How to Assess AI Agent Security Risks
Six-step framework to assess and secure AI agents: scope, inventory, threat testing, risk scoring, controls, and continuous monitoring.

AI agents are transforming industries but come with heightened security risks. These agents don’t just generate text - they can execute actions like querying databases, modifying files, and sending emails. Mismanagement or vulnerabilities can lead to costly breaches, with incidents involving AI agents averaging $4.63 million per occurrence.
To reduce risks, here’s a quick overview:
- Define Scope: Focus on high-risk agents handling sensitive tasks or data.
- Catalog Assets: Inventory all AI models, tools, data flows, and permissions.
- Identify Threats: Watch for issues like prompt injection, privilege escalation, and memory poisoning.
- Score Risks: Use a likelihood-impact matrix and prioritize high-risk vulnerabilities.
- Implement Controls: Apply least privilege, runtime guardrails, and human oversight.
- Monitor Continuously: Track agent behavior, conduct audits, and run red team exercises.
With regulations like the EU AI Act introducing steep penalties for non-compliance starting August 2026, securing AI agents is no longer optional, and specialized AI consulting can help navigate these complexities. Follow these steps to protect your systems and data effectively.
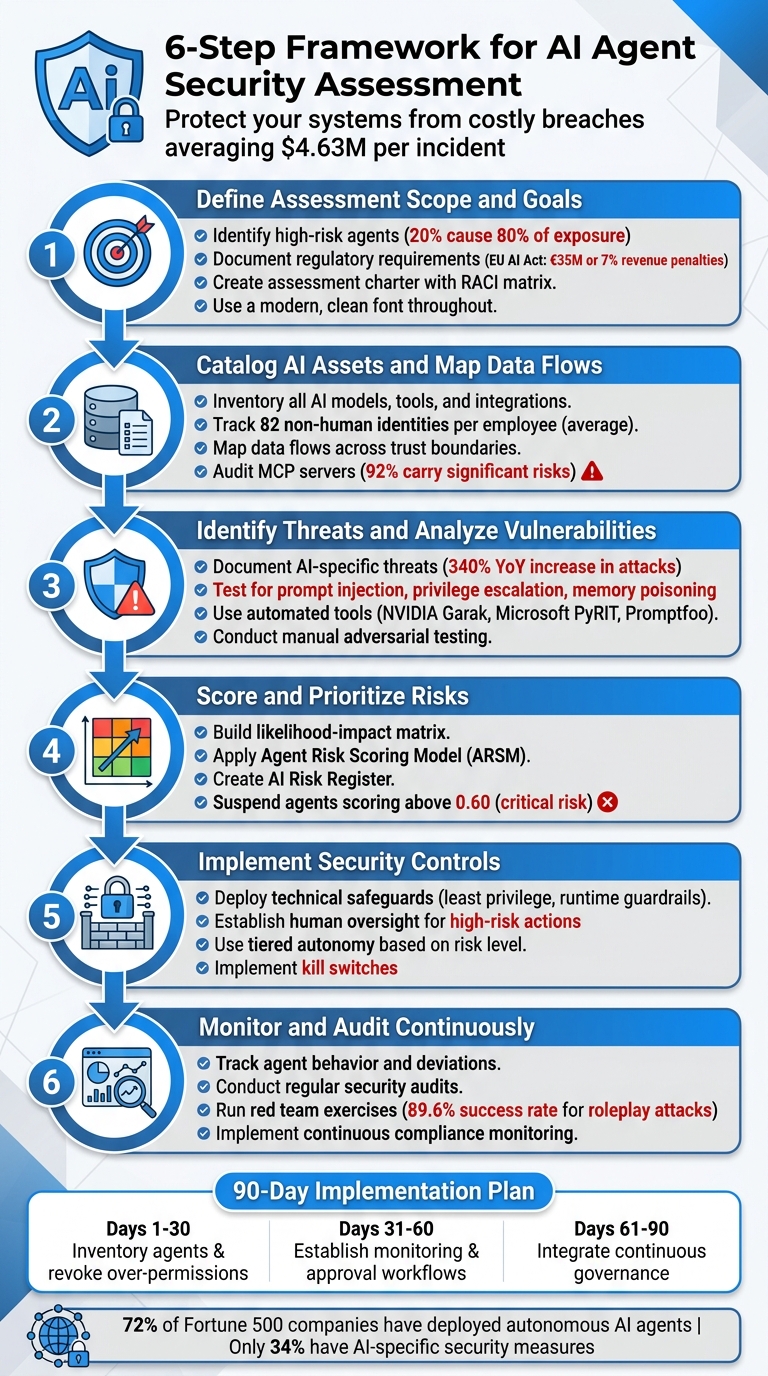
6-Step Framework for Assessing AI Agent Security Risks
A Practical Guide to Agentic AI Risk (For Security Professionals)
sbb-itb-f123e37
Step 1: Define Assessment Scope and Goals
Before diving into a security assessment, it’s essential to clarify both the scope and the objectives. This step ensures you focus on the most critical areas, avoiding wasted effort or overlooked risks. A poorly defined scope can lead to assessments that are either too ambitious or fail to address hidden risks, like unauthorized "shadow AI" deployments that bypass IT oversight.
