Cross-Domain Adaptation vs. Domain-Specific Agents
Pick cross-domain for speed and reuse; pick domain-specific for control, accuracy, and compliance—use hybrids when both matter.

If you need speed and reuse, go cross-domain. If you need tight accuracy, audit trails, and rule control, go domain-specific. That’s the core choice.
I’d boil the article down like this:
- Cross-domain adaptation fits when teams share similar work, data is thin, and processes change often.
- Domain-specific agents fit when mistakes cost money, trigger compliance trouble, or break fixed workflows.
- A hybrid setup often works best: one router, several specialist agents, and RAG for fast-changing facts.
A few numbers stand out right away:
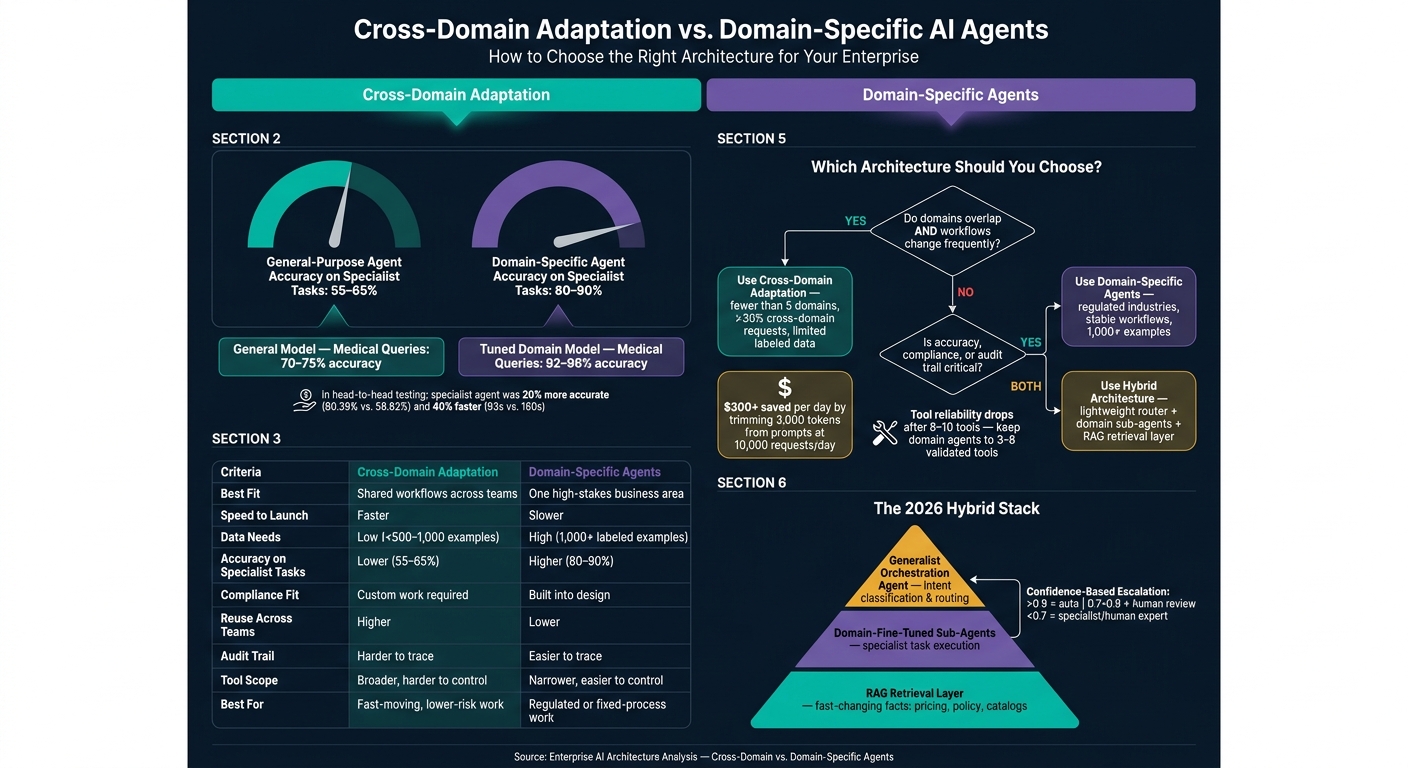
- 55%–65% first-draft accuracy for general-purpose agents on specialist work
- 80%–90% for domain-specific agents on that same type of work
- 92%–96% accuracy for tuned medical models vs. 70%–75% for general models
- $300+ per day in savings at 10,000 requests/day by cutting 3,000 tokens from prompts
- Tool reliability often drops after 8–10 tools
- At 50,000+ daily requests, specialist agents can win on cost per task
What I think matters most is simple: this is not just a model choice. It’s a build, risk, and ownership choice. You’re deciding:
- how much knowledge lives in the model
- how much comes from retrieval at runtime
- who owns monitoring
- how human review works
- how much compliance work your team must add later
Cross-Domain vs. Domain-Specific AI Agents: Key Metrics & Decision Guide
Battle of AI agents: Learn Why Domain-specific AI Agents Win!
