Multi-Modal AI: Visual and Gesture Synergy
Combining visual inputs and gesture recognition to create intuitive, touchless AI for healthcare, AR/VR, and manufacturing.

Multi-modal AI is transforming how humans interact with technology by combining visual inputs (like images) and gesture recognition (like pointing or waving). This approach allows systems to interpret user intent more naturally, similar to human communication. For example, a surgeon can navigate medical scans using gestures in a sterile environment, or a factory worker can point to control machinery without touching anything.
Key insights:
- Visual inputs help identify objects, analyze scenes, and provide context. They're used in tools like medical imaging (91% radiologist agreement) and automated shelf auditing (89% accuracy).
- Gesture inputs enable touchless control, ideal for healthcare or AR/VR, but face challenges like lighting or calibration issues. Gesture accuracy ranges from 85–95% in trained environments.
- Combining both inputs creates intuitive systems, such as AR/VR tools for 3D design or gesture-controlled robotics for precise tasks.
Despite challenges like cost and latency, these systems are already improving productivity across industries, from healthcare to manufacturing. Businesses deploying multi-modal AI report higher efficiency and reduced task times.
1. Visual Inputs in Multi-Modal AI
Core Mechanisms
When it comes to visual processing in multi-modal AI, the system begins by breaking images into smaller patches. Advanced architectures like Vision Transformers (ViT) convert these patches into tokens, which are then mapped into a high-dimensional space. This allows a unified decoder to process both visual and textual data simultaneously. A standout technique here is CLIP (Contrastive Language-Image Pre-training), which aligns visual and textual representations, making it easier for the AI to reason across modes. Grounding further connects raw visual inputs to real-world entities, like product SKUs or specific dates. While these systems have come a long way, they still face some hurdles.
Strengths and Limitations
These models shine in tasks like optical character recognition (OCR), interpreting charts, recognizing user interface elements, and analyzing document layouts. For example, vision models achieve a 94.2% accuracy rate when extracting data from mixed-format PDFs, compared to just 78% with older methods. Similarly, medical imaging AI tools show a 91% agreement with radiologists on routine findings.
However, challenges persist. These systems often struggle with spatial reasoning, such as distinguishing left from right on a small scale, or counting objects in complex scenes. For instance, GPT-4o's accuracy on single-fact QA tasks drops significantly - from 100% with no context to just 27% when dealing with 128K context. Processing high-resolution images is also resource-intensive, requiring over 1,000 tokens per image, making multimodal processing 5–10 times costlier than text-only tasks. Factors like lighting, camera angles, and image quality add further complications. These limitations underscore the need for varied application strategies, often requiring specialized AI consulting to navigate technical hurdles.
Real-World Applications
Despite these challenges, practical applications of visual AI are thriving. Google Lens, for example, supports 1.5 billion users monthly with its visual search capabilities. In the insurance industry, companies use these tools to compare photos of vehicle damage with written policies and repair estimates [9,10]. Retailers rely on automated shelf auditing, achieving 89% accuracy and reducing manual inspection work by 80%. Manufacturing facilities use AI to analyze site inspection videos, identifying safety violations and checking equipment placement.
Logan Kilpatrick, Senior Product Manager at Google DeepMind, highlights the power of visual inputs:
"A picture is worth a thousand words. This matters double in the world of multimodal. If I look at my computer right now and try to describe everything I see, it would take 45 minutes. Or, I could just take a picture."
However, costs remain a factor. For instance, processing a 5-minute video at 1 frame per second costs about $1.15 in image input tokens. That said, API costs for multimodal models are expected to drop by roughly 70% between 2024 and 2026.
Fusion Strategies
To combine visual and textual data effectively, systems employ different fusion methods. Early fusion integrates raw inputs - like images and text - into unified representations right from the start. Late fusion, on the other hand, processes each modality independently before merging their high-level features for a final decision. Attention-based fusion dynamically adjusts the weight given to each modality.
For tasks requiring high visual detail, cross-modal embeddings map both text and images into a shared vector space. Simpler applications can convert images into text descriptions, reducing storage requirements and complexity. Additionally, designing interfaces that progressively reveal what the AI "sees" - starting with quick, low-confidence insights and refining them over time - can help build user trust and improve understanding.
sbb-itb-f123e37
2. Gesture Inputs in Multi-Modal AI
Core Mechanisms
Gesture recognition systems work by capturing movement data through sensors, processing it with encoders, and combining the information using a fusion network. These systems then analyze the context to predict what gesture was intended. Tools like Google's MediaPipe and PoseNet are commonly used to track specific landmarks on the hands and body, relying on classifiers to identify patterns.