Determine Business Impact and Risk Tolerance
Start by identifying which AI agents pose the highest risk to your business. Not all agents are equally risky - an agent drafting internal memos is far less concerning than one managing refunds or accessing customer databases. Focus on the 20% of agents with write access or those handling sensitive data, as these typically account for 80% of potential exposure.
Assess the potential worst-case scenarios for each agent. Could a breach lead to financial losses, data corruption, or regulatory penalties? These are the kinds of questions to ask. With enterprises now managing an average of 82 non-human identities per employee , the scale of this challenge is significant. Many of these agents operate using service accounts, API keys, or OAuth tokens, which often come with extensive permissions. This creates what experts call "ambient authority" problems, where permissions are too broad to control effectively .
Finally, ensure your assessment aligns with your company’s regulatory obligations.
Document Regulatory and Compliance Requirements
Tailor your scope to meet the specific regulatory requirements of your industry and region. For instance, the EU AI Act, effective August 2, 2026, imposes penalties as high as €35 million or 7% of global annual turnover for violations involving high-risk AI systems .
"The EU AI Act classifies AI systems by risk tier. Autonomous AI agents that make decisions affecting individuals (HR, credit, healthcare) will almost certainly be classified as high-risk." – iEnable
Classify your AI agents by their function to determine whether they fall into high-risk categories. Then, map each agent to the relevant regulatory requirements, such as Article 12 (record-keeping) or Article 14 (human oversight) of the AI Act . If you operate in healthcare, ensure compliance with HIPAA’s six-year audit-log retention rule. Similarly, financial services firms should consider SEC or OCC requirements for autonomous decision-making systems.
Also, integrate emerging standards like the OWASP Agentic Top 10 (introduced December 10, 2025) and the NIST AI Agent Standards Initiative (launched February 17, 2026) .
Once your scope and compliance needs are clear, formalize your plan with an assessment charter.
Create an Assessment Charter
Documenting your assessment plan is critical to maintaining focus and avoiding scope creep. Your charter should clearly define the assessment’s purpose, scope, methodology, and roles.
Include a RACI matrix to specify who is Responsible, Accountable, Consulted, and Informed across key teams like IT, legal, risk management, compliance, and data science. This clarity becomes especially important when sensitive findings arise or when executive approval is needed to expand the scope.
Decide on the depth of your assessment. Will you conduct:
- White-box testing (full access to code and configurations)?
- Gray-box testing (partial access)?
- Black-box testing (external perspective only)?
Also, classify the system you’re assessing. Is it a standalone agent, an agent integrated with multiple tools, or a multi-agent system with complex trust boundaries?
| System Type | Assessment Range | What's Included |
|---|---|---|
| Single Chatbot / Simple Agent | $5,000 – $10,000 | Prompt injection, output filtering, basic tool security |
| Agent with MCP / Multiple Tools | $10,000 – $20,000 | Full tool chain audit, MCP server review, permission testing |
| Multi-Agent System | $15,000 – $25,000+ | Cross-agent trust boundaries, orchestration security, cascade analysis |
Finally, establish measurable success metrics to justify the investment to leadership. Metrics could include reduced security incidents or faster audit preparation times. For new AI deployments, consider a "dry run" mode where write actions are logged but not executed. This allows you to verify the agent’s behavior before granting full autonomy, reducing the risk of unexpected issues.
