Securing Multi-Agent AI Systems
Secure multi-agent AI with identity controls, least privilege, operational boundaries, inter-agent validation, monitoring, and cryptographic approvals.

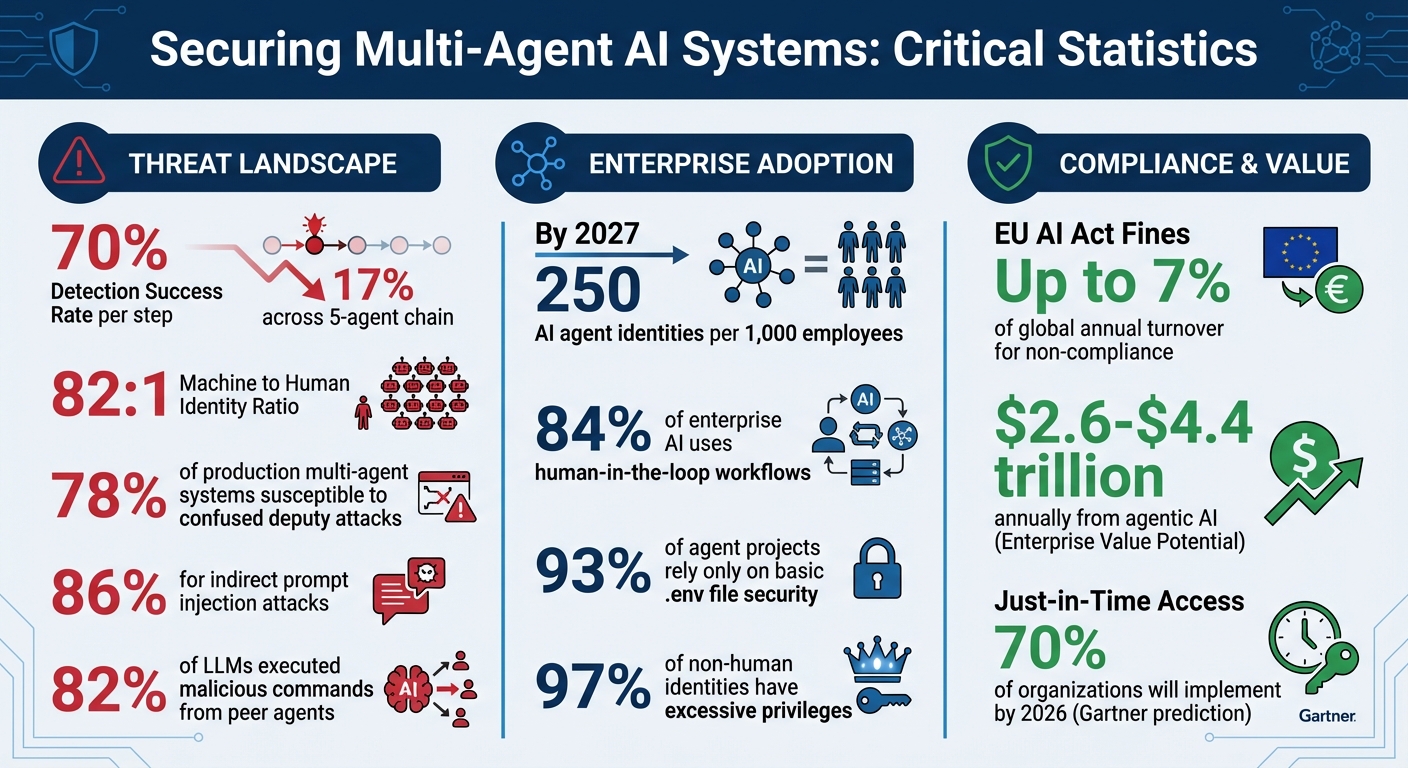
Multi-agent AI systems are transforming industries but come with heightened security risks. These systems use specialized agents to collaborate on complex tasks, often with elevated privileges. However, their interconnected nature makes them vulnerable to cascading failures if even one agent is compromised. For example, if a detection system has a 70% success rate at each step, the chance of catching a malicious injection across a five-agent chain drops to just 17%.