sbb-itb-f123e37
Quick Comparison
| Criteria | Cross-Domain Adaptation | Domain-Specific Agents |
|---|---|---|
| Best fit | Shared workflows across teams | One high-stakes business area |
| Speed to launch | Faster | Slower |
| Data needs | Lower | Higher |
| Accuracy on specialist tasks | Lower | Higher |
| Compliance fit | More custom work needed | Built into design |
| Reuse across teams | Higher | Lower |
| Tool scope | Broader, but harder to control | Narrower, easier to control |
| Audit trail | Harder to trace | Easier to trace |
| Best for | Fast-moving, lower-risk work | Regulated or fixed-process work |
If I were making the call, I’d use this rule: pick cross-domain for overlap and change, pick domain-specific for control and precision, and use hybrid when both matter.
Cross-Domain Adaptation: Benefits, Limits, and Operating Requirements
Where Cross-Domain Adaptation Creates Value
Cross-domain adaptation tends to work best in nearby workflows, where reuse matters more than deep domain tuning. The big win is simple: teams can reuse what already works instead of building each agent from scratch.
The numbers back that up. With Parameter-Efficient Fine-Tuning (PEFT) methods like LoRA, teams can tune an agent with as few as 1,000 high-quality examples and often recover costs within 1–3 months at moderate volumes. At higher scale, trimming 3,000 tokens from a system prompt can save $300+ per day at 10,000 requests per day, while also cutting latency.
| Benefit | Description | Enterprise Impact |
|---|---|---|
| Faster Rollout | Reuses base model reasoning and shared schemas across departments | Cuts time-to-market for new automation workflows by avoiding ground-up builds |
| Lower Data Costs | Uses PEFT (LoRA) to tune agents with as few as 1,000 labeled examples | Makes automation possible in niche business units where labeled data is limited |
| Operational Efficiency | Shrinks system prompt length by baking in domain patterns | Major daily cost savings and lower latency at high request volumes |
| Consistency | Reaches 98–99.5% consistency on structured outputs versus 85–95% for prompt engineering | Reduces pipeline failures and manual review in high-volume workflows |
A good example is moving an internal support agent from billing to collections. Instead of a rollout that drags on for months, teams can often get there in weeks.
Where Cross-Domain Adaptation Breaks Down
This is where things can go sideways fast. And the damage isn't limited to model quality. It can hit operations, compliance, and customer-facing work.
The most common issue is source-domain knowledge hurting target-domain performance. When labeling logic or feature distributions don't match, the agent keeps making the same mistakes, and those mistakes are hard to fix with prompting alone. That kind of failure can slip past testing and show up only after launch.
Task complexity is another problem. Research shows agents can drop from 70% success on standard benchmarks to only 23% on longer-horizon, real-world tasks. That's a huge gap, and it's the kind of thing a neat pilot can hide.
Compliance adds even more pressure. Cross-domain agents usually do not include built-in controls for rules like HIPAA, SOC 2, or PCI, so the enterprise team has to handle that work itself. And in cross-domain RAG setups, there's another risk: indirect prompt injection. In plain English, harmful instructions buried inside retrieved documents may get treated like system-level commands.
| Failure Type | Description | Enterprise Risk |
|---|---|---|
| Source-Domain Interference | Source domain knowledge conflicts with target domain accuracy | Persistent errors that are difficult to debug via prompting |
| Changing Policies or Conditions Over Time | Agent fails as internal policies or world state changes | Outdated decision-making and compliance violations |
| Too Much Autonomous Permission Across Domains | Broad permissions without granular controls | Unauthorized data modification or runaway autonomous actions |
That's why monitoring, schema alignment, and access control aren't nice-to-have items. They're table stakes.
What Teams Need Before Using Cross-Domain Adaptation
Before rollout, teams need controls that keep adaptation steady as data, policies, and workflows shift. That usually means solid MLOps for drift monitoring, shared schemas or aligned ontologies, and clear interface contracts so one part of the system doesn't quietly break another.
Evaluation planning matters just as much, and it's often the part teams skip. A smart move is to build a "transfer matrix" that measures the gap between the training domain and each target domain, instead of looking only at top-line accuracy. Teams should also test for instruction shifts like paraphrasing, API changes, and stale information as a normal part of validation, not as an afterthought.
NAITIVE AI Consulting Agency can assess integration readiness and drift-monitoring needs before deployment.