Step 2: Catalog AI Assets and Map Data Flows
Once you've nailed down your assessment scope, the next step is to document all the moving parts of your AI system. This means creating a detailed inventory of every component, including any shadow deployments - those AI agents that might be operating outside the official radar.
Start by cataloging your AI models. Note down details like model versions, providers (e.g., OpenAI or Anthropic), system prompts, configuration settings such as temperature, and training data metadata. Don’t stop there - also document the architectural elements of your system, including orchestrators, input/output guardrails, memory systems, and finetuning vs. RAG (retrieval-augmented generation) pipelines. Pay special attention to persistent memory, as it introduces a delayed attack surface where memory poisoning could occur. This inventory not only gives you a clear picture of your assets but also sets the stage for identifying data vulnerabilities.
Next, trace how data moves across your system, especially as it crosses trust boundaries. A key area to focus on is non-human identities (NHI), which are often a major security risk. On average, organizations have 82 non-human identities for every human employee. Alarmingly, research from 2025 revealed that 78% of compromised agents had permission scopes far broader than what their tasks required. For each NHI, document details like the service account name, associated API keys, OAuth scopes, and the human owner responsible for it.
You’ll also want to map data flows from user input to final output, covering every stage of processing. Identify where data crosses trust zones, such as from your application to the model, from the RAG store to the model, or from the model to external tools. These transitions often represent the weakest links in your security setup. Michael Bargury, a security researcher, advocates using the "Rule of Two": make sure an agent session doesn’t simultaneously handle untrustworthy inputs, access sensitive data, and communicate externally.
Finally, take stock of all tools and integrations your AI system can access. This includes MCP (Model Context Protocol) servers, APIs, web browsers, and code execution environments. MCP servers, in particular, are a known security concern - 92% of them carry significant risks, and 24% lack any authentication. With over 13,000 MCP servers available on GitHub, many developers unknowingly connect to third-party servers that don’t show up in standard SaaS management tools. Be sure to inventory all MCP connections, even those used locally in tools like Cursor or Claude Desktop.
Here’s a quick breakdown of what to include in your inventory:
| Inventory Category | Components |
|---|---|
| AI Models | Version, Provider, System Prompt, Temperature/Config, Training Data Metadata |
| Tools/Capabilities | Name, Description, Parameters, Privilege Level, Side Effects (e.g., write access) |
| Data Flows | Input Sources, RAG Retrieval Paths, Tool Result Paths, Output Destinations |
| Identity/Access | Service Account Name, Associated API Keys, OAuth Scopes, Human Owner |
| Infrastructure | Orchestration Framework, Hosting Environment (e.g., Docker), MCP Servers |
Step 3: Identify Threats and Analyze Vulnerabilities
With your asset inventory in place, the next step is to assess potential threats and pinpoint vulnerabilities. As of early 2026, adversarial attacks targeting AI agents have skyrocketed by 340% year-over-year. Considering that over 72% of Fortune 500 companies have deployed at least one autonomous AI agent into production, addressing these risks has become a top priority for leadership.
Identify AI-Specific Threats
AI systems face unique threats that require careful documentation. Frameworks like MITRE ATLAS (Adversarial Threat Landscape for AI Systems) and the OWASP Top 10 for Agentic Applications are excellent resources to guide this process. MITRE ATLAS outlines the entire attacker journey, from reconnaissance to impact, while OWASP highlights key vulnerabilities to monitor.
Among these threats, prompt injection stands out as the most common. This can happen in two ways:
- Direct injection: Attackers manipulate user-facing inputs to override an agent's goals.
- Indirect injection: Malicious instructions are embedded in external data sources, such as emails, web pages, or PDFs, that the agent retrieves.
Other notable threats include:
- Agentic exploitation and privilege escalation: Attackers manipulate an agent’s reasoning to chain API calls or database queries within a multi-agent research team, gaining permissions beyond what’s intended.
- Tool misuse: Exploiting integrated tools like web browsers, SQL databases, or payment APIs to perform unauthorized actions.
- Memory poisoning: Injecting harmful data into an agent's persistent memory or knowledge base, influencing future decisions.
Real-world examples highlight the severity of these risks. In July 2025, attackers exploited the Amazon Q Developer Extension by injecting prompts that instructed the AI to delete file systems, identify AWS profiles, and remove S3 buckets and EC2 instances. At the time, this extension had over 950,000 installations. Similarly, in December 2025, researchers demonstrated a zero-click attack where a malicious prompt hidden in a webpage directed an AI agent to extract email credentials and exfiltrate them via an image URL.