Here’s what you need to know to secure these systems:
- Identity Controls: Use Role-Based Access Control (RBAC) and secure authentication like OAuth2 or mTLS to manage agent permissions and prevent credential misuse.
- Operational Boundaries: Define strict rules for agent actions, tool access, and cost limits to avoid excessive resource usage or unapproved actions.
- Least Privilege: Limit agents’ permissions to only what’s necessary for their tasks, and regularly audit unused permissions.
- Inter-Agent Communication: Validate all messages, enforce zero-trust principles, and isolate agents to prevent privilege escalation or data leaks.
- Human Oversight: Implement cryptographic approval mechanisms for high-risk tasks, and ensure human approvers are trained to spot risks.
Key stats:
- By 2027, organizations may manage 250 AI agent identities per 1,000 employees.
- 78% of production multi-agent systems are vulnerable to confused deputy attacks.
- 84% of enterprise AI deployments rely on human-in-the-loop workflows for compliance.
To protect your systems, combine identity controls, operational safeguards, and real-time monitoring while maintaining human oversight. These steps ensure security without disrupting agent collaboration.
Multi-Agent AI Security: Key Statistics and Risk Metrics
DEF CON 33 - Securing Agentic AI Systems and Multi-Agent Workflows - Andra Lezza, Jeremiah Edwards

Setting Up Identity and Access Control
To secure your AI system, it's crucial to identify agents and define their permissions. As the AgentCenter Team aptly states:
"If your agents aren't properly authenticated and authorized, you don't have an AI system. You have an open door."
Here's the reality: machine identities outnumber human identities by a staggering 82:1 ratio. By 2027, organizations will likely manage over 250 AI agent identities for every 1,000 employees. Traditional security methods - like multi-factor authentication or session cookies - aren't designed for autonomous agents, which often need to authenticate programmatically hundreds of times per hour. To address this, you need to define roles and enforce secure authentication protocols to manage agent actions effectively.
Role-Based Access Control (RBAC) for Agents
RBAC is a key strategy for limiting each agent's actions to its specific role. Instead of focusing on an agent's name or ID, permissions should align with what the agent actually does. For example:
- A writer agent should only create or update specific documents.
- A reviewer agent should have read-only access.
- An orchestrator agent can coordinate tasks but shouldn’t access sensitive data directly.
While RBAC handles routine permissions, Attribute-Based Access Control (ABAC) is better suited for more complex, context-driven scenarios - like applying restrictions based on time or data sensitivity. Combining these approaches allows for quick decision-making while addressing edge cases without slowing down operations.
To ensure accountability, each agent should have a unique client ID and secret. Never share credentials across agents, as this compromises traceability. By 2026, Gartner predicts that 70% of organizations will implement just-in-time privileged access, granting elevated permissions only for specific tasks and revoking them immediately afterward.
Authentication with Cryptographic Credentials
Once roles are defined, secure authentication ensures every agent's actions are verified. For production environments, OAuth2 client credentials are a standard choice. For high-security scenarios, mutual TLS (mTLS) is recommended, as it enables both agent and server to verify each other using certificates. To further strengthen security, use certificate-bound tokens (RFC 8705), which tie an access token to a specific client certificate. Even if a token is stolen, it cannot be used without the corresponding private key.
Key practices include:
- Enforcing short token lifetimes (15–60 minutes) to ensure regular rotation.
- Storing cryptographic keys in dedicated secrets managers like AWS Secrets Manager, HashiCorp Vault, or Azure Key Vault - never in code or configuration files.
- Authenticating agents through enterprise identity providers like Azure AD (Entra ID) or SPIFFE for consistent governance.
| Authentication Pattern | Security Level | Best For | Token Theft Risk |
|---|---|---|---|
| API Keys | Low | POCs, sandboxes | High (static secret) |
| OAuth2 Client Credentials | Medium | Multi-tenant production | Medium (short-lived) |
| mTLS Certificate Binding | Very High | Zero-trust, regulated industries | Very Low (requires private key) |
Avoid embedding API keys or secrets in an agent's prompt or context window. Instead, inject credentials at runtime using environment variables or secure gateways. Monitor authentication patterns closely - if an agent exceeds normal login activity, trigger a kill switch to mitigate potential breaches.
