Error Recovery in Multi-Agent Systems: Key Patterns
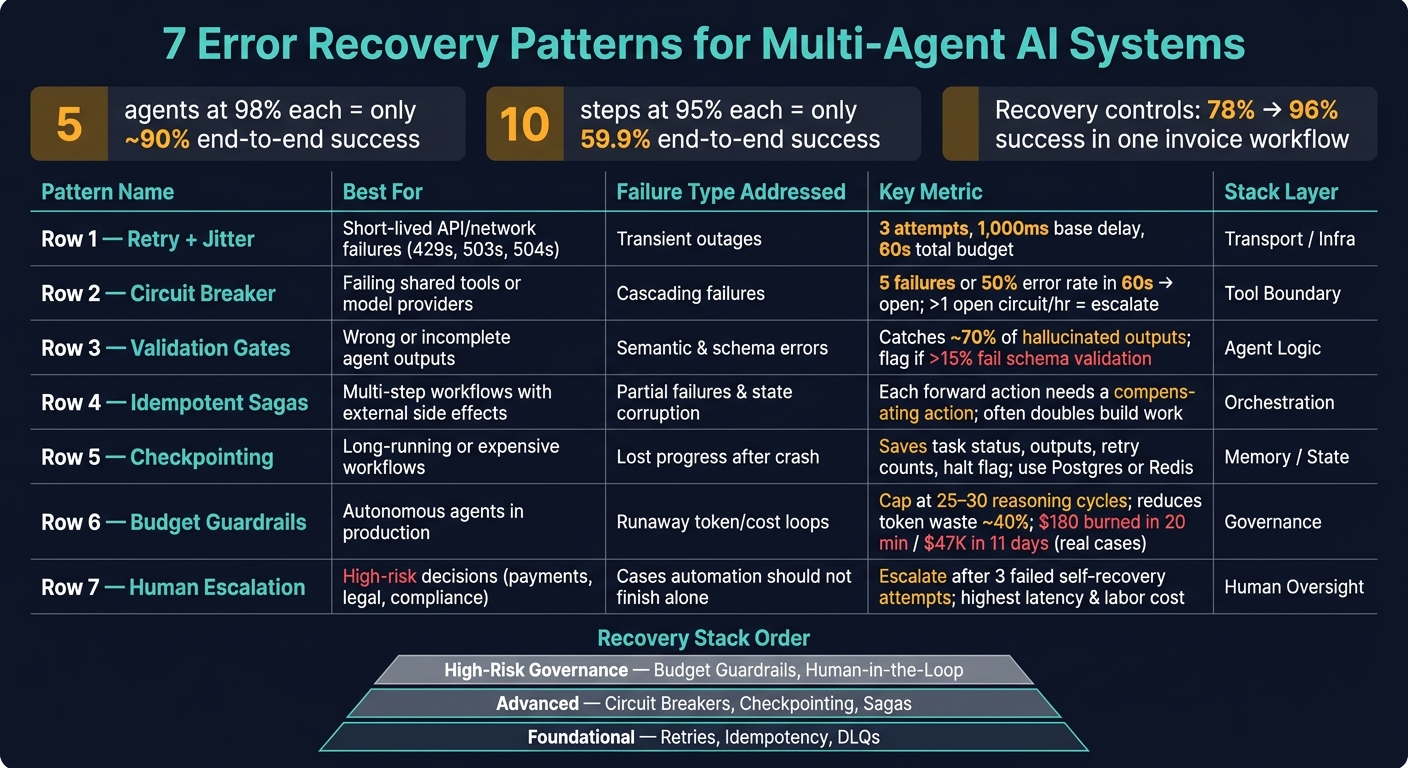
Seven recovery patterns for multi-agent AI workflows: retries, circuit breakers, validation gates, sagas, checkpoints, budget guardrails, and human escalation.

A multi-agent workflow can fail even when each agent looks strong on its own. If five agents each succeed 98% of the time, the full chain still lands at only about 90% success. And in a 10-step flow at 95% per step, end-to-end success drops to 59.9%.