Domain-Specific Agents: Benefits, Limits, and Build Requirements
If cross-domain adaptation wins on reuse, domain-specific agents win on control. They bake rules, vocabulary, and tool access straight into the system design.
Where Specialization Outperforms Adaptation
The gap between general agents and specialist agents isn't small. In medical query benchmarks, out-of-the-box generalist models hit 70–75% accuracy, while properly fine-tuned domain-specific models reach 92–96%. In a head-to-head stress test, a specialized agent was 20% more accurate (80.39% vs. 58.82%) and 40% faster (93 seconds vs. 160 seconds) than a generalist agent.
This gap becomes most obvious in regulated work. In healthcare administration, a domain-specific agent needs to recognize domain language, apply business rules, and flag invalid actions before they ever reach a human reviewer. A general model can sound convincing and still produce output that fails in actual operations.
That’s why these settings need prebuilt guardrails at the tool layer. Invalid actions should be blocked before a reasoning miss turns into a real consequence.
| Aspect | Domain-Specific Agent Characteristics | Operational Implication |
|---|---|---|
| Rule Enforcement | Bound to actual policies, business rules, and compliance thresholds | Prevents outputs that violate regional or company policy |
| Verified Source Data | Trusted access to internal records and domain-specific vocabulary | Eliminates hallucinations by anchoring responses in verifiable source material |
| Process Awareness | Understands approval gates, handoffs, and exception paths | Reduces silent failures where agents miss non-standard process steps |
| Auditability | Domain-specific decision traceability tied to source rules and records | Provides the decision lineage required by auditors and regulators |
| Tool Access | Controlled, sandboxed, and pre-validated function calls | Ensures agent autonomy does not trigger irreversible or catastrophic actions |
The Trade-Offs of Building for One Domain
That extra precision comes at a cost. Specialization improves safety and accuracy, but it gives up reuse. A claims-adjudication agent won’t help much with a marketing campaign. In high-stakes settings, that narrow scope is often the point. Still, it adds maintenance overhead over time.
Building a domain-specific agent also takes serious upfront knowledge engineering. Teams need to map actual workflows, curate domain data, and bring subject-matter experts into the build process as co-designers of tool logic, not just people who hand over requirements. If each business unit builds its own specialist agent without a shared orchestration layer, things can get messy fast. You end up with siloed agents that can’t pass context cleanly between each other.
What Domain-Specific Projects Require to Succeed
Domain rules need to be part of the architecture from day one. That includes process maps that show how work actually happens, with manual overrides and exception paths included, not just the SOP. It also includes curated data like SOPs, fee schedules, case law, or operational records, plus at least 1,000+ high-quality labeled examples if fine-tuning is on the roadmap.
System integration access is non-negotiable. Domain-specific agents get their value from deep ties to systems of record like EHRs, ERPs, MLS feeds, and other production systems. Tool access should stay tight: 3–8 validated tools is a good range. That limit helps reduce risk, and tool-selection reliability drops off once an agent has more than 8–10 tools available.
It also helps to define KPI-based test cases before any build work starts. A solid starting point is 50–100 domain-specific test cases with expert-created ground-truth answers, prepared before architecture choices are locked in. For teams that need help turning domain requirements into agent design and governance controls, NAITIVE AI Consulting Agency can support the process.
How to Choose: A Decision Framework for Enterprise AI
Once your build requirements are clear, the next step is figuring out which architecture fits how the business actually runs, often with the help of AI consulting. This is a deployment choice, not just a matter of picking the model you like more. The decision usually comes down to five things: data, regulatory risk, domain count, workflow stability, and tool complexity.
Decision Criteria That Matter Most
A good starting point is cross-domain adaptation when fewer than five domains overlap and more than 30% of requests cut across those domains. But as domain count grows, compliance gets tighter, or tool dependencies pile up, specialization starts paying off fast.
Here’s a simple way to look at it:
| Decision Criteria | Cross-Domain Adaptation Preferred | Domain-Specific Agents Preferred |
|---|---|---|
| Data Constraints | Fewer than 500–1,000 quality examples | 1,000+ high-quality labeled examples |
| Regulatory Pressure | Low; standard privacy controls | High; regulated controls required |
| Number of Domains | Fewer than 5 distinct domains | 5 or more distinct domains |
| Change Frequency | High; weekly workflow changes | Low; stable workflows and terminology |
| Tooling Complexity | Under ~15 total tools across all domains | 10+ tools required per domain |
Two other factors carry a lot of weight in enterprise settings.
At volumes above 50,000 daily requests, specialist agents often come out ahead on cost because they’re cheaper per interaction. And when outputs need to follow a fixed schema closely, a generalist can become a problem. Its flexible output style, which sounds nice on paper, turns into a downside when the format has to be tight and repeatable.
