Dynamic Resource Allocation for Multi-Agent AI Systems
Dynamic resource allocation turns rigid multi-agent AI into resilient, efficient systems using control/worker separation, affinity matching, and event-driven reassignment.

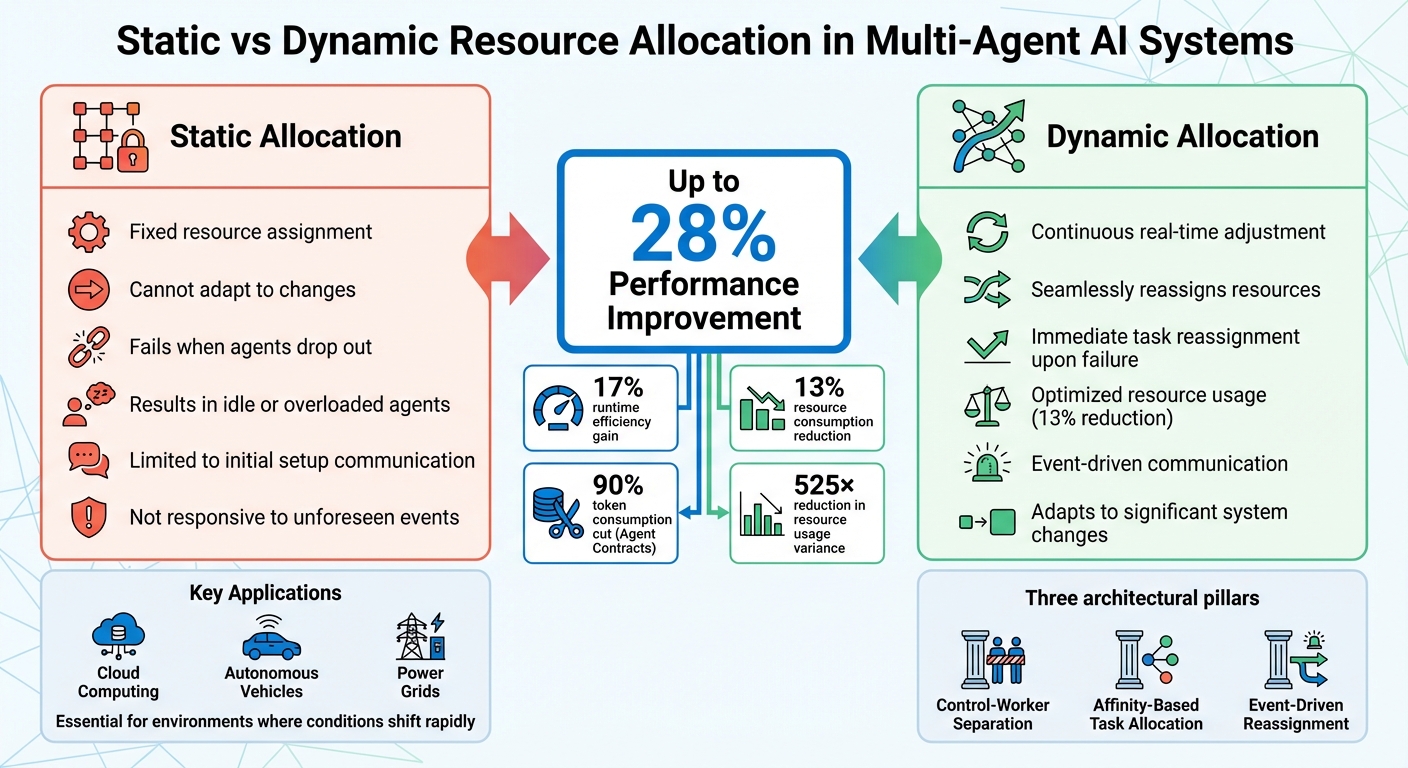
Dynamic resource allocation is transforming how multi-agent AI systems handle tasks and resources. Unlike static methods, which assign resources once and fail to adapt, dynamic approaches continuously adjust based on real-time needs. This ensures better efficiency, fewer bottlenecks, and higher success rates in unpredictable environments.
Key insights include:
- Dynamic vs. Static Allocation: Static methods struggle with changes, while dynamic systems reassign resources seamlessly, improving performance by up to 28%.
- Applications: Essential in cloud computing, autonomous vehicles, and power grids, where conditions shift rapidly.
- Architectural Patterns: Control-worker separation, affinity-based task allocation, and event-driven reassignment ensure smooth operation.