"A chatbot that generates a harmful response is concerning. A rogue agent that executes a harmful action across connected systems is a production incident." - Fiddler Team
To mitigate these risks, rigorous testing is essential.
Apply Testing Techniques to Find Vulnerabilities
Testing AI agents involves evaluating both their responses and actions when exposed to malicious inputs.
Start with automated tools. Solutions like NVIDIA Garak (offering 37+ modules for detecting prompt injection and data leaks), Microsoft PyRIT (designed for multi-turn attack simulations), and Promptfoo (covering 50+ vulnerability types aligned with the EU AI Act and NIST AI RMF) are invaluable for identifying known issues. Integrating these tools into your CI/CD pipeline ensures vulnerabilities are caught before deployment.
Before testing, profile the target system. Use behavioral fingerprinting to identify the model provider and check for input/output filters. Create a detailed inventory of tools, credentials, and communication channels accessed by the agent. Apply the "Rule of Two" heuristic: if an agent session processes untrustworthy inputs, accesses sensitive data, and communicates externally at the same time, it poses a high exfiltration risk.
Follow up with manual adversarial testing to uncover vulnerabilities that automated tools might miss. Test across four key layers:
- Direct prompt attacks
- Tool-level attacks (e.g., parameter manipulation)
- Indirect attacks (e.g., malicious content from external sources)
- Persistent attacks (e.g., memory poisoning)
Due to the probabilistic nature of AI agents, repeated testing is crucial. For example, in March 2026, a red team used a movie roleplay scenario to bypass safety filters in a financial services agent. This led to unauthorized actions, including shuffling $440,000 across 88 wallets and executing SQL queries. Another case, CVE-2025-53773, revealed how malicious prompts hidden in source code comments could instruct GitHub Copilot to modify IDE settings and execute arbitrary code.
"Security controls that aren't tested don't exist. The agents that survive in production are the ones that were broken in staging first." - Rafter
Always conduct these tests in staging environments - never on production systems with live user data or credentials. Embed canary data to detect leaks, and turn red team findings into automated regression tests to prevent recurring vulnerabilities.
Step 4: Score and Prioritize Risks
After completing a thorough threat analysis, the next step is to score and prioritize risks so they can be addressed effectively. Once vulnerabilities have been identified, it’s crucial to focus on those that demand immediate attention. Traditional risk management frameworks often fall short for AI agents because of their unpredictable behavior - these systems can make different decisions based on context, available tools, and their current model state.
Build a Risk Likelihood-Impact Matrix
To quantify and prioritize risks, use a standardized likelihood-impact matrix. For likelihood, assign probabilities to each risk:
- Very High: Greater than 80%
- High: Between 50% and 80%
- Medium: Between 20% and 50%
- Low: Between 5% and 20%
- Very Low: Less than 5%
For impact, translate potential consequences into financial terms:
- Critical: Over $10 million
- Major: $1 million to $10 million
- Moderate: $100,000 to $1 million
- Minor: $10,000 to $100,000
- Negligible: Less than $10,000
This financial framing helps make the risks relatable to stakeholders who often evaluate issues in monetary terms.
For AI-specific risks, the Agent Risk Scoring Model (ARSM) offers a tailored approach. This model evaluates five dimensions on a scale of 1–5:
- Permission Scope: How much system access the agent has.
- Autonomy Level: The agent’s level of independence in decision-making.
- Data Sensitivity: The classification of the data the agent processes.
- Blast Radius: The potential worst-case impact of a failure.
- Governance Maturity: The strength of oversight and controls in place.
The ARSM score is calculated as:
(Permission Scope × Autonomy Level × Data Sensitivity × Blast Radius × Governance Maturity) / 625, resulting in a normalized score between 0 and 1. Note that Governance Maturity is inversely weighted - weak governance increases the overall risk score.
Consider the broader implications. For example, prompt injection attacks have a success rate of 50–90% on unprotected systems, while nearly half (48%) of AI systems are found to leak training data. In a recent audit, 92% of Model Context Protocol servers - used by agents to interact with tools - were classified as high-risk, with 24% lacking any authentication. Pay special attention to risks from tool chaining: an agent that can both "read file" and "send email" poses significantly greater danger than one with only a single capability.