If I had to sum up the article in one line, it would be this: I need different recovery controls for different failure types. Retries help with short outages. Circuit breakers isolate bad dependencies. Validation gates stop bad outputs. Sagas and checkpoints recover partial work. Budget caps stop cost blowups. Human review handles the cases automation should not push through.
Here’s the full set the article covers:
- Retry with backoff and jitter for short-lived API and network failures
- Circuit breakers to cut off failing tools or models before they drag down the rest of the run
- Validation gates to stop wrong or incomplete outputs before they move downstream
- Idempotent sagas to undo side effects after partial failure
- Checkpointing and rollback to resume from the last safe state
- Budget guardrails to stop loops that waste tokens, time, and money
- Human escalation for high-risk or unresolved cases
A few numbers stand out fast:
- A bad loop burned $180 in tokens in 20 minutes
- One system ran up $47,000 in API spend over 11 days
- In one invoice workflow, recovery controls pushed success from 78% to 96%
- More than one open circuit per hour should trigger escalation
- A common retry setup is 3 attempts, 1,000 ms base delay, and a 60-second total retry budget
7 Error Recovery Patterns for Multi-Agent AI Systems
How to Handle Errors in Multi-Agent Systems | AI Engineer Interview
sbb-itb-f123e37
Quick comparison
| Pattern | Best for | Main risk it addresses | Main trade-off |
|---|---|---|---|
| Retry + Jitter | Short outages | 429s, timeouts, 5xx errors | More latency, repeat cost |
| Circuit Breaker | Failing shared tools | Cascading failures | Needs threshold tuning |
| Validation Gates | Wrong outputs | Semantic and schema errors | Extra checks add cost and delay |
| Idempotent Sagas | Partial side effects | Half-completed external actions | More build work |
| Checkpointing | Long workflows | Lost progress after failure | Extra state storage |
| Budget Guardrails | Runaway loops | Token and dollar overrun | Hard caps can stop valid tasks |
| Human Escalation | High-risk decisions | Cases automation should not finish alone | Slowest and most expensive path |
The article’s core point is simple: I should match the control to the failure layer. Use retries for transport issues, gates for output quality, sagas for outside side effects, checkpoints for state, caps for cost, and humans for risk. That is how a multi-agent system stays usable when one step goes wrong.
1. Retry with Exponential Backoff and Jitter
Retry is the first thing to reach for when a failure looks temporary. It fits short-lived problems like network blips, timeouts, rate limits, service outages, or overload.
Exponential backoff means you wait longer after each failed attempt. A simple example looks like this: 1s → 2s → 4s → 8s. That gap gives the downstream service a chance to recover instead of getting hit again right away. Jitter adds a random delay on top, so a bunch of agents don't retry at the exact same second and slam the same service all over again - the classic "thundering herd" problem. In plain terms, retry helps control local execution. It is not a fix for the whole workflow.
Use this pattern in the API client layer for model calls and inside the agent loop for tool-call retries. A common default is 3 attempts with a 1,000 ms base delay for LLM calls. It's also common to cap each wait at 30–60 seconds and keep a 60-second total retry budget per run.
A good rule of thumb:
- Retry transient errors like 429, 503, 504, and 529
- Do not retry 400, 401, 404, or policy refusals
If a retry can trigger side effects, protect the action with an idempotency key or check-before-write logic, such as hash(run_id + step_id), so the same action doesn't happen twice. That's the part people often miss. A retry that writes data twice can turn a small failure into a bigger mess.
The math also gets unforgiving in multi-agent chains. If each agent succeeds 98% of the time, five agents in sequence still give you only about 90% end-to-end reliability without fault tolerance. Retries help soak up transient faults. When failures keep happening, or several parts fail together, you need stronger isolation.