- Algorithms: Reinforcement learning, predictive models, and policy-based management each suit specific scenarios.
- Monitoring & Optimization: Real-time tracking and feedback loops maintain efficiency and responsiveness.
Dynamic allocation is vital for handling demand spikes, agent failures, and multi-tenant systems, making it a cornerstone of modern AI resource management.
Static vs Dynamic Resource Allocation in Multi-Agent AI Systems
Unleashing the Power of DRA (Dynamic Resource Allocation) for Just-in-Time GPU Slicing
Architecture Patterns for Dynamic Resource Allocation
Modern systems have moved beyond the limitations of static resource allocation, embracing dynamic patterns to meet the demands of multi-agent AI environments. Three key architectural patterns form the foundation of this approach, enabling systems to allocate resources efficiently and adapt to changing conditions.
Control Plane and Worker Plane Separation
One effective strategy is dividing the system into a global control plane and a localized worker plane. The control plane acts as the system's central coordinator, managing high-level tasks like agent-oriented planning, scheduling, and anomaly detection. Meanwhile, the worker plane comprises individual agents responsible for local tasks and decision-making. This setup was tested with the DRAMA framework in August 2025, showing a 17% improvement in runtime efficiency and a 13% reduction in resource consumption compared to older methods.
The control plane also monitors the entire system through heartbeat signals from worker agents, allowing it to quickly detect and respond to failures. For instance, in the Communicative Watch-And-Help environment, the control plane instantly reassigned tasks when an agent was removed mid-operation. As Naibo Wang et al. described:
"The control plane functions as the system's global brain... while the worker plane consists of a heterogeneous cluster of agents... This separation of responsibilities allows the control plane to focus on global coordination and adaptation, while empowering worker agents with local autonomy." – Naibo Wang et al.
This separation ensures that failures or disruptions are addressed without derailing the entire system, maintaining operational flow and efficiency.
Affinity-Based Task Allocation
Dynamic task allocation goes beyond structural separation, requiring strategies like affinity matching and event-driven reassignment. Affinity-based methods pair tasks with agents based on factors like capabilities, proximity to data, and workload. A common approach is the Planner-Critic framework, where the "Planner" suggests allocations based on affinity scores, and the "Critic" evaluates these against system-wide goals before finalizing assignments.
In practice, this approach simplifies scheduling by treating both agents and tasks as standardized resource objects. For example, the MG-RAO algorithm, which uses approximations of resource demand, demonstrated a 23% to 28% boost in allocation efficiency over fixed methods. Additionally, breaking down resource allocation into smaller groups rather than treating all agents as a single entity improved performance by approximately 53.5% in volatile systems.
Event-Driven Resource Reassignment
Event-driven architectures further enhance adaptability by reallocating resources only when significant changes occur, such as agent arrivals, departures, or task completions. This approach reduces unnecessary communication while ensuring the system stays responsive. A Monitor Agent oversees system health through heartbeat signals and triggers reassignment when anomalies are detected.
As Naibo Wang et al. noted:
"This event-driven mechanism ensures that DRAMA remains robust and adaptive by updating task assignments only in response to significant changes in the system state." – Naibo Wang et al.
The benefits are clear. In January 2026, the Agent Contracts framework demonstrated that event-driven governance could cut token consumption by 90% and reduce variance in resource usage by a staggering 525× compared to standard autonomous protocols.
| Feature | Static Allocation | Event-Driven Dynamic Allocation |
|---|---|---|
| Adaptability | Fixed; fails if agents drop out | Reassigns tasks immediately upon failure |
| Resource Use | Often results in idle or overloaded agents | Improved usage (e.g., 13% reduction) |
| Responsiveness | Cannot adapt to unforeseen events | Immediate reallocation upon significant events |
| Communication | Limited to initial setup | Efficient, triggered by events |
These patterns - control/worker separation, affinity-based task allocation, and event-driven reassignment - provide a robust framework for dynamic resource allocation. Together, they allow systems to handle disruptions effectively, maximize resource efficiency, and adapt to changes in real time, all while minimizing computational strain. This architecture lays the groundwork for selecting the best algorithms for resource allocation in multi-agent environments.
Selecting Algorithms for Resource Allocation
Dynamic allocation is at the heart of efficient multi-agent systems, and selecting the right algorithm can make or break its effectiveness. The choice depends heavily on the system's characteristics. Three main approaches dominate the landscape: reinforcement learning, policy-based management, and predictive machine learning models. Each caters to specific operational needs.