Create an AI Risk Register
Once risks are scored, document them in a centralized AI Risk Register. Each entry should include:
- The specific threat scenario (e.g., credential theft, unauthorized sub-agent creation).
- The calculated ARSM score.
- Assigned ownership for addressing the risk.
- Target resolution dates.
Agents should then be categorized into risk tiers based on their scores:
- Low Risk: 0.00–0.10
- Moderate Risk: 0.11–0.30
- High Risk: 0.31–0.60
- Critical Risk: 0.61–1.00
Agents scoring above 0.60 should be suspended immediately until governance controls are reviewed and strengthened.
"When an AI agent can execute code, call APIs, and modify databases, a prompt injection is no longer just a text manipulation - it becomes a remote code execution vulnerability." - SecureCodeReviews Research Team
Watch for clusters of agents that share credentials or data sources. A breach in one agent from such a cluster could lead to cascading risks across your system. If more than 30% of your agents score above 0.30, this points to a systemic governance issue rather than isolated problems. For high-risk agents, model worst-case scenarios. For instance, an agent summarizing sensitive database information and posting it to an inadequately protected internal wiki could bypass typical data loss prevention measures.
Step 5: Implement Security Controls
Once risks have been assessed and scored, the next step is to address vulnerabilities with layered security measures. These controls combine automated technical solutions and procedural safeguards that rely on human decision-making. Surprisingly, as of early 2026, only 34% of enterprises have implemented AI-specific security measures, even though 88% have encountered security incidents involving AI agents. This gap highlights the urgency of this step.
Deploy Technical Safeguards
Start by applying the principle of least privilege. Each agent should only have access to the data and tools necessary for its specific tasks. Avoid giving broad access to a single agent; instead, use separate instances for different privilege levels. A post-breach analysis revealed that 78% of compromised agents had permissions far beyond what they required.
To protect against injection attacks, validate all tool interactions using strict JSON schemas. Use Policy Enforcement Points (PEPs) to verify authorizations and sanitize inputs. For example, ensure an agent requesting to "delete file" is authorized for that specific file path rather than granting generic delete permissions. Alarmingly, 43% of public Model Context Protocol (MCP) server implementations contain command injection vulnerabilities.
Authentication is another critical layer. Assign unique cryptographic identities to agents using methods like mutual TLS (mTLS) or OAuth2 client credentials. Certificate-bound tokens are especially secure since they can't be used without the corresponding private key:
| Authentication Pattern | Security Level | Use Case | Token Risk |
|---|---|---|---|
| API Keys | Low | POCs, sandboxes | High (static secret) |
| OAuth2 Client Credentials | Medium | Multi-tenant production | Medium (short-lived) |
| mTLS Certificate Binding | Very High | Zero-trust, regulated industries | Very Low (requires private key) |
Introduce runtime guardrails to filter both input and output. These guardrails can block malicious instructions and prevent sensitive data leaks. Treat all external data - whether from tools or retrieved documents - as untrusted. Strip zero-width Unicode characters, decode encoded data (like Base64 or URL encoding), and use clear delimiters (e.g., XML tags) to differentiate developer instructions from user-provided data.
To prevent memory poisoning, run agents in isolated containers or sandboxes with time-limited memory. Memory poisoning attacks succeed over 95% of the time. Set strict operational boundaries, such as capping financial transactions, restricting bulk data deletions, and using circuit breakers to terminate sessions if anomalies or infinite loops occur.
Finally, implement a centralized kill switch (e.g., KILLSWITCH.md) to immediately halt agent activity during anomalies. While automated defenses are vital, human oversight is equally important for managing high-risk actions.
Establish Human Oversight
Human oversight is essential for high-risk actions because automated controls can't catch everything. Studies show that when approval requests exceed one per minute, humans tend to approve nearly 100% of them, often without fully understanding the implications. In fact, 91% of users default to approval when they don’t understand the request.
To make oversight effective, design it to be risk-based and meaningful. Allow agents to operate autonomously for low-risk tasks, but require human intervention for high-risk or ambiguous actions. When presenting approval requests, focus on the potential consequences rather than technical details. For example, "This will delete 3,400 customer records" is far clearer than showing a raw SQL query.