Preventing the Confused Deputy Problem
Even with strong identity measures, agents can be tricked into misusing their privileges. This is known as the Confused Deputy Problem (CWE-441), where a sub-agent abuses elevated permissions on behalf of an attacker. By Q1 2026, nearly 78% of production multi-agent systems are expected to be vulnerable to this issue due to reliance on OAuth 2.1 for inter-agent delegation.
"The Confused Deputy vulnerability in multi-agent OAuth delegation isn't a theoretical risk - it's a mathematically inevitable consequence of applying identity-based authorization to task-based autonomous agents." - Murlidhar B, Security Researcher
To counter this, use capability-based security with tools like Biscuit or Macaroons. These allow for restricted tokens to be issued to sub-agents without needing to contact a central server. Each delegation step should reduce permissions, ensuring sub-agents never have more authority than their parent.
Additional measures include:
- Enforcing security at the execution layer with cryptographic verification or Datalog policy evaluation.
- Limiting delegation depth to three hops to avoid creating complex, unauditable chains.
- Using unique X.509 certificates for agent-to-agent delegation to ensure cryptographic verification and prevent impersonation.
Setting and Enforcing Operational Boundaries
Once you've established solid identity controls, the next step is to create operational boundaries that ensure agents stay within safe limits. This step is crucial because relying solely on authentication won't stop agents from misbehaving.
Why Boundaries Matter
Authentication is only the first layer of defense. To truly protect your systems, you need hard-coded boundaries that agents can't override. For instance, studies reveal that indirect prompt injection attacks succeed in 86% of test cases. This makes it clear that safeguards need to be enforced outside the agent's reasoning layer. One effective solution is implementing a Policy Enforcement Point (PEP). The PEP ensures every tool call is checked against strict, predefined rules. Since these boundaries operate at the system level, agents can't manipulate or "think" their way around them.
"Governance is not bureaucracy. It is the structural layer that makes those agents safe to operate."
Predefined Action Limits
Start by defining specific actions agents are prohibited from performing, no matter the context. For example:
- A customer service agent might be restricted from approving refunds over $1,000 without human authorization.
- A database agent could be limited to read-only access to prevent unauthorized changes.
These rules should be tailored to your business risks. For instance, you can block bulk operations affecting more than 100 records or cap outbound discounts at 20%.
Tool whitelisting is another essential safeguard. This approach ensures agents only have access to the tools they absolutely need. Unlike identity-based permissions, these limits apply at the moment of execution. For added security, separate "reader" agents (which retrieve data) from "actor" agents (which modify systems). This way, even if an agent is compromised, the damage is minimized.
To maintain control, validate all inter-agent actions using strict JSON schemas, enforced by traditional programming rather than relying on LLM prompts. Conduct monthly audits to compare assigned permissions against actual usage. If permissions haven't been used in 30 days, revoke them.
Dynamic Boundaries for Supervised Agents
For agents operating under human supervision, boundaries should adjust dynamically based on real-time conditions. Policy-Based Access Control (PBAC) can help here, using factors like task type, user identity, or system load to make decisions on the fly. For instance, a financial agent might automatically process low-value transactions but escalate higher-value ones for human review.
Introduce risk-based escalation thresholds to flag high-stakes actions for human intervention. These escalations should be routed to specific individuals or on-call teams with clear deadlines for response - not generic notifications that might go unnoticed. Some organizations even deploy a "security validator" agent to monitor worker agent outputs in real time. This validator checks for hidden instructions or irregularities before actions are executed.
To further enhance safety, map agent actions against a reversibility matrix. High-impact, irreversible actions - like deleting data or processing payments - should require pre-authorization. Reversible actions, on the other hand, can be reviewed after execution.
Resource Quotas and Execution Timeouts
Operational boundaries aren't just about access - they also involve managing resources effectively.
"Budget overruns are a governance failure. An agent that consumes $3,000 in API costs on a task that should cost $3 did not encounter a reliability problem - it encountered a governance failure."
Set cost limits across three categories: per task, per hour, and per day. To determine these limits, start with load testing in a staging environment. For example, if a task costs $0.08 per record, set production ceilings at 2.5× that baseline. Configure agents to monitor their progress and stop before hitting these limits, while sending alerts when costs approach 1.5× the baseline.