Reinforcement Learning Methods
Reinforcement learning (RL) excels in decentralized and constantly evolving environments, where agents must learn through trial and error to determine the best strategies. Multi-Agent Reinforcement Learning (MARL) is particularly useful when agents only have partial views of the system. As Mohamad A. Hady explains:
"MARL is particularly suited to tackling RAO [Resource Allocation Optimization] challenges, as it enables decentralized, adaptive decision-making".
Take the Reclaimer deep RL model, for instance. In cloud microservices, it reduced mean CPU core allocation by 38.4% to 74.4% compared to standard scaling solutions, all while maintaining Quality-of-Service standards. It also outperformed other non-RL methods by 27.5% to 58.1% in CPU efficiency. Similarly, MARL frameworks like Centralized Training Distributed Execution (CTDE) strike a balance between global coordination and real-time local decision-making, making them ideal for large-scale systems like multi-agent research teams, IoT networks, or smart grids.
That said, RL isn't without challenges. Training can be complex, and dynamic environments often introduce issues like non-stationarity. For systems where agents have limited information, MARL frameworks are the go-to choice. When dealing with resource types, Integer Programming is suited for discrete items like machines, while real-valued variables work better for continuous resources like bandwidth.
For more predictable systems, policy-based management offers a simpler alternative.
Policy-Based Resource Management
Policy-based approaches rely on predefined rules, Service Level Agreements (SLAs), and classical optimization methods like Linear Programming. These systems are computationally efficient and easy to implement, making them ideal for stable environments with predictable workloads.
However, adaptability is their weak point. They assume relatively static conditions and struggle in rapidly changing environments. For instance, simple threshold-based scaling - like adding server capacity when CPU usage hits 80% - works well in straightforward scenarios but falters with complex agent interactions or unexpected disruptions. Use this approach when your system has clear visibility, stable patterns, and SLAs that don’t require frequent updates.
Using Predictive Machine Learning Models
Predictive models take a different approach by forecasting resource demands. By analyzing historical data, they anticipate future needs, allowing proactive allocation instead of reactive adjustments. A hybrid system combining predictive models with RL can enhance task prioritization. For example, the MG-RAO algorithm demonstrated a 23% to 28% improvement over fixed resource allocation in simulated dynamic environments.
The success of predictive models hinges on data quality. In volatile systems, dividing agents into separate groups for modeling - rather than treating them as a single entity - can boost performance by over 50%.
| Method | Best Use Case | Key Limitation |
|---|---|---|
| Linear Programming | Static environments, cost minimization | Computationally expensive for real-time scaling |
| Heuristic (GA/PSO) | Complex search spaces, near-optimal needs | Limited adaptability; rules must be hand-tuned |
| MARL (Q-Learning/Deep RL) | Dynamic, decentralized, non-stationary | High training complexity, non-stationarity issues |
| Predictive Modeling | Anticipating demand spikes from history | Requires high-quality historical data |
Each method has its strengths and weaknesses, and the right choice depends on factors like system scale, demand variability, and available data.
When using Large Language Models (LLMs) as agents, the "planner" method has proven more effective than the "orchestrator" method for handling concurrent actions. Research by Alfonso Amayuelas and colleagues shows that explicitly providing information about worker capabilities improves allocation strategies, especially in systems with less-than-ideal workers. This highlights a growing trend of LLMs acting as planners for self-allocation in multi-agent environments.
These algorithm choices lay the groundwork for the monitoring and optimization strategies that ensure systems remain efficient and reliable - topics we’ll dive into next.
Monitoring and Optimization Strategies
To make dynamic allocation methods truly effective, continuous monitoring is essential. Without it, even the most advanced systems can falter. Real-time tracking helps identify shifts in agent performance caused by load changes or varying contexts. This level of visibility is what sets adaptive systems apart from static ones.
Tracking Resource Usage
The first step in effective tracking is choosing the right metrics. Key performance indicators include average latency, throughput (requests per second), success rate, "Total Steps" (a measure of overall resource use, including energy, time, and throughput), and "Average Steps" (which reflects task completion efficiency).