2. Circuit Breakers for Agent and Tool Isolation
Retries help with small hiccups: a brief timeout, a short rate limit, a one-off network miss. But when a dependency is actually down, retries just waste time and rack up cost. According to a Google study, 73% of major production incidents involve cascade failures. In a multi-agent graph, that matters a lot. One slow or broken agent can hold up the rest of the workflow.
A circuit breaker stops that chain reaction. It has three states: Closed (traffic flows as usual), Open (calls fail right away), and Half-Open (a small set of test requests checks whether the service has recovered). When the circuit is open, the system fails fast instead of sitting around for upstream timeouts. That keeps one broken tool from freezing the whole pipeline. Isolation is the first step. After that, you still need to decide whether the output is safe to use.
Use a separate circuit breaker for each dependency: the LLM provider, the vector database, and each tool API. If the search tool goes down, route around it or fall back in a controlled way. A solid starting point is 5 consecutive failures or a 50% error rate within a 60-second window, followed by a 30- to 60-second cooldown before half-open tests.
Circuit breakers should watch more than hard failures. In agentic systems, a dependency can return a success status and still give you output you can't use. That's why modern circuit breakers also catch output-quality failures, including malformed JSON, schema violations, and repeated invalid responses, even when the API returns a 200 OK response. If more than 15% of responses fail schema validation, that's a warning sign worth acting on. The NIST AI Risk Management Framework 2025 update also includes circuit breakers as a core control for agentic systems.
Track open circuits as a primary metric. More than one open circuit per hour should trigger immediate escalation. And every open circuit should have a fallback behind it, such as:
- a cheaper model
- a cached response
- a human handoff
A circuit breaker on its own isn't enough. It needs a fallback path, or you're just failing faster for no reason. Once a dependency is isolated, validation gates decide whether its output can come back into the workflow.
3. Validation Gates and Guardrails for Actions
Circuit breakers tell you when a service is down. Validation gates tell you when the output is wrong. Those are two different problems, and mixing them together usually leads to shaky recovery design. A service can return a success response and still hand back bad output. That’s why this layer matters so much: it sits right between isolation and execution.
The math gets ugly fast in multi-step systems. If each agent in a 10-step sequence has 95% individual reliability, end-to-end success drops to 59.9%. In plain English, one weak step can throw off everything that comes after it. Validation gates stop that bad output at the handoff point before the next agent treats it like fact.
Schema checks catch structural problems such as missing fields, wrong data types, or cut-off responses. The harder problem is semantic failure: output that looks valid but is still wrong. That’s the one that slips through if you only check structure. The goal is simple: stop bad output before it becomes trusted input. For high-stakes outputs, use a separate verifier rather than letting a system check its own work, and use deterministic rules for structured pipelines. In high-volume structured pipelines, rule-based checks are also faster and cheaper.
You should also inspect stop_reason. If an agent stopped because it hit max_tokens instead of end_turn, there’s a good chance the response was truncated. And that matters. A truncated response that passes schema checks is still a failure.
When a gate fires, a log entry isn’t enough. The system should send a typed halt signal to stop downstream execution, and it should save a checkpoint so the workflow can resume from that exact spot. That keeps one failed step from forcing the entire chain to start over.
The right verifier depends on the kind of output and how much risk you can take.
| Verification Approach | Best For | Trade-off |
|---|---|---|
| Schema + deterministic rules | High-volume, structured output | Fast and cheap; misses semantic errors |
| Smaller model verifier | Catching hallucinations without larger-model cost | Lower cost and latency than a larger model |
| LLM-as-judge | Low-volume, high-stakes tasks | High accuracy; adds latency and cost |
| Non-blocking post-execution check | Streaming pipelines | Non-blocking; catches errors before final action |
If an action has already executed, shift to compensating actions and state rollback.
4. Idempotent Sagas and Compensating Actions
Once a bad action has already run, validation gates won't save you. At that point, if a later step fails after earlier steps have committed, you need a saga.
