How to Secure Autonomous Agent Data
Autonomous agents demand strict inventory, short-lived identities, AES/TLS encryption, continuous monitoring, and layered defenses to prevent breaches.

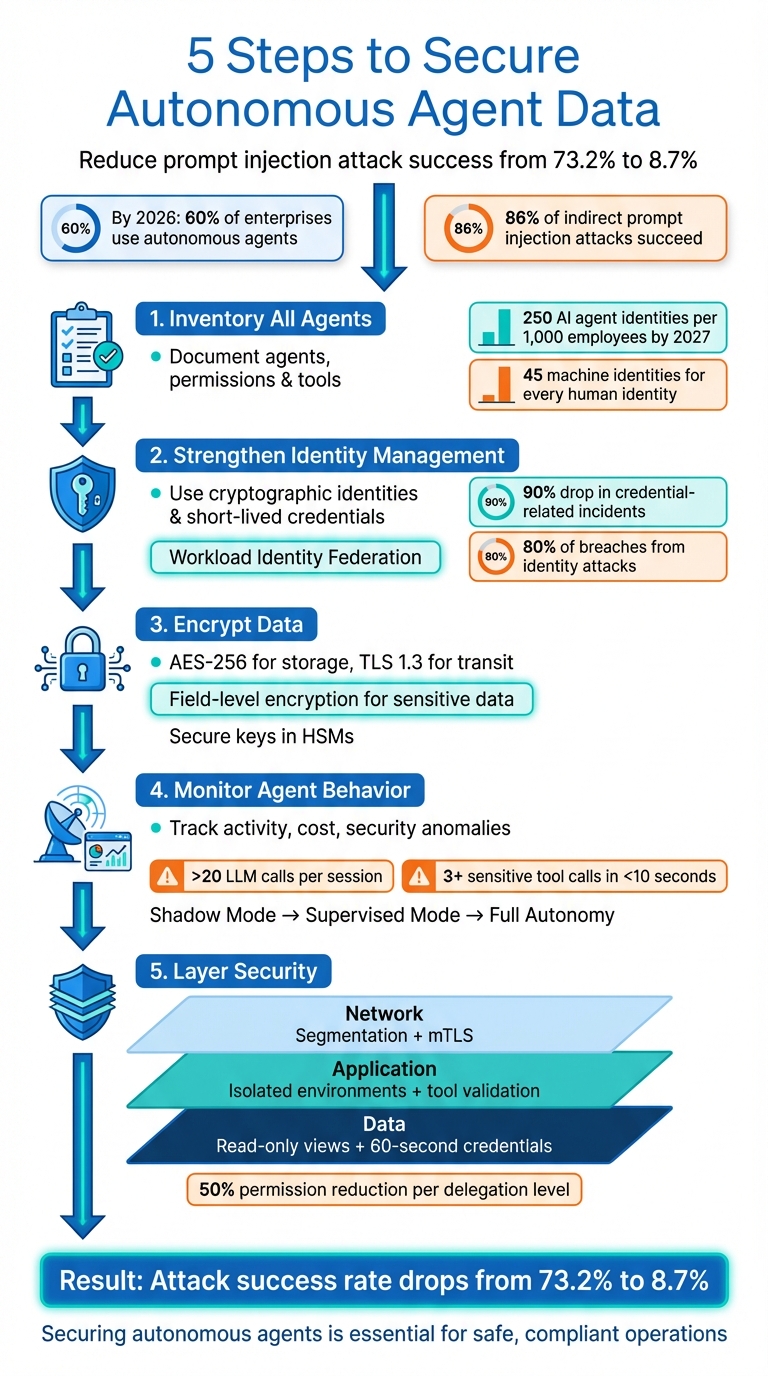
Autonomous agents are powerful but risky. They handle sensitive tasks like database updates, email communication, and financial transactions without direct human oversight. By 2026, over 60% of large enterprises use these systems, yet 86% of indirect prompt injection attacks succeed in exploiting them. A single breach can lead to regulatory violations, hefty fines, and operational chaos.
To protect these agents, follow these five steps:
- Inventory All Agents: Document every agent, its purpose, permissions, and tools. Identify and address shadow deployments.
- Strengthen Identity Management: Use cryptographic identities and enforce short-lived credentials.
- Encrypt Data: Apply AES-256 for storage and TLS 1.3 for transit while securing encryption keys.
