Bias in Customized AI Models: Key Concerns
Unchecked bias in customized AI models entrenches inequality, harms marginalized groups, and demands proactive mitigation across the AI lifecycle.

Bias in AI models is a critical issue that affects fairness, equity, and trust in technology. From unbalanced training data to flawed algorithms, these biases can amplify stereotypes, reinforce discrimination, and lead to unfair outcomes in areas like hiring, healthcare, and law enforcement. Here’s a quick breakdown of the main causes and their impact:
- Representation Bias: When training data doesn't reflect real-world diversity, AI models fail to perform equally across different groups.
- Historical Bias: Models inherit societal prejudices from past data, perpetuating outdated norms.
- Measurement Bias: Errors in data collection or reliance on inaccurate proxies skew results.
- Algorithmic Bias: Design choices and optimization processes favor certain outcomes, often at the expense of minority groups.
- Confirmation Bias: Homogeneous development teams unintentionally reinforce their own perspectives in AI systems.
- Proxy Bias: Neutral-seeming variables indirectly encode sensitive attributes, leading to discrimination.
- Cultural Blind Spots: Models trained on Western data struggle to interpret non-Western contexts accurately.
- Stereotyping Bias: AI outputs reinforce harmful stereotypes based on biased training data.
- Prejudice Bias: Overgeneralized assumptions about groups distort individual evaluations.
- Long-Term Effects: Unchecked bias creates feedback loops, worsening inequality and eroding trust.
Key Stats:
- 68% of executives spend $10M+ on AI annually, yet biased systems undermine their goals.
- AI-generated images often depict CEOs as white males while misrepresenting women and minorities.
- A 2019 study showed facial recognition systems had a 34.7% error rate for dark-skinned women.
Solutions:
- Use diverse datasets and test models across various groups.
- Employ tools like "Datasheets for Datasets" and IBM’s AI Fairness 360.
- Involve diverse teams and ethical experts during development.
- Regularly audit and monitor AI systems to identify hidden biases.
Bias in AI isn’t just a technical problem - it has societal consequences. Addressing these issues requires deliberate action at every stage of the AI lifecycle to ensure systems work equitably for all users.
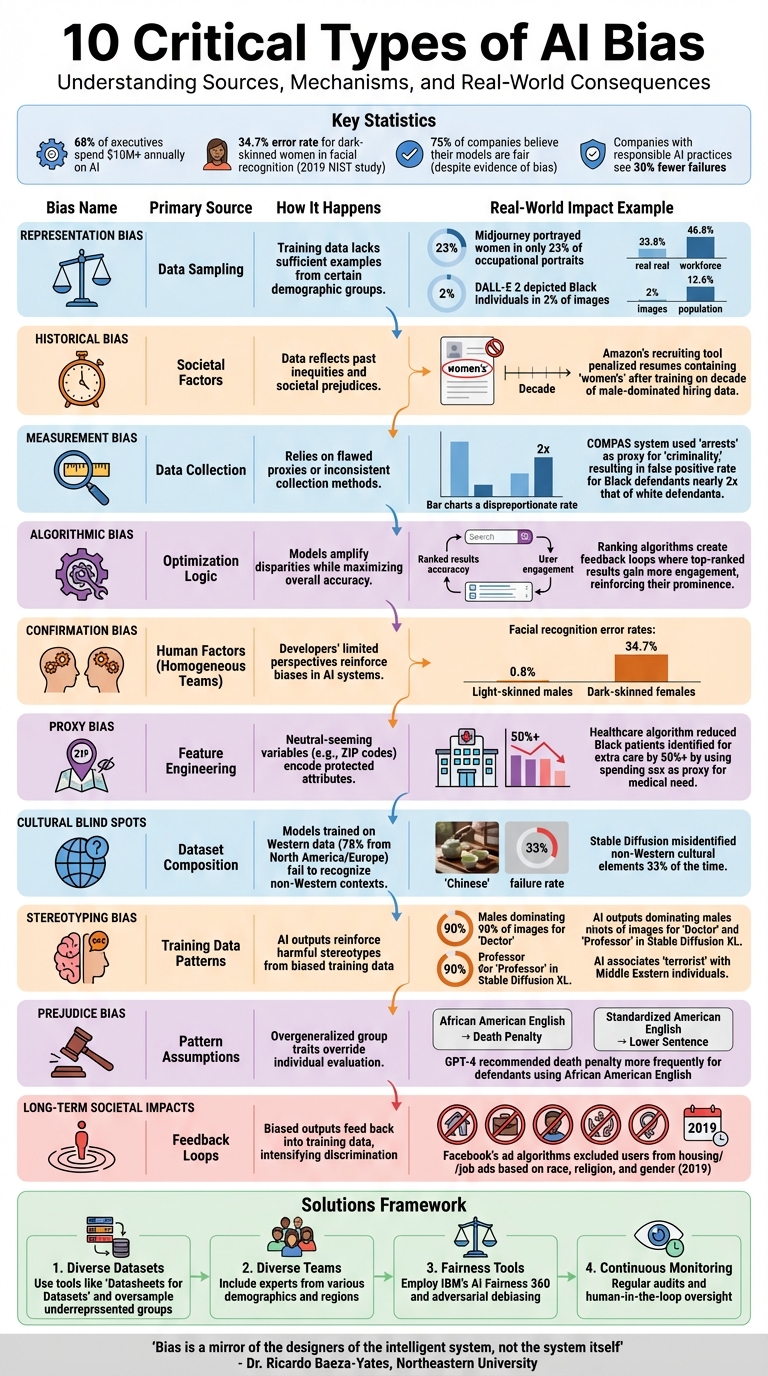
10 Types of AI Bias: Sources, Mechanisms, and Real-World Impacts
Unmasking Bias in AI: Challenges, Consequences, and Better Practices
1. Representation Bias from Unbalanced Training Data