What sets advanced systems apart is their ability to analyze gestures over several frames rather than focusing on static poses. For example, actions like pointing involve a sequence of movements that these systems can interpret. To reduce errors, models are trained on "garbage classes" - movements that resemble gestures but aren't intentional. This approach has significantly lowered false positives from 15–20 per hour to just 2–3. Additionally, for interactions to feel smooth and natural, response times need to be under 300 milliseconds.
By building on these core mechanisms, gesture inputs bring unique benefits but also come with certain challenges.
Strengths and Limitations
Gesture data enhances multi-modal AI by adding spatial context, much like visual inputs, but it also introduces its own set of challenges. One major advantage is its touchless nature, making it an ideal solution in settings like healthcare. For instance, surgeons can use gestures to navigate medical images without risking contamination. Gestures also clarify ambiguous speech; for example, when someone says "that one" while pointing, the motion provides the missing context. As Hannah VanderHoeven and Nikhil Krishnaswamy from Colorado State University put it:
"Gesture recognition and other forms of multimodal interpretation serve as a means of giving 'blind' systems 'eyes'".
However, these systems aren't without flaws. Gesture recognition typically achieves 85–95% accuracy on trained datasets, but performance can drop in poorly lit or uncalibrated environments. Privacy concerns also arise when cameras are used for continuous monitoring, and hardware calibration can be tricky. Additionally, while the gesture recognition market is expected to grow at an annual rate of 18.8% through 2030, the lack of standardization remains a hurdle. Users often need to learn specific movements, which may not feel intuitive.
Real-World Applications
When combined with visual processing, gesture recognition enables more immersive and hands-free interactions. In healthcare, for example, surgeons can manipulate virtual tools or images without touching any surfaces. Engineers in AR/VR environments use hand-tracking to interact with machinery or explore 3D models without physical controls. Retail settings are also adopting touchless kiosks as a cleaner alternative to traditional touchscreens. For individuals with physical disabilities, gesture systems provide a more intuitive way to interact with technology. These examples show how gestures can complement visual inputs, adding depth and immediacy to multi-modal systems.
Fusion Strategies
To create seamless, real-time interactions, gesture inputs are often fused with other modalities like voice and vision. Instead of processing inputs one after another, modern systems analyze them simultaneously, allowing for on-the-fly adjustments as gestures unfold. In cases where gesture recognition is uncertain, systems may use cross-modal confirmation. For instance, if a user waves to dismiss an element, the system might ask for confirmation to ensure the action was intentional.