- Monitor Agent Behavior: Track metrics like activity, cost, and security to spot anomalies early.
- Layer Security: Implement network segmentation, limit permissions, and enforce tool-layer validation.
Key stat: Proper defenses can reduce prompt injection attack success rates from 73.2% to 8.7%. Securing autonomous agents with expert AI consulting is no longer optional - it's essential for safe, compliant operations.
5-Step Framework for Securing Autonomous Agent Data
How to secure your AI Agents: A Technical Deep-dive
Understanding how to build multi-agent research teams is the first step toward implementing these security protocols effectively.
Step 1: Create a Complete Agent Inventory
You can't protect what you don't know exists. To secure your organization effectively, you need a clear picture of all autonomous agents in operation. This includes not only officially approved systems but also any agents employees may have created without formal approval.
Build Your Agent Catalog
Start by setting up a centralized registry to document every authorized agent in your environment. This registry should act as the definitive record, capturing key details about each agent's identity, purpose, and capabilities.
For each agent, document its unique cryptographic identity (such as X.509 certificates or OAuth tokens), its role, and the human owner responsible for it.
"Traditional IAM was designed for humans who log in, perform tasks, and log out. AI agents run continuously, spawn sub-agents, access dozens of tools, and make thousands of decisions per hour." - SCR Security Research Team
By 2027, the average organization is projected to manage over 250 AI agent identities per 1,000 employees. Right now, enterprises already handle 45 machine identities for every human identity. Clearly, traditional identity management systems aren't built for this level of complexity.
Here’s a breakdown of the essential fields to include in your agent catalog:
| Field | Description | Example |
|---|---|---|
| Agent ID | Unique identifier | agent-finance-prod-005 |
| Purpose | Primary function of the agent | Automated invoice processing |
| Owner | Human responsible for the agent | alex.smith@company.com |
| Permissions | API scopes and data access levels | ERP:Read, Storage:Write |
| Tools | External systems the agent can access | SAP API, Gmail, Slack |
| Data Class | Sensitivity of data handled | Confidential / PII |
| Environment | Deployment location | AWS Cluster-B / Production |
| Status | Operational state | Active / Suspended / Deprecated |
Make sure to record every API, database, SaaS tool, and third-party integration that the agent interacts with. Specify the permission levels for each - whether it’s read-only access to an ERP system or write access to customer databases. Also, track the credentials (user or service account) the agent uses to perform its tasks.
Special attention should be given to sub-agents - autonomous systems created by primary agents to handle specific tasks, often built using Agentic frameworks like LangChain or CrewAI. Each delegation level should ideally reduce permissions by at least 50% to minimize damage in case of a security breach.
Once your catalog is complete, it’s time to address undocumented or shadow deployments.
Find Undocumented Agent Deployments
While a formal catalog captures approved agents, uncovering unauthorized or "shadow" deployments is just as important. Studies reveal that 80% of organizations have faced AI agent-related risks, such as data leaks or unauthorized system access. However, only 29% feel prepared to handle these risks.
"If you cannot see what an agent does, you cannot secure it." - Innovaiden
Shadow agents often originate from SaaS platforms that allow employees to create automation freely. Tools like n8n, Tines, Workato, and Zapier are common culprits, as they enable users to build cross-platform workflows.
To address this, deploy AI Security Posture Management (AI-SPM) tools. These tools scan your cloud environments for undocumented models, exposed training data, and unauthorized agent deployments. They can also detect behavioral anomalies, such as spikes in authentication attempts, unusually high activity rates, or agents accessing unfamiliar data scopes.
Be vigilant about Model Context Protocol (MCP) servers, as they are often vulnerable. A review of over 7,000 MCP servers found that 36.7% were susceptible to server-side request forgery, and 492 lacked basic security measures like client authentication or traffic encryption. Monitoring API gateways for unusual behavior can help identify unauthorized activity.
After identifying undocumented agents, evaluate their business purpose. Decide whether to formalize, adjust, or decommission them. To prevent future shadow deployments, establish an AI Review Board (AIRB). This board should review all high-risk agent deployment requests to ensure they align with governance policies before going live. A structured approval process like this ensures security while meeting your organization’s operational needs. For organizations requiring specialized assistance in building these secure architectures, AI business consulting can help design and manage advanced multi-agent systems.