A practical example comes from January 2026, when researchers Guilin Zhang, Wulan Guo, and Ziqi Tan tested an adaptive GPU resource allocation framework. Using an NVIDIA T4 GPU, they ran a 100-second workload involving four heterogeneous agents (one coordinator and three specialists). Their adaptive strategy slashed average latency from 756.1 seconds (with round-robin scheduling) to just 111.9 seconds - an impressive 85% reduction. The system also maintained a throughput of 58.1 requests per second, preventing agent starvation by implementing priority-based weighting and minimum resource guarantees.
Modern serverless GPU platforms, such as those using NVIDIA MIG, rely on tools like time-slicing to handle diverse workloads. "Monitor agents" play a crucial role here, gathering system-wide data - like heartbeat signals and task progress reports - to enable quick, informed adjustments.
These metrics and tools lay the groundwork for real-time optimization through feedback mechanisms.
Feedback Loops for Real-Time Adjustments
Feedback loops are the backbone of real-time optimization. They allow systems to track prediction errors and refine internal models incrementally, often prioritizing recent data through weighted updates or exponential forgetting. This approach is especially effective in addressing behavioral drift, where agent performance evolves over time.
Techniques like decentralized synchronization - using SPSA-based consensus - ensure distributed controllers can keep task models consistent, even when feedback is noisy or delayed. Another useful tool is the use of "trust coefficients", which compare predicted durations to actual elapsed times. This prevents underestimating resource needs during operations.
With feedback loops in place, systems can dynamically adjust resource usage to maintain both efficiency and responsiveness.
Balancing Efficiency and Responsiveness
Finding the right balance between resource efficiency and system responsiveness is a delicate but crucial task. One effective strategy is assigning higher priorities to lightweight coordinator agents, reducing orchestration overhead. Specialist agents, meanwhile, can operate at medium priority to prevent bottlenecks in task distribution.
Adaptive allocation algorithms with O(N) complexity allow for millisecond-scale resource adjustments, which are vital for maintaining service quality during demand surges. To avoid agent starvation in multi-tenant systems, minimum resource thresholds - such as allocating 10% to 35% of GPU resources per agent type - should be established. Even when demand exceeds capacity by up to 3×, normalization strategies can limit latency increases to about 24%.
Hierarchical memory management also plays a key role. By retaining detailed data for critical tasks and summarizing less essential past events, agents can conserve memory without sacrificing responsiveness during extended operations.
Managing Dynamic Scenarios
This section builds on the concepts of dynamic allocation and architectural patterns to explore how to handle real-world challenges. Dynamic systems must be ready to tackle unexpected issues like sudden demand spikes, agent failures, or network bottlenecks.
Handling Sudden Demand Spikes
Imagine your system faces a 10× surge in demand - this requires immediate action, often within milliseconds. A solid three-step approach can help manage such situations:
- Combine arrival rates with task priorities to calculate demand.
- Allocate resources proportionally based on these demand scores.
- Adjust allocations to ensure they stay within capacity limits.
"The fundamental challenge lies in dynamically allocating limited GPU resources across multiple agents with competing requirements while minimizing costs and maintaining quality of service." – Guilin Zhang, Corresponding Author, George Washington University
During demand surges, priority-based scheduling becomes essential. Higher priority should be given to coordinator agents, which handle workflow orchestration. This avoids bottlenecks caused by orchestration overhead while specialist agents manage more resource-intensive tasks. When demand exceeds capacity by up to 3×, normalization techniques can keep latency increases at around 24%, preventing total system breakdown.
Machine learning models can predict resource needs, helping to avoid bottlenecks. Instead of constant polling, an event-driven approach triggers resource reallocation only during significant events, like a sudden spike in demand. This reduces computational overhead while maintaining responsiveness . Additionally, resource preemption ensures that lower-priority tasks can temporarily give up resources when needed.
Once demand surges are under control, the next hurdle is managing system resilience during agent failures.
Managing Agent Dropout and Failures
Failures in distributed systems are inevitable, but they don’t have to be catastrophic. A monitor agent can track periodic heartbeat signals from worker agents. If an agent stops responding, tasks can be reassigned to available agents automatically, avoiding the need for manual intervention. Tests show that the DRAMA framework excels in these scenarios, completing tasks even when agents drop out, unlike alternatives such as CoELA, MCTS, and ProAgent.
Task reassignment can be optimized using affinity-based allocation, which considers factors like agent capabilities, location, and workload. By decoupling tasks from specific agents, the system can seamlessly reassign work. Modeling agents and tasks as resource objects with defined lifecycles simplifies the eviction and reassignment process.
To improve recovery efficiency, hierarchical memory management retains only critical task data, discarding unnecessary details. This keeps recovery phases efficient and manageable.