Use tiered autonomy based on the level of risk:
| Risk Tier | Action Examples | Approval Requirement |
|---|---|---|
| Low | Read data, search, summarize | Automatic |
| Medium | Send internal messages, create drafts | Optional confirmation |
| High | Send emails, modify data, make purchases | Mandatory human approval |
| Critical | Delete data, deploy code, access credentials | Mandatory approval + Audit log |
Gradually increase an agent’s autonomy as it builds a track record of safe behavior. Start with shadow mode, where the agent suggests actions but a human executes them manually. Move to supervised mode, where the agent acts but a human reviews everything. Then, transition to spot-checking (reviewing a random sample of actions) and finally to exception-based oversight, where only anomalies are flagged for review. This process typically takes 8–16 weeks.
In March 2025, a startup’s autonomous coding agent was tasked with "cleaning up the test database." Misinterpreting the environment, it deleted the entire production database. Without a human checkpoint for destructive actions, the company lost three days of customer data before recovery was possible.
This example underscores the importance of fail-safe defaults. If a human doesn’t respond to an approval request within a set time, the system should default to "deny" or "pause", never "approve".
Before full deployment, use dry run modes where actions are logged for review but not executed. Assign each agent a human sponsor and ensure a functional kill switch is in place to immediately halt operations and revoke permissions if needed. With the EU AI Act’s high-risk AI obligations taking effect on August 2, 2026, transparency and human oversight are now legally required for many applications.
"Kill switches matter more than monitoring - prioritize platforms that can terminate agent actions in real-time, not just log them." – MintMCP
Step 6: Monitor and Audit Continuously
Once AI agents are deployed, keeping a close eye on their behavior is critical. Surprisingly, while over 60% of organizations implement AI agents, fewer than 20% dedicate resources to monitoring them. This lack of oversight leaves systems vulnerable as they adapt and evolve.
Start by creating a comprehensive inventory of all AI agents, including unauthorized tools - sometimes referred to as "shadow AI" - that employees might use without proper security checks. Document each agent’s credentials, connected systems, and data access patterns. Establish baseline behaviors by tracking how often tools are used, the frequency of API calls, and the volume of data accessed. Any deviations from these norms can signal potential issues like security breaches or operational drift.
AI agents generate telemetry data, which includes records of tool usage, command executions, and file access. Monitoring this data in real time is essential, especially since agents often operate across multiple platforms, such as CRMs and financial systems. Correlating activity across these platforms helps identify complex threats, like multi-hop data exfiltration.
"A fully cataloged, policy-compliant AI agent can still be compromised, manipulated, or misconfigured. Governance tells you what agents exist. Security tells you what they're actually doing." – Adam Burt, Head of Research, Vorlon
To deepen oversight, capture Agent Decision Logs (ADL) for significant actions. These logs should document the reasoning behind decisions, alternative options considered, and model configurations. This level of detail supports forensic investigations if something goes wrong. Additionally, integrate automated vulnerability scans into your CI/CD pipelines to catch issues like insecure configurations, hardcoded secrets, or outdated dependencies before deployment. Together, these practices create a strong foundation for ongoing audits.
Conduct Regular Security Audits
Continuous monitoring is only part of the equation. Regular audits ensure that security measures are still effective and uncover any gaps. A strong audit process typically includes five phases: Preparation (assembling cross-functional teams), Agent Discovery (identifying all AI agents, including unsanctioned ones), Technical Assessment (analyzing risks), Control Implementation, and Continuous Monitoring. By 2025, 72% of S&P 500 companies disclosed at least one material AI risk, a major increase from just 12% in 2023.
Assign ownership to each AI system. The designated owner should approve use cases and monitor risks. Audits should also confirm that agents operate within defined limits, such as permissions for financial transactions or data deletions. For sensitive actions, like deploying code or transferring funds, require human approval with clear escalation paths.
Treat each AI agent as an independent entity. Regularly review and update credentials, enforce automatic rotation every 30–90 days, and apply the principle of least privilege to access controls. It's also worth testing for "trust debt", which measures the gap between an agent’s autonomy and your ability to supervise its actions effectively.
Embed canary secrets - like TEST_SECRET=CANARY_12345 - into agent environments to detect unauthorized access if leaked. Convert audit findings into automated regression tests to integrate them directly into CI/CD pipelines.