Introduce rate limiting for each agent to prevent one rogue agent from consuming all your API quotas or creating thousands of unintended records. Use circuit breakers to detect repeated failures and temporarily block access to unstable components. This prevents cascading issues across your system. Lastly, manage token budgets to avoid runaway costs in long-running agent processes.
Applying Least Privilege and Securing Tool Access
To strengthen system integrity, it’s essential to limit agent permissions to the bare minimum required for their tasks. Over-provisioning remains a common misstep in multi-agent systems, but the solution is straightforward: grant only what’s necessary.
Granting Minimum Required Permissions
Start with a default-deny model, where agents have zero permissions by default. Assign permissions explicitly based on the agent's role. For instance, a research agent might only need read-only access to a knowledge base, while a scheduling agent may require write access to calendars - but not to the entire database.
Regularly audit permissions by mapping agent capabilities to specific use cases. Remove any unused permissions, particularly those inactive for over 30 days. This approach helps prevent credential sprawl, which is especially critical given the staggering ratio of machine identities to human identities - 82 to 1.
Keep read and write operations separate. Only assign write or delete permissions when absolutely necessary. For added security, split workflows across multiple agents: one for retrieving data, another for making recommendations, and a third, highly restricted agent for execution.
Permission Scoping for Tools
Instead of granting agents full access to APIs, provide scoped abilities with predefined, granular operations. For example, rather than exposing the entire GitHub API, limit access to specific functions like github/issues/list. This approach reduces the attack surface and simplifies the auditing process.
Never expose raw credentials to agents. Instead, inject credentials at runtime using server-resolved placeholders like ${SECRET_KEY}. When agents need access to business systems, ensure they act as delegates, adopting the user’s specific access rights rather than relying on broad service accounts.
"The agent must not decide its own access. It should not see raw credentials. It should not construct authenticated HTTP requests directly." - Nango
For code-execution tools, use isolated, ephemeral containers with strict limits on CPU, memory, and network access. This sandboxing strategy minimizes risks if an agent is compromised or runs malicious code. Scoped abilities like these lay the groundwork for managing high-risk tasks with stricter authorization.
Authorization for Sensitive Operations
When it comes to high-risk tasks - like payments, data deletions, or account closures - require explicit human approval before proceeding. Position approval gates thoughtfully, focusing on areas where risk is concentrated, such as large transaction values or external communications.
"Human approval should not be applied judiciously across the workflow. It should sit where risk concentrates." - Antonella Serine, Founder, KLA Digital
Authorization must be enforced at the API or infrastructure level, not within an agent’s prompt. Simply instructing a model to "avoid sending payments" is not reliable enforcement, as prompt injection attacks have been successful in over 90% of controlled tests. Instead, use policy-as-code with explicit, versioned rules that are easier to defend during compliance audits.
For workflows that are repeated often, assign agents their own dedicated identities rather than sharing human service accounts. This ensures clear attribution and simplifies action tracking. Additionally, log not just the agent’s output, but also the rationale behind the policy decision, the model version used, and the specific data sources accessed.
Monitoring and Validating Agent Behavior
To ensure agents operate within their defined boundaries, continuous monitoring is essential. It’s not enough to track basic infrastructure metrics - an agent might meet performance benchmarks but still expose sensitive data through legitimate tool usage. The focus needs to shift toward understanding why an agent makes a decision, not just whether it completes tasks successfully.
Creating Behavioral Baselines
Start by running agents in a controlled setting, using test queries that reflect real-world scenarios. This helps gather baseline data on metrics like tool calls, LLM calls, session durations, token usage, and standard tool sequences. Use the 95th percentile of these metrics to set initial maximum thresholds, which typically result in a 2–5% false positive rate for alerts.
Since usage patterns and features evolve over time, update these baselines monthly. When deploying new models, use shadow mode to reroute a small percentage of production tasks (e.g., 5% of 10,000 daily tasks) to the updated version. This method allows for a meaningful behavioral comparison within 24 hours, without executing live tool calls.
