, while others point toward longer-range autonomy.
Trends 3 and 5 are the most practical near-term priorities for most enterprises. Trend 3 gives the clearest near-term ROI. Trend 5 is the governance gate for every deployment, especially with EU AI Act Article 50 taking effect on August 2, 2026.
Trend 4 has the biggest upside because it shifts voice AI from answering questions to completing tasks. And the gap between adopters and non-adopters is material. Trend 2 also gets overlooked more than it should, because accuracy still drops on regional accents and dialects.
The next section turns this comparison into a rollout decision, or you can consult a specialized AI agency for custom implementation.
Conclusion
Multilingual voice AI has moved past the test phase. It’s now part of production infrastructure. For U.S. companies, the main question isn’t if they should use it. It’s where to start to get the fastest return.
That change matters for a simple reason: the use cases with the fastest payback are support automation, global expansion, and customer experience at scale. And if a company serves three or more markets, payback can drop from 14 months to 9 months.
But ROI doesn’t come from good slides or pilot demos. It comes from solid production discipline. The companies that pull ahead are the ones that handle accent variation, code-switching, dialect drift, and live language switching in production, not just in planning docs. That’s the line that separates teams that talk about multilingual voice from teams that make it work.
Treat multilingual voice as core architecture. Translation, accent handling, support automation, orchestration, and governance need to be built as one system. When those pieces are planned together, the setup is much more likely to hold up under live demand.
FAQs
Where do we start with multilingual voice AI?
Treat multilingual voice AI as an architecture choice, not just another feature on the roadmap.
Before you talk to vendors, get clear on your setup. Decide whether you want one model across all languages or separate models for each language. Then make a second call: should language detection happen once at the start of the call, or on each utterance so the system can handle code-switching?
That second choice matters more than it may seem. A customer might start in English, switch to Spanish mid-sentence, then switch back again. If your system can’t keep up, the experience falls apart fast.
NAITIVE AI Consulting Agency helps businesses design and manage autonomous voice agents so they can scale cleanly and keep performance steady across global markets.
How do we know which languages are ready for automation?
Don’t take vendor claims at face value. Test the system end to end on your call mix, using your own inbound audio so you can see how it handles accents, dialects, and code-switching in practice.
It also helps to group languages by readiness. A Tier-1 language might be ready for production, while a Tier-3 language may still need a translation bridge or human support. And if the AI can’t identify the language or manage the interaction with enough accuracy, build in a smooth handoff to a human agent.
What metrics should we track by language?
Track KPIs by language and dialect, not just as one blended number. The metric that matters most is Word Error Rate (WER), measured against your actual inbound audio mix, because accuracy can shift a lot by accent.
You should also track:
- containment rate
- average handle time
- post-interaction CSAT
- escalation frequency
- sentiment by language
That extra layer matters. It helps you spot cultural friction, accent-related issues, or translation gaps that broad reporting can easily hide.