Representation bias happens when the training data doesn't accurately reflect real-world demographics. This imbalance can lead to some groups being overrepresented while others are underrepresented, causing AI systems to learn and perpetuate skewed perceptions of reality. This isn't just a technical hiccup - it’s a deeper fairness issue that can affect how well models perform across different populations.
Take the 2024 study by Zhou et al., for example. They analyzed over 8,000 AI-generated images from tools like Midjourney, Stable Diffusion, and DALL-E 2, using prompts such as “A portrait of [occupation].” The findings were striking: Midjourney portrayed women in just 23% of occupational portraits, despite women making up 46.8% of the U.S. labor force. Similarly, DALL-E 2 depicted Black individuals in only 2% of images, far below the real-world figure of 12.6%. These disparities mean that AI models trained on such unbalanced datasets may start associating certain jobs or roles with specific demographics, reinforcing outdated stereotypes about authority and competence.
The root of these imbalances often lies in biases during data collection, such as sampling, coverage, or non-response biases. These issues don’t just stay theoretical - they lead to real-world system errors.
"Representation bias arises from factors like historical discrimination and selection biases in data acquisition." – Nima Shahbazi, Researcher, ACM Computing Surveys
For instance, facial recognition systems trained mostly on lighter-skinned faces tend to have higher error rates for darker-skinned individuals. Similarly, when loan default datasets overrepresent younger people, the AI might unfairly predict negative outcomes for that entire age group. A notable example is ImageNet, a widely used AI dataset, which had to remove over 500,000 images from its "person" category in 2019 after systemic biases were uncovered.
To address representation bias, AI consulting experts recommend curating diverse datasets, oversample underrepresented groups (using methods like SMOTE), and ensure transparency through tools like "Datasheets for Datasets." These steps tackle the core issues of sampling and coverage bias, helping create AI systems that better reflect the diversity of the real world.
2. Historical Bias Inherited from Past Datasets
Historical bias occurs when AI systems are trained on data that reflect outdated societal norms or discriminatory practices. Unlike representation bias, which arises from unbalanced data sampling, historical bias can persist even in datasets that are perfectly sampled. The issue lies in the fact that historical data often mirror inequities from the past, leading AI systems to reinforce these patterns under the guise of objectivity.