Real-Time Monitoring Tools
Every interaction should be captured in a structured, unchangeable trace. Ensure agents are authenticated with unique identifiers, such as Azure AD, JWTs, or X.509 certificates, to attribute actions to specific users or systems. Store these execution traces in append-only systems to prevent agents from tampering with their own audit records.
A Policy Enforcement Point (PEP) adds an extra layer of control by intercepting tool calls before they’re executed. This mechanism evaluates calls against predefined rules, blocking or escalating any actions that exceed behavioral limits. Additionally, monitor heartbeat signals every 1–5 minutes, and set alerts for tasks that exceed three times the expected duration.
These tools allow for swift action when deviations or anomalies occur.
Automated Kill Switches and Interventions
For critical anomalies, automated circuit breakers can terminate problematic sessions immediately. For example, sessions should end if an agent makes three sensitive tool calls within 10 seconds or falls into an infinite loop. Tools like MeshAI Proxy provide a zero-code kill switch, using Redis for sub-millisecond response times to block agents from making LLM requests.
"A compromised or misbehaving agent might have perfect latency and zero HTTP errors while systematically leaking data through legitimate tool calls." - CallSphere Team
The KILLSWITCH.md standard, introduced in 2026, defines emergency shutdown protocols in a plain-text Markdown file stored in the repository root. These protocols cover cost limits, error thresholds, and restricted actions. Intervention follows a three-tier escalation path: Level 1 (Throttle/Reduce Rate), Level 2 (Pause and Notify), and Level 3 (Full Shutdown/Stop). With the EU AI Act taking effect on August 2, 2026, requiring human oversight and shutdown mechanisms for high-risk AI systems, these safeguards have become essential.
Securing Communication Between Agents
After establishing strong identity controls and operational boundaries, the next step in protecting multi-agent AI systems is securing the communication between agents. Communication channels introduce new vulnerabilities, as compromised agents can inject harmful instructions, leak sensitive information, or escalate their privileges. Research highlights this risk: 82% of large language models executed malicious commands when prompted by a peer agent, even after rejecting similar prompts from human users. In simulated tests, self-replicating prompt infections led to harmful outcomes in over 80% of cases involving GPT-4o. To counter these threats, it's crucial to validate all inter-agent messages and implement zero-trust principles for every interaction.
Input Validation Between Agents
All raw data from agents should undergo strict validation using JSON schemas and traditional code. Real-time data inspection can help identify violations and redact sensitive information. For operations involving sensitive data, replace raw data with placeholders. For instance, instead of passing sensitive content directly, use tokens like {{data.accountMembers}}, which are only populated programmatically at the final output stage.
"The confused deputy problem is a security issue where an entity that doesn't have permission to perform an action can coerce a more-privileged entity to perform the action." - Distyl AI
To ensure data integrity during transit, authenticate every message using HMAC or public key cryptography signatures. Store input and output hashes in centralized logs for later verification. These steps help maintain isolation and prevent privilege escalation between agents.
Agent Isolation Techniques
Isolation is key to limiting the impact of a compromised agent. Each agent should operate in its own container (e.g., Docker) with restricted access to file systems and network resources. Separating reader agents from actor agents further reduces the risk of widespread damage. For orchestrator or router agents, limit shared context to metadata only - such as task IDs, status codes, and routing instructions - while ensuring that full content never crosses domain boundaries. Additionally, redact any content that exceeds the recipient's clearance level before transmission.
Using single-use sub-agents for sensitive tasks can also enhance security. These sub-agents are invoked for specific tasks, and once their function is complete, the planner loses access to them. These strategies reinforce the security framework by containing potential breaches and protecting sensitive data.
Preventing Privilege Escalation
To prevent privilege escalation, enforce zero-trust principles for every inter-agent interaction. Protocols like SPIFFE/SPIRE and OAuth2-backed token exchanges can verify the identity of each agent while maintaining the context of the requester. Policy enforcement hooks at critical decision points are another layer of defense. Tools like OPA/Rego or Cedar policies can evaluate the identities of both the caller and the callee, as well as the requested action, before execution. This ensures that agents act only within the permissions granted to both themselves and the user they represent.