There are two main approaches to integrating gesture data: joint representation, where all inputs are merged into a single unified space, and coordinated representation, where separate modality spaces are aligned. By processing multiple inputs in parallel, these systems create interactions that feel natural and collaborative, rather than rigid or mechanical.
Build Motion Control Interfaces with Multimodal LLMs
Pros and Cons
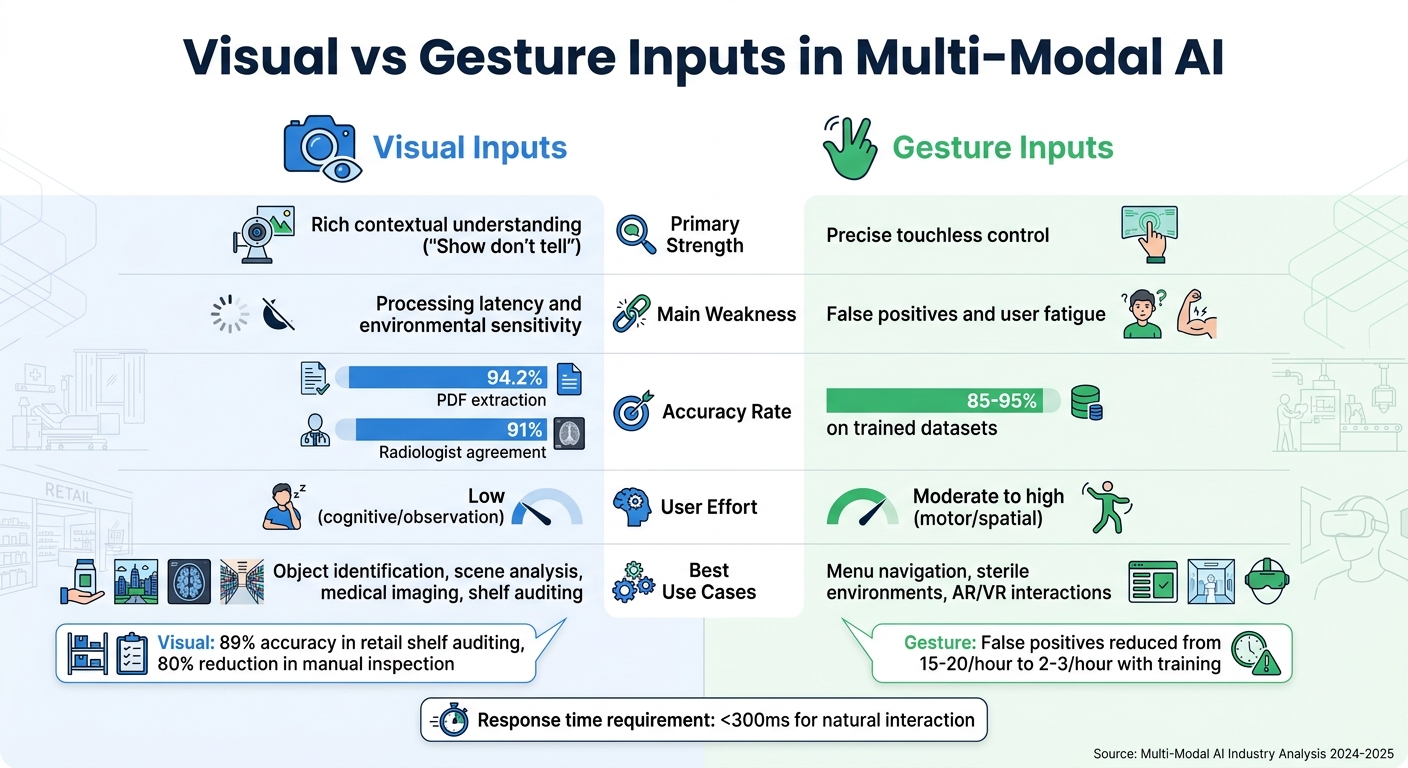
Visual vs Gesture Inputs in Multi-Modal AI: Strengths, Weaknesses and Use Cases
Visual and gesture inputs each bring distinct advantages and challenges to multi-modal AI systems. By understanding these trade-offs, developers can design systems that make the most of each modality's strengths while addressing their limitations.
Visual inputs excel at providing rich contextual information, allowing users to "show instead of tell." This capability is particularly useful for tasks like object identification and scene analysis. However, visual analysis can introduce delays, as it requires substantial computational power. Additionally, performance can be affected by factors like lighting conditions and camera angles.
Gesture inputs, on the other hand, are invaluable in touchless scenarios. They are especially useful in environments like healthcare or industrial settings, where maintaining sterility or working with occupied hands is critical. Gesture inputs offer precise spatial control, but they come with their own hurdles. Unoptimized systems may generate 15–20 false positives per hour due to unintended movements. However, training with "garbage classes" can reduce this to just 2–3 false positives per hour. Other challenges include physical fatigue and the lack of a standardized gesture vocabulary.
Here’s a side-by-side comparison of these modalities:
| Feature | Visual Inputs | Gesture Inputs |
|---|---|---|
| Strength | Rich contextual understanding ("Show don't tell") | Precise touchless control |
| Weakness | Processing latency and environmental sensitivity | False positives and user fatigue |
| Accuracy | High for specialized tasks like diagnostics | 85–95% on trained datasets |
| User Effort | Low (cognitive/observation) | Moderate to high (motor/spatial) |
| Best Use Case | Object identification, scene analysis | Menu navigation, sterile environments |
Practical Applications and Combined Use
The combination of visual and gesture inputs unlocks a range of practical uses across industries, offering a more intuitive way to interact with technology. For instance, in AR/VR spatial design, vision systems detect virtual objects and map room geometry - like walls and floors - while gestures handle tasks such as positioning, scaling, and rotating objects. This approach not only streamlines workflows but also reduces the mental effort involved in 3D design tasks.
