Data Privacy in Custom ASR Systems
Control collection, reuse, access, retention, transfer, and deletion of voice data across custom ASR pipelines to reduce legal, compliance, and security risk.

If privacy is not built into custom ASR from day one, voice data can spread across transcripts, logs, backups, analytics tools, and vendor systems within minutes. That is where deletion gets hard, legal risk grows, and one spoken detail can turn into a long-term data problem.
As part of our AI consulting work, we often boil the core privacy challenges down this way:
- Voice data is high-risk data. It can include names, card numbers, health details, account data, and even biometric identifiers.
- The risk is not just the audio. Transcripts, metadata, audit logs, and training datasets can all hold personal data.
- Reuse is a big problem. The article notes that 70% of vendor agreements reviewed allowed audio use for training or sharing with partners.
- The law follows the full data path. GDPR, HIPAA, CCPA/CPRA, and BIPA can all apply based on what the system does and whose data it handles.
- The first controls to put in place are clear: opt-in consent, no default training reuse, encryption, redaction, access limits, and automated deletion across every system.
Here’s the short version in plain English:
- If your ASR system handles PHI, every vendor in the chain needs the right HIPAA paperwork.
- If it uses voice for identification or verification, you may be handling biometric data and need stronger consent rules.
- If audio goes to cloud vendors or crosses borders, you need to check transfer and contract rules.
- If raw audio, transcripts, and logs all use the same retention rule, deletion requests can break down fast.
The main point: custom ASR privacy is not just about securing recordings. It is about controlling collection, reuse, access, retention, transfer, and deletion across the whole pipeline.
That’s the lens I’d use to read the rest of the article.
Where Custom ASR Projects Run Into Privacy and Security Problems
How Sensitive Data Spreads Across Audio, Transcripts, and Metadata
Voice data starts spreading the moment a call begins. One interaction can produce raw audio, a transcript, sentiment scores, escalation flags inside a CRM, and diagnostic logs in tools like Datadog or Splunk - all before anyone has reviewed the call. And every copy adds another privacy risk.
Even metadata that looks routine can still help re-identify someone long after the recording itself is gone.
| Pipeline Stage | Data Generated | Primary Risk |
|---|---|---|
| Speech-to-Text | Audio + Transcript | Provider infrastructure access; retention in ASR logs |
| Post-Processing | Transcript + Prompt Context | Data reuse for training; cross-border transfer |
| Storage/Backups | Recordings + Metadata | Unauthorized internal access; lack of deletion enforcement |
| Analytics | Sentiment/Intent scores | Re-identification via contextual clues |
The problem gets harder to manage when that same audio is pulled back in for tuning, testing, or later analysis.
How Training and Model Updates Create Hidden Data Reuse Risk
One of the less obvious risks is reuse. Audio collected for live operations - billing calls, patient check-ins, customer support - often ends up in fine-tuning or error analysis workflows. In many cases, that happens by default.
That matters because once sensitive data makes its way into model weights, removing it becomes hard. In some cases, it can also get in the way of full erasure under GDPR. A review of vendor agreements found that 70% included clauses that allowed audio samples to be used for model training or shared with "trusted partners".
At that stage, the issue isn't just a system design problem. It's a governance problem too.
How Weak Governance Turns Technical Gaps Into Compliance Incidents
Technical gaps turn into compliance incidents when governance doesn't hold the line. Most of the time, the weak spot is the vendor chain.
A typical ASR stack sends data through telephony, STT, post-processing, and hosting, often across several vendors. If the main vendor has a Business Associate Agreement (BAA) but upstream providers do not, the whole data path can fall out of compliance.
Broad access and vague deletion rules make things worse. When one platform applies a single retention period across raw audio, transcripts, metadata, and audit logs, handling narrow deletion requests becomes almost impossible without keeping sensitive data longer than needed. Cross-border transfers add yet another layer of risk.
Those are the pressure points GDPR, HIPAA, and state privacy laws are meant to cover.
sbb-itb-f123e37
Rev's AI Security, Governance, & Privacy
What GDPR, HIPAA, and U.S. State Privacy Laws Require From ASR Systems
These rules don't stop at storage. They shape how voice data is collected, processed, moved, and deleted. For enterprise ASR teams, compliance has to be built into the system from the start. It affects consent, contracts, retention, and access control in very direct ways.