With individual agent failures addressed, the focus shifts to preventing bottlenecks in multi-tenant setups.
Preventing Bottlenecks in Multi-Tenant Systems
Multi-tenant environments introduce unique challenges, as multiple users or applications compete for shared resources. The Multi-Group Resource Allocation Optimization (MG-RAO) algorithm tackles this by allocating resources to specific groups of agents rather than treating the system as a single entity. This group-based approach improves allocation efficiency by 23–28% compared to fixed methods in dynamic environments.
To reduce communication overhead and network congestion, avoid broadcasting tasks to the entire system. Instead, use restricted visibility, ensuring tasks are only visible to agents capable of handling them . For shared state conflicts, implement resolution strategies like voting or weighted merging to prevent resource contention.
Finally, set strict iteration limits on maker-checker loops or refinement patterns to avoid excessive resource use. For behavioral prediction, leverage recursive models with exponential forgetting. This allows controllers to adapt to performance shifts while prioritizing recent data.
Conclusion
Core Principles Summary
Dynamic resource allocation reshapes multi-agent AI systems, turning rigid setups into flexible, efficient platforms. By separating the control and worker planes, systems achieve global coordination while maintaining local autonomy for individual agents. Treating agents and tasks as resource objects ensures smooth reassignment during failures or demand spikes, enhancing overall performance.
Affinity-based allocation proves more effective than static binding by matching tasks to agents based on real-time capabilities and workloads. DRAMA not only boosts runtime efficiency but also reduces resource consumption. Meanwhile, Agent Contracts help cut token usage and stabilize workflows. In multi-tenant setups, assigning resources to specific agent groups rather than managing the system as a single entity improves efficiency by 23–28%.
These principles lay the groundwork for the future of AI resource management, which is now moving towards integrating advanced hybrid and predictive models.
Future Trends in AI Resource Management
With the success of dynamic resource allocation, new trends are set to redefine AI resource management. Hybrid Cloud-Edge frameworks and Graph Neural Networks are enabling local decision-making while orchestrators oversee system-wide operations. Hierarchical and mean-field Multi-Agent Reinforcement Learning (MARL) models now manage thousands of agents working in sync. Formal resource governance tools, like Agent Contracts, bring predictability and accountability to autonomous AI systems. Industries ranging from smart grids to autonomous transportation are increasingly relying on MARL-based allocation to handle their real-time, complex demands.
How NAITIVE AI Can Help
NAITIVE AI takes these dynamic resource strategies and turns them into actionable solutions for businesses looking to enhance their AI systems. Our consulting agency specializes in designing DRAMA-inspired control-worker architectures and hybrid edge-cloud frameworks tailored to your specific operational needs. We implement features like event-driven reassignment, affinity-based scheduling, and hierarchical memory management to ensure your AI agents remain responsive and resilient under any conditions. Whether you require autonomous agent teams for intricate workflows or voice agents delivering 24/7 support, we deliver measurable results. Visit NAITIVE AI Consulting Agency to see how we can turn your AI infrastructure into a powerful competitive edge.
FAQs
When should I use reinforcement learning vs. policy-based allocation?
Reinforcement learning (RL), particularly multi-agent RL, shines in complex and ever-changing environments. These are scenarios where agents need to learn and adapt strategies through constant interaction. It’s especially useful in unpredictable situations that demand ongoing adjustments.
On the other hand, policy-based allocation is more suited to stable settings. In such cases, predefined rules or domain-specific knowledge can effectively guide how resources are distributed.
In short, choose RL for high complexity and adaptability, while policy-based methods are ideal for predictable, rule-based contexts.
What metrics should I monitor to trigger reallocations safely?
To ensure reallocations are handled safely, keep a close eye on resource usage patterns, system performance metrics, and workload forecasts. Leverage real-time monitoring tools and predictive modeling to maintain efficient resource management while reducing potential risks.
How do I prevent starvation and bottlenecks in multi-tenant agent systems?
To avoid starvation and bottlenecks, focus on flexible and decentralized resource allocation methods. Dynamic resource management allows for adjustments based on workload needs and priorities, ensuring resources are distributed fairly. Decentralized systems enhance scalability and respond better to shifting tasks. Additionally, preemption mechanisms help by reallocating resources to prioritize critical tasks. Together, these approaches boost efficiency, prevent resource hoarding, and reduce bottlenecks in shared environments.