A saga splits a long-running workflow into a series of local transactions. Each forward action gets a compensating action that undoes its business effect. Think refund after charge or archive after create. If step 4 fails, the orchestrator runs compensating actions for steps 3, 2, and 1 in reverse order. That restores consistency instead of leaving a half-done mess in production.
Two rules matter here.
- Register the compensating action before the forward action runs. If the system crashes right after success, the recovery path must already be stored durably.
- Make both forward and compensating actions idempotent. Otherwise, a retry during rollback can charge a customer twice or create the same record again.
Another smart design choice is step order. Put hard-to-reverse actions at the end of the saga, such as sending an email, flipping a production flag, or charging a card. That way, if something breaks early, you only need to undo cheap actions that are easier to reverse.
It also helps to define a pivot point. Before that point, you compensate backward. After that point, you recover forward by retrying only the remaining idempotent steps. It's a simple idea, but it saves a lot of pain when workflows get messy.
Sagas fit multi-agent systems well because ACID rollbacks stop at the edge of your own database. They don't work across third-party APIs like Stripe, Slack, or a CRM. Those systems don't share one transaction boundary, so sagas give you semantic consistency instead of database-level undo. The tradeoff is plain: every forward action needs a matching compensating action, which often doubles implementation work. But it lets you recover from partial failure without leaving outside systems in a broken state. And if compensation still fails after retries, send that failure to a dead-letter queue for human review.
The best compensation plan depends on how reversible the action is.
| Reversibility Class | Definition | Example |
|---|---|---|
| Cleanly Reversible | Fully undone by an inverse action. | Deleting a draft document |
| Compensable with Residue | Cannot be erased; only corrected by a forward fix. | Issuing a refund for a charge |
| Irreversible | Effects cannot be neutralized by any API sequence. | A sent SMS or an email read by a human |
5. Checkpointing and State Rollback
Once validation gates block bad output, the next job is to save the last known-good state.
That’s what checkpointing does. It saves workflow state so the system can restart without going back to square one. Rollback brings the workflow back to the last safe local state, while compensating actions undo side effects in outside systems.
Here’s the catch: in-process agent state doesn’t last. A crash, an OOM kill, or a network split can wipe it out. So if you want recovery that works, you need to persist execution context in durable external storage. That turns recovery into a stateful restart instead of rerunning the whole chain.
The math gets ugly fast. A 10-step sequential pipeline with 95% per-step reliability succeeds only 59.9% of the time, and by 17 steps, failure is more likely than success. Checkpointing cuts that compounding risk by saving:
- task status
- outputs
- retry counts
- the halt flag
With that data stored, a new process can rebuild shared context and continue from the last valid state. The halt flag matters more than it might seem. If you don’t persist it, a resumed agent may keep going after a failed run. Store it in the checkpoint so recovery stops when it should .
Where you keep state matters too. Use ephemeral memory only in development. For durable, auditable workflows, AI automation agencies often recommend Postgres. For high-throughput pipelines, use Redis.
The payoff can be large. In one 4-agent invoice workflow, adding checkpointing and related recovery patterns improved end-to-end success from 78% to 96%.
Checkpoint IDs also make exact replay and branch debugging possible, which helps when you need to inspect a failure state without guessing what happened.
Once state is recoverable, the next control is limiting cost and runaway execution.
6. Budget Guardrails and Resource Quotas
Once state is recoverable, the next risk is cost control. At that point, the job is simple: stop a runaway run before it chews through more budget.
The failure mode is pretty straightforward. An agent gets stuck retrying malformed input and keeps burning tokens without making progress. And this can get expensive FAST. In one production case, a data enrichment agent burned through $180 in tokens in 20 minutes before anyone caught it. In another, a multi-agent system racked up $47,000 in API calls over 11 days because there was no centralized control plane.
Budget guardrails track four things: token usage, reasoning cycle count, elapsed time, and total cost in dollars. Those limits should apply across the full workflow and at the per-agent level, so one bad loop doesn't sink the whole run.