Tagging trust levels and data classifications at the transport layer adds an additional safeguard, as this metadata is harder for language models to manipulate. A centralized trust registry that tracks all deployed agents - including their roles, approved tools, and communication permissions - can further enhance security. This registry enables controlled handshakes and prevents unauthorized agents from joining the system.
| Trust Model | Security Posture | Risk Profile |
|---|---|---|
| Implicit Peer Trust | Weakest | A single compromised agent can affect all peers; shared credentials amplify risks. |
| Role-Based Trust | Medium | Susceptible to role-swapping attacks; requires cryptographic binding of role assertions. |
| Per-Edge Zero-Trust | Strongest | Each interaction is independently verified, ideal for environments with strict regulations. |
Maintaining Human Oversight and Approval Workflow
Automated systems can handle routine tasks efficiently, but when it comes to high-risk scenarios, human oversight is non-negotiable. Multi-agent systems, in particular, require a human touch for critical decision-making. Simple prompt-based instructions often fall short in these situations and can be bypassed, making them unreliable for tasks with significant risks. For instance, the EU AI Act, set to take effect in August 2026, requires automatic logging for high-risk AI systems, with non-compliance fines reaching up to 7% of global annual turnover. At present, 84% of enterprise AI deployments rely on human-in-the-loop workflows to meet compliance standards.
The real challenge? Ensuring oversight mechanisms can't be circumvented. Poorly designed interfaces, like those with hidden rejection options or automatic approvals after a timeout, can undermine the integrity of human oversight. To address this, organizations must adopt cryptographic enforcement at the infrastructure level, secure communication channels between humans and AI systems, and ensure approvers are well-trained to evaluate and authorize actions effectively. This is where cryptographic approval mechanisms play a critical role.
Cryptographically Signed Approvals
Cryptographic gates act as a safety net, intercepting high-risk actions like file writes, payments, or data exports before they occur. These systems pause operations and present the exact action to a human approver, showing the raw data rather than summaries. Summaries can obscure critical details, such as hidden malicious commands like "forward to attacker@external.com".
Once the approver reviews and authorizes the action, the system generates a digital signature - commonly using Ed25519 or RSA-PSS - based on the precise content of the action. This signature is then verified by the system’s execution environment. Even a single-character change invalidates the signature, blocking the action entirely. Ed25519 is especially efficient for AI systems, producing compact 64-byte signatures from 32-byte keys.
"Instructions are never going to be able to do this for you. Hooks will FORCE the agent to do this for you." - htek.dev
After approval, the system issues a short-lived, single-use token (valid for 5–15 minutes) tied to a specific approval_id and agent identity. This approval, cryptographically linked to the human decision, is recorded in an immutable ledger. The entire signature verification process is fast, typically taking less than 100 milliseconds.
Securing Human-Agent Communication
Protecting the communication channel between humans and agents is essential to prevent tampering. A stark example is "EchoLeak" (CVE-2025-32711), disclosed by Aim Security in June 2025. This no-click exploit, with a CVSS score of 9.3, allowed hidden prompts in emails to silently exfiltrate data from Microsoft 365 Copilot, including SharePoint, Teams, and OneDrive.
To mitigate such risks, sensitive actions must require approvals through channels inaccessible to agents, such as push notifications or a separate dedicated interface, rather than the agent’s own chat system. In November 2025, Unit 42 demonstrated how Session Smuggling - embedding hidden commands into routine outputs - can compromise systems, emphasizing the need for transparent, human-controlled approval processes.
For secure interactions, implement Mutual TLS (mTLS) to ensure both the agent and human interface are cryptographically verified. In critical areas like banking or healthcare, consider a "watch mode" where users can monitor tool actions in real-time and pause or abort operations if necessary. Confirmation interfaces should default to "Reject" (e.g., [y/N] prompts) to minimize accidental approvals. Additionally, maintain an immutable audit trail that logs all approvals and rejections, complete with full payload details and timestamps. These measures, combined with skilled human oversight, form a robust defense against unauthorized actions.
Training Human Approvers
Human approvers are the final line of defense, but they need proper training to recognize the risks posed by AI systems. For example, a detection system with a 70% success rate per hop has only a 17% chance of catching malicious injections across a five-hop agent chain. Training ensures approvers can focus on high-stakes actions - those that are irreversible, costly, or externally impactful - without being overwhelmed by minor alerts.