In practice, these signals often lead teams toward a layered setup.
Hybrid Architectures: Shared Base Agent Plus Domain Layers
When one architecture doesn’t win across every factor, a shared base with domain layers is usually the most workable middle ground. For most enterprises, that means a hybrid stack.
The pattern gaining traction in 2026 is a three-layer setup: a lightweight generalist orchestration agent handles intent classification and routing, domain-fine-tuned sub-agents do the actual task work, and a RAG retrieval layer feeds in fast-changing facts like pricing, policy updates, or product catalogs.
The routing layer also doesn’t have to be expensive. A smaller router can keep token costs down while still protecting accuracy where it counts. Then each specialist sub-agent works with a narrow tool set, which helps avoid tool overload. That matters because accuracy tends to drop once an agent has to manage more than 8–10 tools.
The day-to-day upside is pretty clear: each domain layer can change on its own. If billing logic changes, you update the billing sub-agent and leave the rest alone. That lowers regression risk, since a change in one area is less likely to break another.
Governance, Human Oversight, and Conclusion
Monitoring and Human-Agent Interaction
Once you’ve picked the architecture, governance decides how safely that system works in production. And that choice shapes ownership too: who watches performance, who handles escalation, and who keeps the audit trail clean.
Cross-domain agents need centralized monitoring across prompts, retrieval, and outputs. The hard part is traceability. Teams have to know where each output got its knowledge from, especially when that answer may draw from the base model, an adapter, or a retrieval layer.
Domain-specific agents change that setup. Oversight sits with each domain team, and each team is responsible for its own specialist agent. The test surface is narrower, so validation tends to move faster and staff training is easier to plan. Frontline teams can work from stable playbooks instead of trying to decode a generalist agent’s broader reasoning paths.
Those same trade-offs show up in daily oversight.
| Governance Aspect | Cross-Domain Adaptation Focus | Domain-Specific Agent Focus |
|---|---|---|
| Auditability | Hard to trace whether output came from the base model, adapter, or retrieval layer | High; versioned adapters and fingerprints identify the exact knowledge state behind each output |
| Compliance | Enforced through runtime policy checks | Baked in by design; encodes HIPAA, FINRA, SOC 2 natively |
| Retraining Risk | High; changes in one domain can affect others | Low; modular updates allow independent iteration without side effects |
| Staff Workflow | Broad task assistance; requires high oversight for reasoning errors | Expert-level judgment and exception handling with stable playbooks |
| Escalation Path | Often binary: AI handles it or a human does | Multi-tiered: router, then specialist, then human |
One rule works well no matter which architecture you use: a confidence-based escalation threshold. Outputs above 0.9 confidence run automatically. Outputs between 0.7 and 0.9 go to human review. Anything below 0.7 gets routed to a specialist or human expert. That way, staff spend time on decisions that need judgment instead of checking every single output.
Key Takeaways for Business and Technical Leaders
The main difference here isn’t just model quality. It’s how much control each operating model gives the business.
Choose cross-domain adaptation when domains overlap, labeled data is limited, and workflows shift often. It’s faster to deploy and easier to update, but you give up some auditability and compliance precision in exchange.
Choose domain-specific agents when accuracy, regulatory compliance, or output consistency can’t slip. Specialist agents are easier to control, audit, and regulate in high-stakes settings.
Use a hybrid model when you need both central routing and domain-level control.
FAQs
How do I choose between cross-domain and domain-specific agents?
Choose based on your use case, scale, and level of complexity. Domain-specific agents usually work better for complex, high-volume, rule-heavy tasks spread across several distinct domains where accuracy matters most.
A cross-domain agent may be a better fit if you have fewer than five domains, frequent cross-domain interactions, or limited resources. A smart way to handle this is to track performance over time and add specialized agents where accuracy starts to slip or deeper domain knowledge is needed.
When does a hybrid agent setup make the most sense?
A hybrid agent setup makes the most sense when an organization needs both deep domain expertise and cross-system interoperability. That’s often the case in complex environments or situations that change often.
It tends to work best when a few high-value workflows call for domain-specific agents, while broader business processes need cross-functional agents that can coordinate across many systems. In plain terms, you get specialist agents where precision matters most, and broader agents where coordination matters more.
That balance can help teams improve performance, meet compliance needs, and keep enough flexibility to adjust as things shift.
What data and governance do I need before deployment?
Before deployment, make sure your AI agent’s knowledge sources - model weights, fine-tune deltas, system prompts, tool catalogs, and retrieved context - are versioned, owned, and maintained.
You also need governance built in from the start. That means audit trails, compliance controls, role-based access, data residency where required, clear responsibility, regular updates, and guardrails such as input/output validation and rate limiting.