In robotics, a study conducted in December 2025 at KTH Royal Institute of Technology showcased the potential of this integration. Using a Meta Quest 3 headset and a Franka robotic arm, researchers implemented an AR "puppeteer" framework. This system displayed the robot's digital twin alongside its real-time state, allowing participants to control the virtual proxy using gestures. Among 42 participants, gesture-only input proved faster for time-sensitive pick-and-place tasks, while adding voice commands introduced more flexibility for less urgent operations. The findings highlight how gesture-based control, especially when paired with visual data, can adapt to a variety of operational needs.
In customer support, combining visual analysis with gesture-based navigation boosts efficiency in resolving issues. For example, analyzing photos of damaged products alongside touchless menu navigation has enabled automated workflows. In optimized setups, automation rates jumped from 68% to 81%, and cross-modal confirmations - like voice prompts for ambiguous gestures - cut recovery steps by 30%.
The healthcare field also benefits from these technologies. Surgeons use gesture controls to navigate imaging data, such as X-rays and MRIs, while visual systems track hand movements with an accuracy rate of 85–95% - ensuring precision during critical moments.
| Application Scenario | Visual Contribution | Gesture Contribution | Performance Improvement |
|---|---|---|---|
| AR/VR Spatial Design | Detects virtual objects and maps room geometry (walls, floors) | Enables object placement, scaling, and rotation | Reduces reliance on manual input |
| Customer Support | Analyzes photos of damaged products | Facilitates touchless menu navigation | Automation rate increased to 81% |
| Field Service | Streams real-time equipment video | Allows pointing gestures despite occupied hands | 30% fewer recovery steps |
Conclusion
Multi-modal AI systems that combine visual and gesture inputs are reshaping the way humans interact with technology. Visual inputs offer critical environmental context and help identify objects, while gestures add precision by conveying intent and spatial details - like pointing to a specific object. Together, these inputs create systems with sharper perception, leading to more natural and effective user experiences.
By leveraging the strengths of both modalities, these integrated systems overcome limitations that single-input systems often face. For example, when a gesture is ambiguous, the system can rely on visual context or even voice feedback to clarify intent, reducing the likelihood of errors cascading through the process. Modern systems employ an orchestration layer to dynamically prioritize inputs, determining whether a gaze, a voice command, or a hand gesture should take precedence in real time. This seamless coordination enhances interactions across diverse fields like healthcare, manufacturing, customer service, and AR/VR technologies.
The growing adoption of these systems reflects their ability to deliver practical benefits across industries. However, implementing them comes with challenges. Bridging the gap between controlled lab environments and real-world deployment, addressing latency issues, and designing workflow-specific solutions require specialized expertise. Tackling these hurdles is key to achieving scalable success.
For organizations ready to explore these technologies, NAITIVE AI Consulting Agency (https://naitive.cloud) offers tailored solutions to ensure smooth integration. Their expertise helps businesses transition from innovative concepts to real-world applications, delivering measurable results that align with unique operational goals.
FAQs
When should a system use vision, gestures, or both?
When designing a system, the choice to use vision, gestures, or both should depend on the context of the interaction. For tasks that involve physical actions, spatial awareness, or nonverbal cues, combining vision and gestures can lead to better accuracy. For instance, identifying gestures like pointing is crucial when handling spatial commands. On the other hand, if the interaction is strictly verbal or visual, relying on a single modality might be enough. Ultimately, the decision hinges on factors such as the user's intent, the environment, and the specific goals of the interaction.
How do teams reduce gesture false positives in real-world settings?
Teams work to reduce gesture false positives by combining advanced algorithms with precise sensors to interpret gestures more reliably. They implement strict input validation, adopt zero-trust principles, and isolate agents to avoid unintentional triggers. Ongoing improvements to gesture recognition technology also help cut down on accidental activations.
What causes multimodal latency and cost, and how can it be minimized?
Multimodal latency and cost arise from the heavy computational requirements of handling diverse data types like text, images, and audio. Each type demands tailored processing, which consumes significant memory and GPU resources. To tackle this, several strategies can be employed:
- Optimizing model architectures: Techniques like quantization and pruning can streamline models, making them more efficient.
- Leveraging specialized hardware: Devices like GPUs and TPUs are designed to handle these tasks more effectively.
- Using edge computing or caching: These methods reduce the need for constant data transmission, improving speed and lowering costs.
By implementing these strategies, multimodal AI systems can maintain real-time performance while keeping expenses under control.