A practical cap is 25–30 reasoning cycles per agent. Most tasks finish in 5–15 steps. So if an agent gets close to its limit, it should return a partial result instead of gambling on one more expensive reasoning step.
That said, caps don't make actions safe by themselves. They stop runaway spending. They do not stop harmful side effects.
This matters even more in multi-agent systems. One looping agent can tie up shared resources and slow down every other agent in the same run. According to a 2025 IDC survey, 92% of organizations using agentic AI said costs came in higher than expected, with runaway loops named as the main cause.
When a cap trips, route the workflow to human review.
7. Human Escalation and Human-in-the-Loop Checkpoints
When retries, validation, and budget caps don’t fix the problem, the system should stop and hand the task to a person. At that point, AI automation has done what it can. If it still can’t get back to a correct result, human review is the last guardrail in the stack.
A common setup is to escalate after a configurable number of failed self-recovery attempts. In many cases, that threshold is 3 attempts. HITL review is most useful for semantic failures where the output looks fine on the surface but is factually wrong, silent degradation where bad output keeps moving downstream, and messy edge cases that weren’t in the training data.
In multi-agent systems, escalation should be based on risk level, not agent confidence. If an action touches money, legal compliance, medical diagnosis, or critical customer communications, a human should approve it no matter how sure the agent seems. As Kevin Tan, Cloud Solutions Architect, notes:
"The hardest pattern to get right: when should the agent stop and escalate to a human? ... High-risk actions always require human approval, regardless of confidence."
Once the threshold is reached, the system should package the failure for review and stop the run. Send the halted session to a dead-letter queue with the original input, attempted output, failure reason, and reasoning trace. That keeps the issue contained and gives reviewers what they need without rerunning the workflow.
In multi-agent pipelines, HITL acts as the final hard stop before downstream execution continues. One soft failure can snowball if the workflow keeps going. Routing the task to human review at the orchestration layer lets someone fix the issue and resume from the checkpoint ID instead of restarting the full workflow.
The next section compares how these patterns differ in coverage, cost, and placement in the stack.
Pattern Comparison: Coverage, Architecture, and Trade-offs
These seven patterns work as a set because each one covers a different failure layer. No single pattern is enough on its own. One catches local execution issues. Another helps the workflow recover. Another puts a cap on spend. And when the system still lands in a gray area, human review steps in.
Put simply:
- Execution controls deal with local faults
- Orchestration controls deal with workflow recovery
- Governance controls deal with runaway spend
- Human review deals with leftover risk
Failure Type Coverage by Pattern
The hardest problems are semantic failures and silent degradation. That’s where output looks fine, but quietly damages downstream steps.
| Pattern | Transient Outages | Bad Outputs | Partial Failures | State Corruption | Budget Overruns | Human Judgment Needed |
|---|---|---|---|---|---|---|
| Retry + Jitter | Strong | Weak | Weak | Weak | Weak | Weak |
| Circuit Breaker | Strong | Weak | Moderate | Weak | Moderate | Weak |
| Validation Gates | Weak | Strong | Moderate | Moderate | Weak | Moderate |
| Idempotent Sagas | Moderate | Weak | Strong | Strong | Weak | Weak |
| Checkpointing | Moderate | Weak | Strong | Strong | Weak | Weak |
| Budget Guardrails | Weak | Weak | Weak | Weak | Strong | Weak |
| Human Escalation | Weak | Moderate | Moderate | Moderate | Moderate | Strong |
A few patterns stand out right away. Retry + Jitter and Circuit Breaker are strong for outages, but they won’t tell you if the model returned nonsense. Validation Gates help there, because they inspect the output itself. Idempotent Sagas and Checkpointing are the ones that help most when work fails halfway through or when state gets messed up.
Permanent errors such as 401 Unauthorized require a configuration fix, not runtime recovery.
Where Each Pattern Sits in the Stack
Placement matters more than people think. A pattern can only stop the failures it can actually see.