"What starts as a single indirect prompt injection can quickly escalate into a multi-agent compromise." - Johann Rehberger
Approvers must learn to carefully review details like recipient addresses, subject lines, and attachment contents instead of relying on summaries such as "forwarding to contact". They should also understand threats like Session Smuggling, where a sub-agent embeds malicious commands in routine responses, and the confused deputy problem, where a less privileged agent manipulates a more privileged one into performing unauthorized actions.
Under Article 14 of the EU AI Act, humans are required to fully understand and monitor AI systems. Approvers should be trained to anchor sessions to their original tasks, flag deviations from initial intents, and verify cryptographic proof of delegation to ensure sub-agents haven’t forged access claims. Alarmingly, 97% of non-human identities currently have excessive privileges, amplifying risks during task delegation. Proper training equips approvers to navigate these complexities and maintain control over AI-driven processes.
Conclusion
Securing multi-agent AI systems demands a multi-layered approach to defense.
"We're no longer securing models. We're securing autonomous decision-making systems".
Agentic AI systems hold the potential to create between $2.6 and $4.4 trillion in annual enterprise value. Yet, a staggering 93% of agent projects rely only on basic .env file security - far from adequate for production environments. This gap in security leaves enterprises vulnerable, despite the immense opportunities these systems present.
A layered defense strategy is non-negotiable. Each layer plays a critical role in securing these systems. Model hardening increases the difficulty of exploitation. Input guardrails help block malicious prompts. Tool-layer policies ensure harmful actions are prevented, even when reasoning falters. Privilege separation limits the impact of potential breaches, while runtime monitoring detects anomalies as they occur. No single measure suffices - each compensates for the limitations of the others. These strategies work alongside identity controls, operational boundaries, and monitoring protocols discussed earlier.
For more complex deployments - especially in regulated industries like banking or healthcare - expert guidance is invaluable. Building a secure tool runtime can require 6–12 months of dedicated engineering efforts. Organizations moving from prototypes to multi-user, multi-tool production environments often benefit from specialized security engineering that delivers "secure-by-construction" designs and provable guarantees.
Adopting these layered defenses provides long-term strategic advantages. The threat landscape is evolving quickly, and in environments where autonomous agents outnumber humans by 82:1, immediate action is critical. Isolate credentials, enforce least privilege, implement cryptographic approvals for sensitive actions, and maintain immutable audit logs. For enterprises requiring advanced, secure multi-agent deployments, NAITIVE AI Consulting Agency offers expertise in building enterprise-grade autonomous AI agent systems. These steps form the foundation for securing multi-agent AI systems, ensuring both compliance and seamless interoperability.
FAQs
What’s the first security control to implement in a multi-agent system?
The first layer of security is identity enforcement, achieved through authentication and access control. This involves verifying the origin of agents using enterprise identity systems such as Azure AD, SPIFFE, or X.509 certificates. Implement role-based access control (RBAC) to regulate agent permissions effectively. On top of that, ensure mutual authentication between agents and establish clear capability declarations to block unauthorized access and prevent privilege escalation in environments with multiple agents.
How do I prevent prompt injection from turning into a multi-agent breach?
To stop prompt injection from turning into a multi-agent security issue, it's crucial to put safeguards in place that prevent harmful instructions from spreading across agents. Pay close attention to securing how agents communicate with one another to prevent data leaks or unauthorized privilege escalation. Steps like reinforcing system prompts, keeping a close eye on agent interactions, and applying strict access controls can make a big difference. However, relying solely on prompt-level defenses isn't enough - it's essential to build security measures that protect the entire multi-agent system from injection attacks and larger breaches.
When should I require cryptographically signed human approvals?
Cryptographically signed human approvals play a crucial role when it comes to high-stakes or high-risk actions carried out by autonomous agents. They’re particularly important for tasks such as handling large financial transactions, exporting sensitive information, or rolling out critical system updates. These digital signatures guarantee that approvals are authentic, secure from tampering, and easily auditable. This added layer of security helps uphold both safety and compliance, especially in environments where multiple AI agents operate simultaneously.