How GDPR Applies to Voice Data and Custom ASR Workflows
With ASR, the main issue isn't speech recognition on its own. It's the collection and transfer of biometric voice data. Under GDPR, biometric voice processing needs a stronger lawful basis, a DPIA, and written vendor agreements. In many cases, that means explicit consent, not a broad legitimate-interest claim.
A DPIA is required before high-risk ASR deployments. Organizations also need a written Data Processing Agreement (DPA) with every vendor in the ASR stack, including telephony, STT, LLM, and TTS providers. That requirement also applies to sub-processors.
Cross-border transfers make things more complex. If audio is stored in the EU but processed by a U.S.-based model provider, that counts as an international transfer. In that case, Standard Contractual Clauses (SCCs) and a Transfer Impact Assessment (TIA) are required.
How HIPAA Applies When Recordings or Transcripts Contain PHI
Once ASR handles patient-related speech, the legal issue shifts fast. At that point, the focus is no longer just transcription quality. It's protected health data. When ASR touches PHI, including audio, transcripts, and related metadata, HIPAA requires BAAs, encryption, and retention controls.
Every vendor that touches that data is a Business Associate (BA) and must have a signed Business Associate Agreement (BAA). That includes every vendor and sub-processor in the chain: telephony providers, STT engines, LLM APIs, and cloud storage.
On the technical side, data must be encrypted in transit with TLS 1.3 and at rest with AES-256. Audit logs must be kept for 6 years under the HIPAA Security Rule, even if raw audio is deleted much sooner. Use only HIPAA-eligible services with signed BAAs.
How State Biometric and Privacy Laws Add Further Obligations
California's CCPA/CPRA treats voiceprints as sensitive personal information, which gives consumers stronger opt-out rights. State biometric laws, including Illinois' BIPA, require explicit opt-in consent before collecting audio features used to identify or verify people by voice.
The compliance burden doesn't end with the recording itself. Call metadata may count as derived PII under some state laws, so it needs its own controls. If a company operates across several states, it has to map actual ASR data flows against each state's rules. Retention, consent, disclosure, and secure destruction can differ from one state to another.
| Data Class | Typical Enterprise Practice | Required Controls |
|---|---|---|
| In-call audio | Ephemeral (call + 30s) | Consent, encryption, deletion at call termination |
| Transcripts | 30–90 days | Time-based auto-purge, access controls |
| Audio archive | 90 days | Manual hold or auto-purge, BAA/DPA coverage |
| Metadata | 6–7 years | Statutory retention, audit logging |
| Training corpus | Opt-in only | Explicit consent, deletion on withdrawal |
Source:
These obligations form the baseline for the technical controls that follow.
Technical and Operational Controls That Reduce ASR Privacy Risk
ASR Privacy Safeguards: Risks, Controls & Compliance at a Glance
How to Build Privacy Controls Into the Data Pipeline
After the legal rules are in place, the next job is stopping voice data from spreading across systems. The safest move is to cut risk at ingress, before audio gets copied, shared, or stored in places that are harder to govern. Encrypt audio at ingress and at rest with TLS 1.3 or TLS 1.2 and AES-256.
Encryption helps, but system design matters just as much. A transcript-first setup keeps the risk window short: convert raw audio to text as soon as possible, then delete the audio. If raw audio sticks around after transcription, the attack surface grows.
Once the transcript exists, run Named Entity Recognition (NER) to redact PII and PHI before the text moves into downstream systems like an LLM, a CRM, or an analytics dashboard. Automated de-identification should remove credit card numbers, email addresses, phone numbers, and account numbers. That way, downstream apps and dashboards don’t end up holding raw personal data.
In high-sensitivity settings, on-device or private-VPC models can keep audio inside the corporate network and cut third-party exposure. It also helps to use customer-managed keys in HSMs so the enterprise controls who can decrypt data. Decryption should be limited to secure enclaves.
How to Limit Access, Monitor Use, and Enforce Deletion
This is where many ASR programs stumble: access control and deletion are often uneven or incomplete. Apply RBAC and MFA across audio storage, transcript databases, and model training environments. Keep development and production data separate. Training datasets should sit in isolated systems, with retention and deletion schedules tied to consent status.