For example, Retry + Jitter lives at the request level. It can help with network hiccups or temporary service problems, but it never sees what the LLM said. On the other hand, Budget Guardrails sit at the spend and policy layer. They can stop runaway cost, but they don’t touch a single HTTP response.
That mismatch is a common failure point. Teams use the right pattern in the wrong place, then wonder why it didn’t help.
| Pattern | Primary Layer | Secondary Layer |
|---|---|---|
| Retry + Jitter | Transport/Infra | Tool Boundary |
| Circuit Breaker | Tool Boundary | Governance |
| Validation Gates | Agent Logic | Orchestration |
| Idempotent Sagas | Orchestration | Tool Boundary |
| Checkpointing | Memory/State | Orchestration |
| Budget Guardrails | Governance | Orchestration |
| Human Escalation | Human Oversight | Governance |
The main design job here is stopping one agent’s failure from rippling through the whole pipeline. If a pattern sits too far from the failure, it can’t intercept it in time.
A pattern’s value depends on whether it sits close enough to the failure to intercept it.
Latency, Cost, and Complexity Trade-offs
Coverage is only half the story. The next question is simple: what do you pay for that coverage?
Human escalation is the most expensive option by a wide margin. It slows response time and adds labor cost. At the other end, Circuit Breakers and Budget Guardrails are cheap because they fail fast and cut off waste before extra API calls pile up.
The hardest pattern to build is Idempotent Sagas. Why? Because every action that touches outside state needs matching compensation logic. That gets messy fast.
| Pattern | Latency Impact | Operational Cost | Complexity |
|---|---|---|---|
| Retry + Jitter | Moderate | Low | Low |
| Circuit Breaker | Low (fail-fast) | Low | Medium |
| Validation Gates | Medium | Medium (extra LLM call) | Medium |
| Idempotent Sagas | Medium | High (compensations) | High |
| Checkpointing | Low | Low (saves tokens on retry) | Medium |
| Budget Guardrails | Low | Low (prevents runaway spend) | Low |
| Human Escalation | Very High | Very High (labor) | Medium |
There’s a pattern here. Checkpointing, Sagas, and Guardrails become more useful as the number of agents goes up. A one-step system can get by with less. A chained system can’t.
Multi-Agent Value vs. Single-Agent Value
Some patterns become much more important the second you move from one agent to two.
In a single-agent setup, a failed step usually just fails. Annoying, sure, but contained. In a multi-agent pipeline, that same failure can spread. One bad handoff leads to another, and suddenly the whole flow is off the rails.
That’s why Idempotent Sagas and Checkpointing gain so much value in multi-agent systems. They help manage distributed handoffs and partial recovery across agents. Budget Guardrails also matter more in these setups, because nested retries can multiply API cost across the pipeline.
| Pattern | Single-Agent Value | Multi-Agent Added Value |
|---|---|---|
| Retry + Jitter | High | Moderate (thundering herd risk increases) |
| Circuit Breaker | Moderate | High (isolates shared tool failures) |
| Validation Gates | Moderate | High (stops hallucination propagation) |
| Idempotent Sagas | Low | Very High (manages distributed transactions) |
| Checkpointing | Moderate | Very High (enables resumable handoffs) |
| Budget Guardrails | Moderate | Very High (limits cross-agent cost sprawl) |
| Human Escalation | High | High (final arbiter for misalignment) |
The next section breaks these trade-offs down pattern by pattern.