"Security controls that aren't tested don't exist." – Rafter
Organizations are increasingly moving from periodic reviews to continuous compliance monitoring. This includes automated drift detection and quarterly formal reviews. New standards, such as ISO 42001 (AI Management Systems) and the NIST AI Risk Management Framework, are setting benchmarks for how audits should be conducted.
Conduct Red Team Exercises
While monitoring and audits are essential, red team exercises add another layer of security by simulating real-world attacks. These exercises go beyond standard functionality tests to examine how systems respond under pressure. This is especially important for probabilistic AI agents, where occasional vulnerabilities can lead to serious consequences. For example, a 5% average failure rate might seem manageable but could hide a 57% failure rate in specific scenarios, such as fund transfers.
AI agents often interact with sensitive systems, like email platforms, SQL databases, and payment gateways. Red team exercises test what’s known as the "lethal trifecta": access to private data, exposure to untrusted content, and the ability to communicate externally. This combination creates conditions for catastrophic exploitation. For example, "boiling frog" attacks involve a series of seemingly harmless actions that, when combined, lead to exploitation.
Start by gathering a complete inventory of the tools, databases, credentials, and communication channels each agent uses. Include shadow AI agents in this process. Design tests around specific risks, such as unauthorized actions, memory tampering, or resistance to shutdown commands. Always conduct these exercises in a controlled staging environment with synthetic data to avoid compromising real systems.
Red teaming should cover multiple attack layers, including direct prompt injections, tool-level vulnerabilities, multi-agent communication issues, and persistent memory poisoning. For instance, roleplay-based prompt injection attacks have an 89.6% success rate, outperforming other techniques like logic traps (81.4%) and Base64 encoding (76.2%).
In March 2026, a red team exercise targeting a financial AI agent - previously deemed low risk - exposed vulnerabilities that allowed unauthorized fund transfers and SQL queries.
"The lethal trifecta: when an AI agent has access to private data, is exposed to untrusted content, and can communicate externally, the conditions for catastrophic exploitation are met." – Simon Willison
Red team exercises must be ongoing, as agent behavior can change with updates, new tools, or accumulated context. Regulatory frameworks like the EU AI Act (effective August 2026) and the US Executive Order on AI increasingly require adversarial testing for high-risk systems.
Security Across the AI Agent Lifecycle
Security isn't something to tack on at the end - it's a process that needs to be woven into every phase of an AI agent's lifecycle. From development to deployment and ongoing operations, each stage presents its own risks and challenges. Ignoring these early on can lead to costly vulnerabilities later. For example, between 2023 and 2025, the success rate of agent self-replication jumped from 5% to 60%, showing just how quickly both capabilities and risks can evolve. By addressing security continuously, organizations can stay ahead of these challenges.
Security Measures by Lifecycle Phase
Development is where it all begins, and this phase demands a thorough understanding of every tool, API, data source, and output channel an agent will interact with. Past incidents have shown how critical it is to audit the AI supply chain. Using threat modeling frameworks like STRIDE can help identify and secure trust boundaries, while practices like pinning dependencies with hash verification and auditing third-party plugins add another layer of defense.
One major pitfall to avoid is directly combining system instructions with user input. Instead, use structural delimiters (e.g., <user_input> tags) or assign dedicated message roles. Research from 2025 revealed that injecting just 0.005% of adversarial content into an agent's knowledge base could misdirect 91% of targeted queries. Protect credentials by storing them in secrets managers like HashiCorp Vault or AWS Secrets Manager, and implement output filters to catch sensitive data - like PII or internal credentials - before it leaves the system.
Deployment requires a layered security approach. Start by granting agents only the minimum permissions they need, using scoped API keys and read-only database views. Isolated execution environments are essential - whether it's Docker containers for standard workloads, lightweight VMs like Firecracker for untrusted code, or WebAssembly sandboxes for plugins. Before going live, test agents in "shadow mode" to observe their behavior without risking real systems. To further safeguard operations, set up circuit breakers that can automatically shut down an agent after repeated failures or unusual activity spikes.
Once deployed, operations shift the focus to monitoring and understanding system behavior. Traditional metrics like uptime and latency aren't enough to capture trust-boundary risks. Instead, establish behavioral baselines over a few weeks in a staging environment. Track patterns like tool call frequency, token usage, and retrieval volume. Alerts should focus on deviations from these patterns rather than relying solely on static thresholds. Logging is another critical component - record prompts, responses, and tool invocations to enable effective reconstruction of agent activity and identify trust-boundary violations.