Privacy problems show up fast when access rules, logging, and deletion don’t follow the data through every system that touches audio or transcripts. Audit logs should be immutable and cryptographically signed, with records of who accessed what, when, and why. Deletion workflows should run automatically across audio storage, transcript databases, and analytics systems.
There isn’t one blanket retention rule for Voice AI. Different data classes need different triggers for deletion. In-call audio, transcripts, audio archives, metadata, and pseudonymized analytics each come with their own lawful basis and their own deletion trigger.
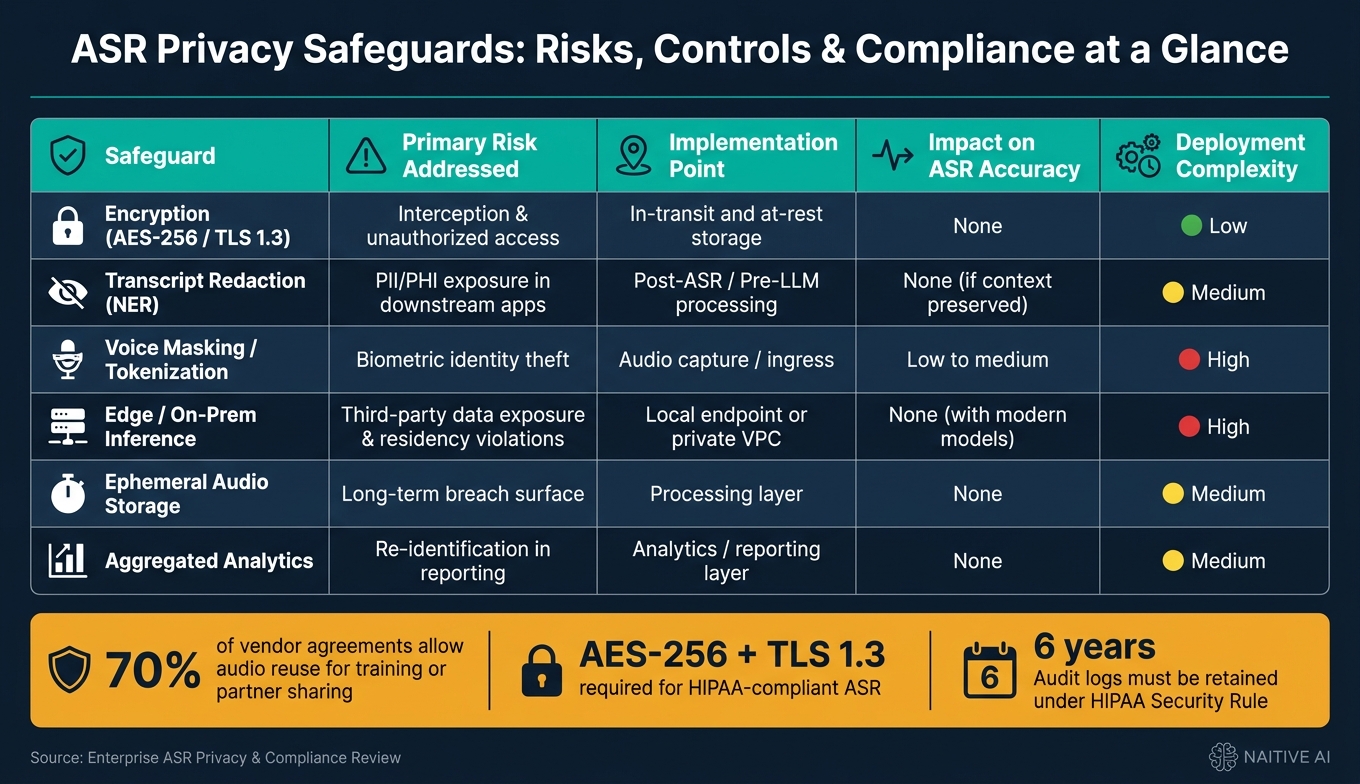
Comparison Table: Which Safeguards Address Which ASR Privacy Risks
| Safeguard | Primary Risk Addressed | Typical Implementation Point | Impact on ASR Accuracy | Deployment Complexity |
|---|---|---|---|---|
| Encryption (AES-256 / TLS 1.3) | Interception & unauthorized access | In-transit and at-rest storage | None | Low |
| Transcript Redaction (NER) | PII/PHI exposure in downstream apps | Post-ASR / Pre-LLM processing | None (if context preserved) | Medium |
| Voice Masking / Tokenization | Biometric identity theft | Audio capture / ingress | Low to medium | High |
| Edge / On-Prem Inference | Third-party data exposure & residency violations | Local endpoint or private VPC | None (with modern models) | High |
| Ephemeral Audio Storage | Long-term breach surface | Processing layer | None | Medium |
| Aggregated Analytics | Re-identification in reporting | Analytics / reporting layer | None | Medium |
These controls work best when privacy reviews are part of consent handling, training workflows, and model updates.