Step 2: Set Up Identity and Access Management (IAM)
After cataloging your agents, the next step is to ensure each one has a secure and verifiable identity. Unlike human users who log in periodically, autonomous agents operate nonstop, making thousands of API calls every hour. Traditional username-and-password systems simply can't keep up with this kind of activity.
Assign Workload Identity to Agents
Each agent needs a unique cryptographic identity - a sort of digital passport. The best way to achieve this is through Workload Identity Federation, where your infrastructure platform verifies an agent's identity using short-lived OpenID Connect (OIDC) tokens. Instead of embedding API keys in code or configuration files, agents receive temporary credentials directly from the runtime environment. This method has proven effective, with organizations reporting a 90% drop in credential-related security incidents.
"Our authentication systems were designed for humans, yet must now securely accommodate entities that never sleep, can operate at tremendous scale, and don't possess physical devices or biometric traits."
- Zack Proser, WorkOS
To secure communication and access, establish a three-tier authentication system based on the type of connection:
- Agent-to-API communication: Use OAuth 2.0 Client Credentials flow with tokens that expire every 5 to 15 minutes.
- Agent-to-agent communication: Implement Mutual TLS (mTLS) with unique X.509 certificates for cryptographic verification.
- Agent-to-data access: Issue short-lived database credentials through secrets vaults (e.g., HashiCorp Vault) that automatically revoke after use.
Long-lived API keys should be eliminated entirely. Identity-based attacks account for 80% of all security breaches, with 15% originating from stolen credentials embedded in outdated pipelines. If you're still embedding API keys in Docker images or CI/CD workflows, switch to workload identity federation immediately.
Once an agent's identity is secured, limit its access to only the resources it truly needs.
Apply the Principle of Least Privilege
Minimizing permissions is crucial. Assign agents only the access they need to perform their tasks. For example, separate read and write operations into different agents, and require human approval for any irreversible actions.
"Telling a model 'do not send payments' is not enforcement."
- Antonella Serine, Founder, KLA Digital
When agents create sub-agents to handle specific tasks, follow the 50% Rule: sub-agents should have at least 50% fewer permissions than their parent agent. Additionally, limit delegation chains to three levels, requiring human approval for any delegation beyond level two. This approach reduces the risk of a single compromised agent triggering a widespread system breach.
To further tighten control, use Attribute-Based Access Control (ABAC). This allows you to create policies based on factors like the agent's purpose, the delegating user, and the data's sensitivity. Set strict permission boundaries that cap the maximum access an agent can have, no matter what roles it inherits. Regularly review permissions - quarterly is a good benchmark - and automatically revoke any that haven't been used in the past 30 days.
Step 3: Encrypt Data at All Stages
Once identities are secured, the next priority is safeguarding data throughout its lifecycle. Autonomous agents often handle sensitive information like customer records or financial transactions, and a breach could expose vast amounts of data before it's even detected.
Encrypt Data at Rest and in Transit
To protect data effectively, use AES-256 encryption for data at rest and TLS 1.3 for data in transit. These encryption standards are designed to prevent unauthorized access and interception. For example, AES-256 ensures that even if someone gains access to your databases or model artifacts, the data remains unreadable without the proper encryption keys.
For communication between agents, implement Mutual TLS (mTLS) to establish secure, verified connections. This reduces the risk of impersonation. Tools like cert-manager or SPIFFE/SPIRE can help automate certificate management, minimizing the chances of human error.
When dealing with highly sensitive data, such as Social Security numbers or credit card details, apply field-level encryption. Instead of encrypting entire datasets, focus on specific fields to ensure that even if part of your system is compromised, the most critical data remains protected. Encryption keys should be stored securely in Hardware Security Modules (HSMs) or secrets managers like HashiCorp Vault, and rotated regularly to avoid key-related vulnerabilities.
"AI must be Secure by Design. This means that manufacturers of AI systems must... prioritize security throughout the whole lifecycle of the product, from inception of the idea to planning for the system's end-of-life."
While encryption is powerful, it has limitations. It secures data at rest and in transit but doesn’t protect it when it’s actively being used in an agent’s memory. To address this, combine encryption with techniques like sandboxing and execution isolation.
Verify Data Integrity with Cryptographic Signatures
While encryption ensures confidentiality, cryptographic signatures help verify the integrity of your data. Every model file, configuration, and instruction should be signed using Ed25519 before deployment. This step prevents attackers from quietly swapping out legitimate models for malicious ones.