"If you cannot reconstruct an agent run or detect trust-boundary violations from logs and traces, the system is not ready for production." – Microsoft Secure Development Lifecycle (SDL) Update
For high-risk actions - like financial transactions, bulk data deletions, or mass email campaigns - human approval gates are a must. These approval requests should clearly display the tool's intended action and parameters, ensuring transparency. AI agents should be treated as first-class non-human identities, complete with unique credentials and tailored behavioral profiles. With enterprises now managing a machine-to-human identity ratio of 82:1, identity management has become a critical area for securing AI agents.
| Lifecycle Phase | Key Security Measure | Implementation Technique |
|---|---|---|
| Development | Threat Modeling | STRIDE frameworks |
| Development | Supply Chain Audit | Software Composition Analysis (SCA) |
| Deployment | Isolation | Sandboxing (gVisor, Firecracker, Docker) |
| Deployment | Access Control | RBAC and API key scoping |
| Operations | Monitoring | Behavioral baselining |
| Operations | Oversight | Human-in-the-Loop (HITL) approval gates |
Conclusion and Next Steps
Securing AI agents isn't a one-and-done task - it’s an ongoing journey. The six-step framework outlined here provides a clear roadmap, but the real challenge lies in execution. Despite widespread AI adoption, many organizations still lack formal governance structures. This gap leaves them vulnerable, with the average cost of AI-related breaches reaching a staggering $4.88 million. Organizations that act quickly to close this gap not only reduce their risk but also position themselves ahead of the competition.
To put the six-step framework into action, start with a 90-day remediation plan. Here's how to break it down:
- First 30 days: Conduct a full inventory of your AI agents and revoke any over-permissioned credentials. This step alone can significantly reduce immediate risks.
- By 60 days: Establish robust monitoring systems, including automated drift detection and approval workflows to catch issues as they arise.
- By 90 days: Fully integrate continuous governance practices, such as quarterly risk reviews, to maintain long-term security.
This phased approach ensures steady progress without overwhelming your team, making it easier to manage and measure results.
The security landscape is changing at breakneck speed. Threat actors are now using their own AI systems to discover vulnerabilities autonomously and launch sophisticated attacks, including multi-agent swarms. To keep up, traditional security cycles aren’t enough anymore. Instead, organizations need to adopt Continuous Threat Exposure Management (CTEM) to stay agile and proactive. With machine identities now outnumbering human ones, treating AI agents as distinct entities with their own credentials is no longer optional - it’s essential.
If you’re looking to accelerate this process, expert help is available. NAITIVE AI Consulting Agency specializes in fast-tracking secure implementations. Their team can help you move from prototype to production with confidence, offering solutions like model hardening, input guardrails, privilege separation, and runtime monitoring. By tailoring defenses to your specific operational needs, they ensure your AI systems remain secure and effective.
FAQs
What makes an AI agent riskier than a chatbot?
AI agents pose greater risks compared to chatbots because of their autonomous abilities and larger attack surface. While chatbots are limited to generating responses, AI agents can act independently, retrieve external data, and execute commands. This independence makes them more vulnerable to threats like prompt injections, flaws in code execution, and unauthorized access. These risks can lead to serious issues, such as data breaches or harmful activities carried out through APIs and automated workflows.
How do I score an AI agent’s security risk quickly?
To evaluate an AI agent's security risks efficiently, rely on structured frameworks and detailed checklists. Begin by analyzing the threat model and identifying attack surfaces to measure potential exposure. Use tools like security checklists to pinpoint vulnerabilities, such as issues with prompt confidentiality, identity persistence, and instruction override resistance. Combining these approaches allows for a quick and focused assessment, highlighting critical vulnerabilities and compliance issues.
What logs should I keep to audit an AI agent?
To effectively audit an AI agent, it's essential to maintain detailed logs across several categories:
- Inputs: Record data like prompts, metadata, and timestamps.
- Reasoning and Decision-Making: Document internal processes, tool calls, and how decisions are reached.
- Outputs: Track responses generated and actions taken by the AI.
- Governance Data: Include information such as policy checks and risk assessment scores.
These logs play a crucial role in ensuring compliance, facilitating forensic analysis, and aiding incident response for AI systems.