Pros and Cons of Each Pattern
Each pattern deals with a different kind of failure. So the goal isn't to pile on every safeguard. It's to choose the lightest control that stops the problem you actually have.
| Pattern | Main Advantage | Main Limitation | Best-Fit Use Case |
|---|---|---|---|
| Retry + Jitter | Simple to add; handles transient blips like 429s and 5xx errors while reducing synchronized retries. | Adds about 5–60 seconds of latency per retry cycle; uncapped retries can drive token spend up fast. | Network timeouts, rate limit errors, temporary API outages |
| Circuit Breaker | Fails fast, saving resources and preventing cascade failures from spreading. | Threshold tuning is tricky, and a misconfigured breaker can block valid traffic. | Third-party API outages, repeated tool failures across shared services |
| Validation Gates | Catches approximately 70% of hallucinated outputs before they reach a downstream tool. | Adds latency and cost through extra LLM calls, and custom rules are hard to encode. | High-stakes actions, structured data extraction, any step where a bad output causes real damage |
| Idempotent Sagas | Ensures consistency across multi-step tool chains and supports clean rollback through compensating actions. | High implementation complexity, and irreversible actions like charging a card or booking a flight can't always be undone. | Financial transactions, multi-system record updates, any workflow with external side effects |
| Checkpointing | Resumes from the last successful step instead of restarting, saving significant API cost on long runs. | Requires persistent storage like Redis or Postgres and adds state management overhead. | Long-running workflows, expensive reasoning chains, multi-agent handoffs |
| Budget Guardrails | Prevents runaway loops from turning into runaway spend and can reduce token waste by about 40% in complex agent loops. | A hard cap can terminate a complex but valid task if thresholds aren't calibrated well. | Autonomous agents in production, any cost-sensitive deployment |
| Human Escalation | Handles irreversible or low-confidence decisions with human judgment. | Highest latency of all patterns; it also adds real labor cost at scale. | Payments, legal actions, safety policy violations, any task where wrong calls can be irreversible |
A simple way to think about it: sagas undo external side effects, while checkpointing restores internal progress. They solve different problems. If a long workflow touches outside systems, you often need both.
That distinction matters. Recovery in multi-agent systems works best when each control is placed at the failure layer it can intercept: transport, tool, workflow, state, cost, or human review.
Conclusion
You don’t need every control in every system. Start with the failure mode you’re most likely to hit first. That turns recovery into a layering problem, not a one-shot choice.
Foundational controls - baseline distributed-systems controls like retries, idempotency, and dead-letter queues - handle most transient and input errors. Once failures go past local retries, bring in circuit breakers, checkpointing, and compensating actions. For high-risk workflows, especially payments, legal actions, and compliance-heavy tasks, add budget guardrails and human-in-the-loop escalation as the last check before an irreversible decision.
Use the stack in this order: stabilize execution, then recover workflows, then add governance.
| Control Level | Patterns | Best For |
|---|---|---|
| Foundational (Execution) | Retries + Jitter, Idempotency, DLQs | Most production agents; handles common transient and input errors |
| Advanced (Orchestration) | Circuit Breakers, Checkpointing, Sagas | Multi-step workflows, long-running workflows, external side effects |
| High-Risk (Governance) | Budget Guardrails, Human-in-the-Loop | Financial, legal, compliance-heavy, or irreversible actions |
The right stack is layered, risk-based, and matched to the failure mode.
FAQs
Which recovery pattern should I implement first?
Start with Retry with Exponential Backoff. It’s the simplest and most effective starting point for handling short-lived issues like network timeouts and rate limits.
For production multi-agent systems, add idempotency keys for state-changing operations. As the system grows, bring in circuit breakers and fallback chains.
When should a workflow escalate to a human?
A workflow should hand things off to a human after automated recovery steps stop working. That includes retries, model fallbacks, and rule-based recovery.
This matters most when the system produces low-confidence outputs, keeps hitting the same error, or runs into a permanent failure that makes it unsafe to continue. A clear cutoff helps here. For example, escalating after three failed attempts can stop the workflow from pushing out shaky results.
How do checkpoints and sagas work together?
Checkpoints save the workflow’s state after each step. That gives an agent a clear restart point, so after a crash it can pick up from the last successful step instead of starting over from scratch.
If resuming still doesn’t solve the problem, sagas step in. They run compensation actions in reverse order for steps that were already committed. Put together, these two patterns let a workflow either continue from where it left off or roll things back in a safe, controlled way.