Here’s how it works: A private key is used to sign messages, while a public key verifies them. This setup allows for easy key revocation and scalability across large networks of agents. To avoid issues caused by formatting differences, convert data into a consistent format (e.g., JSON with sorted keys) before signing or verifying.
However, signatures alone can’t stop replay attacks, where valid signed requests are reused maliciously. To prevent this, combine signatures with unique nonces (numbers used once) and timestamps. Ensure that these elements are validated in the correct order before executing any actions. For agent-to-API communication, issue signed JWT tokens with claims like agent ID, role, and permissions, and set short expiration times (5 to 15 minutes). This limits the potential damage if a token is compromised.
Organizations that adopt cryptographic model signing report fewer incidents of unauthorized model tampering. Make signing a mandatory step for every artifact, and configure your systems to reject anything that doesn’t pass verification. This approach significantly reduces risks like supply chain attacks and memory poisoning.
Step 4: Monitor and Analyze Agent Activity
After securing identities and encrypting data, the next critical step is to keep a close watch on agent activity. This ongoing monitoring acts as a safety net to catch and address new threats. Even with strong encryption and access controls, agents can fail in unexpected ways. As the CallSphere Team explains, "A compromised or misbehaving agent might have perfect latency and zero HTTP errors while systematically leaking data through legitimate tool calls". That’s why tracking behavioral patterns is so important.
Define Normal Agent Behavior Patterns
To identify problems, you first need to understand what "normal" behavior looks like. Start by running your agents in a controlled environment for about a week to gather baseline metrics. Focus on five main areas during this period:
- Liveness: Measure heartbeat signals every 1–5 minutes.
- Quality: Track first-pass approval rates, aiming for above 80%.
- Performance: Monitor how long tasks take to complete.
- Cost: Review token usage per session.
- Coordination: Observe handoff latency between agents.
Once you’ve collected this data, use the 95th percentile of each metric to set initial thresholds. For instance, if 95% of sessions use a certain number of tokens or less, flag any session that goes over this limit. This method keeps false positives to a manageable 2–5%. Update these baselines monthly as your agents evolve and usage patterns change.
Another key step is to define action schemas for each agent. These schemas outline permitted actions, required inputs, potential risks, and execution constraints. For example, if an agent makes three or more calls to sensitive tools (like those handling PII or data deletion) within 10 seconds, it should immediately trigger an investigation [35, 36]. With these baselines and schemas in place, you can move on to setting up automated anomaly detection.
Use Anomaly Detection Systems
Once your baselines are established, deploy automated tools to catch deviations in real time. Implement circuit breakers that can terminate agent sessions when critical alerts arise. For example, if an agent makes more than 20 LLM calls in one session or shows a sudden increase in sensitive tool usage, the system should shut down that session.
Be on the lookout for silent failures, where agents seem to operate normally but fail to produce meaningful results or get stuck in endless retry loops. It’s also crucial to monitor interactions between agents. Missing heartbeats for more than twice the expected interval (e.g., over 6 minutes), approval rates dropping below baseline, or unusual handoff patterns can all indicate issues. To maintain audit integrity, store all agent activity logs and traces in a separate database from the agent’s primary data.
| Metric Category | Normal Baseline | Anomaly Trigger |
|---|---|---|
| Liveness | Heartbeat every 2–3 minutes | Missing heartbeat for >6 minutes |
| Activity | Historical LLM call average | >20 calls per session |
| Security | Normal tool sequences | 3+ sensitive tool calls in <10 seconds |
| Cost | Average tokens per session | Consumption >95th percentile |
| Quality | >80% first-pass approval | Approval rate drops below baseline |
For new deployments, consider starting with graduated autonomy. Begin with "Shadow Mode", where agents only suggest actions, for 2–4 weeks. Then move to "Supervised Mode", where humans review all actions, for another 2–4 weeks. This gradual approach helps refine monitoring thresholds using real-world data before granting agents full autonomy.
Step 5: Build Layered Security Defenses
Layered security is all about creating multiple levels of protection, ensuring that even if one layer fails, others are there to stop an attack. As the ChatBotKit team explains:
"Securing an AI agent is fundamentally different from securing a traditional application... security must be built into the architecture, not bolted on as input validation"
This approach requires addressing security at every level of your system, from networks to applications and data.