Privacy by Design for Custom ASR Programs
How to Embed Privacy From Consent Through Model Lifecycle Reviews
Once legal duties are clear, the next job is putting privacy into day-to-day work across consent, retention, and model updates. That means building it into the process from discovery all the way through model changes.
Start in the discovery phase with a mandatory Data Protection Impact Assessment (DPIA) before launch. A DPIA pushes the team to classify data the right way, map which rules apply, and document the lawful basis for processing early. If the system identifies or verifies speakers, treat voice features as biometric data under GDPR Article 9. In that case, explicit consent is required, not a standard lawful basis.
Consent design also needs care. For voice AI, consent should be collected at the point of interaction, like a clear IVR prompt at the start of the call, and recorded with timestamps and metadata in an auditable log. For customer recordings, default to no training reuse unless there is a separate opt-in. If recordings move into model fine-tuning without a separate, documented opt-in, PII or PHI can make its way into training data and even into model behavior.
Consent controls aren't a one-and-done step. Model updates can change how data gets reused, and that shifts the privacy picture too. As models change and workflows shift, a scheduled privacy review cycle helps keep the program in line. Delete raw audio within 30 days. Retain redacted summaries for 6 years.
How NAITIVE AI Consulting Agency Supports Enterprise ASR Governance
NAITIVE AI Consulting Agency helps enterprises build ASR governance into consent flows, retention rules, and vendor controls. That includes support for consent design, vendor review, retention policy, and audit readiness across the full system lifecycle.
Key Controls Leaders Should Put in Place First
When leaders need a short list of what to roll out first, these are the controls that matter most.
| Decision | What to Decide | Regulatory Driver |
|---|---|---|
| Consent | Opt-in at start of call, documented with timestamps | GDPR Art. 9 / state biometric laws |
| Training data reuse | Disabled by default for customer recordings | GDPR Art. 6 / 9 |
| Biometric features | Disable voice fingerprinting unless explicitly needed | GDPR Art. 9 / BIPA |
| Sub-processor coverage | BAA or DPA for every vendor touching voice data | HIPAA / GDPR Art. 28 |
| Deletion workflows | Automated, propagating across all data layers | GDPR Art. 17 / CCPA |
The programs that stand up best under regulatory scrutiny are the ones that treated privacy as a design constraint from day one, not as a compliance step added right before go-live.
FAQs
What data in an ASR system is considered sensitive?
In an ASR system, sensitive data includes both raw audio recordings and transcripts. Under GDPR, voice data is treated as high-risk personal information because it can identify a person or be used to build biometric voiceprints.
In healthcare, that same data may also count as PHI. That can include patient names, symptoms, appointment details, and other clinical information. Transcripts matter just as much. If they include personal details like email addresses, phone numbers, or locations, they’re sensitive too.
When does custom ASR require HIPAA, GDPR, or biometric consent compliance?
Compliance depends on what data you process and where the people involved are located.
HIPAA comes into play when audio includes PHI, such as clinical details, patient names, or medical reasons for calls. If a vendor handles that data, you need a BAA in place.
GDPR applies to voice data from European users. And if you collect voiceprints for identification, biometric consent is required under laws such as Illinois BIPA.
How can we fully delete voice data across transcripts, logs, backups, and vendors?
Use automated retention policies across every layer of your architecture. Transcripts, raw audio, prompt logs, and CRM records all stick around on different timelines, so each one needs its own retention rule.
Vendors and sub-processors should also delete or return data when a contract ends. On top of that, audit compliance on a regular basis, automate deletion for recordings you no longer need, and use ephemeral processing when you can.
It also helps to keep documented deletion procedures and records of user requests. That way, if someone asks what was deleted, when, and why, you’re not scrambling to piece it together later.