Secure Network, Application, and Data Layers
Start with network security. Limit access by using network segmentation, so agents can only interact with the services they need. Add egress filtering to ensure agents only communicate with approved domains. Employ mTLS to secure communication between components.
For the application layer, run agent workloads in isolated environments using technologies like gVisor or Firecracker. This creates strict boundaries for operations. Combine this with well-defined IAM policies and encryption protocols. Design agents as microservices with limited tool access. Before executing any tool, validate its parameters against predefined schemas to prevent injection attacks. For high-risk actions, enforce human-in-the-loop (HITL) approval.
At the data layer, use read-only database views and issue credentials that expire quickly - such as database passwords that last only 60 seconds, issued from secure vaults. Implement output filtering to detect and redact sensitive information like PII before it leaves the system. These measures, when combined with earlier identity and encryption controls, form a cohesive security framework.
Stop Privilege Escalation Attacks
Privilege escalation occurs when an agent is manipulated into performing actions beyond what the user is authorized to do. To prevent this, apply the "Least Privileged Union" rule, ensuring an agent’s permissions are limited to the overlap between its own and the user’s privileges. In other words, an agent should never access resources the user cannot.
Avoid relying on prompts to enforce authorization. As Synlabs points out:
"Authorization must be enforced by systems, not by prompts. Tools should never execute a privileged action just because the agent asked nicely"
Instead, use tool-layer validation, where each tool independently checks the agent’s identity, the user’s identity, and the scope of the requested resource. A centralized authorization service (Policy Decision Point) can determine whether an agent has the necessary permissions to use a tool or access specific data.
For workflows involving multiple tasks, apply separation of duties. For example, one agent might handle reading a product catalog, while another completely separate agent processes purchases. In delegation chains, reduce permissions by at least 50% at each level and limit the chain to three sub-agents. For deeper chains, require human approval.
Conclusion
Securing data for autonomous agents is crucial to ensuring safe and compliant operations as we move into 2026. An Enterprise Security Architect from a Fortune 500 financial services company highlights the core issue:
"The biggest security risk with AI agents isn't what they're designed to do. It's what they're allowed to do when compromised".
Traditional security measures fall short when it comes to protecting these active, decision-making systems. As agents take on more responsibilities, the security landscape shifts dramatically. With machine identities now outnumbering human ones by a staggering 82:1, the potential attack surface has expanded significantly.
Addressing these risks requires a fresh approach. For example, deploying layered defenses can significantly reduce the success rate of prompt injection attacks - from 73.2% to just 8.7%. Key strategies include maintaining an up-to-date inventory of agents, enforcing strict identity controls, securing data across all stages, continuously monitoring activities, and implementing overlapping defense layers. Together, these practices form the backbone of a strong security framework.
For organizations managing large-scale deployments, NAITIVE AI Consulting Agency offers tailored solutions. Their expertise spans secure architecture design, identity management, regulatory compliance, and continuous monitoring, providing a comprehensive approach to safeguarding autonomous agents.
FAQs
What’s the fastest way to find “shadow” agents in our environment?
To spot "shadow" agents swiftly, start by analyzing network traffic. Keeping an eye on outbound traffic is particularly useful for identifying autonomous AI systems that are operating without proper oversight - especially if they’re making unexpected interactions with external systems.
Another effective approach involves using runtime governance tools. These tools can track agent activities and monitor API calls, helping to uncover agents that haven’t been approved. By focusing on unusual patterns in network and system logs, these methods make it easier to detect unauthorized agents quickly.
How do we replace long-lived API keys with short-lived agent credentials?
To improve security, swap out long-lived API keys for short-lived agent credentials through dynamic credential management and identity and access management (IAM) systems. These systems issue temporary credentials, like OAuth tokens, which come with defined permissions and expiration times. This method minimizes risk, simplifies revocation or rotation, and ensures agents function securely with limited exposure.
What monitoring signals catch prompt injection or data exfiltration early?
Monitoring for prompt injection or data exfiltration means keeping an eye out for unusual inputs, like suspicious or harmful prompts, and unexpected actions that fall outside normal behavior. Look for irregularities in how decisions are made - things like strange command sequences or unusual patterns of data access. These red flags can signal security issues, helping to catch potential threats early and safeguard the data of autonomous agents.