"Historical bias is the already existing bias and socio-technical issues in the world and can seep into from the data generation process even given a perfect sampling and feature selection." – Ninareh Mehrabi et al., Researchers, USC-ISI
This type of bias has shown its impact across various industries, with several notable examples highlighting the problem. One infamous case involved Amazon's recruiting tool, which was found to systematically penalize female candidates. The algorithm, trained on a decade's worth of resumes dominated by men, downgraded applications that mentioned terms like "women's" or referenced all-women's colleges. Similarly, in October 2019, researchers exposed an Optum algorithm used in healthcare that disproportionately favored white patients over Black patients. The tool relied on historical healthcare spending as a proxy for medical need, which led to the misclassification of Black patients - who historically had less access to healthcare - as lower-risk.
Another example dates back to 1988, when the U.K.'s Commission for Racial Equality revealed that St. George's Hospital Medical School used a shortlisting algorithm for admissions. This system, trained on historical data, replicated biases against women and non-European applicants. These cases illustrate how AI can perpetuate and even legitimize discriminatory practices, especially in critical areas like hiring, healthcare, and education.
To combat historical bias, organizations need to take proactive steps. This includes analyzing datasets for structural dependencies with the help of domain experts, identifying proxy variables (like zip codes) that may encode sensitive information, and using tools like IBM's AI Fairness 360 to assess models across diverse groups before deployment. Transparency can also be improved by documenting data origins through initiatives like "Datasheets for Datasets", which help uncover potential biases. Additionally, consulting with AI business consulting experts in fairness and ethics can provide further guidance in addressing these challenges.
3. Measurement Bias in Data Collection Methods
Measurement bias is a unique challenge that arises directly from how data is collected in real time. Unlike historical bias, which reflects patterns rooted in societal history, measurement bias happens during the data collection process itself. It can result from faulty equipment, inconsistent human practices, or the use of proxies that fail to accurately represent the concepts they are intended to measure.
"Measurement bias is introduced by errors in human measurement, or because of certain intrinsic habits of people in capturing data." – Ramya Srinivasan and Ajay Chander, AI Researchers
This type of bias can show up in various ways, each with a direct impact on the accuracy of AI models. For instance:
- Capture bias: This occurs when human habits influence data collection. A good example is photographers consistently shooting from similar angles. AI models trained on such data may struggle to recognize objects from different viewpoints.
- Device bias: Hardware issues, like defective camera sensors, can lead to poor-quality data. This, in turn, results in unreliable predictions.
- Proxy bias: This happens when a measurable variable is used as a stand-in for an abstract concept but fails to capture it accurately.
The effects of measurement bias can be serious. A 2019 study by the National Institute of Standards and Technology (NIST) examined 189 facial recognition algorithms from 99 developers. It found that measurement bias significantly raised error rates, particularly for minority groups.
Another striking example comes from ProPublica's 2016 investigation into the COMPAS system used in Broward County, Florida. The system relied on "arrests" as a proxy for "criminality." Because minority communities were more heavily policed, the link between crime and arrests was skewed. This led to a false positive rate for Black defendants nearly double that of white defendants.
Addressing measurement bias is crucial because it often interacts with other forms of bias, shaping the outcomes of AI systems. To combat it, organizations can work with a specialized AI agency to standardize annotation processes with clear guidelines, ensuring proxies accurately reflect the intended concepts across all groups, and identifying structural dependencies to pinpoint potential sources of error.
4. Algorithmic Bias in Model Optimization
Model optimization decisions can introduce their own forms of bias, separate from those caused by data. Even with perfectly balanced datasets, the way algorithms are designed and optimized can unintentionally favor certain outcomes. This happens because algorithms often rely on design constraints, specific objective functions, or efficiency shortcuts that inherently skew results.
One key issue lies in how success is defined during optimization. Machine learning models typically focus on a single metric, like minimizing cross-entropy loss or maximizing overall accuracy. While this seems logical, it can lead to unintended consequences. For instance, a model might overlook patterns in smaller, minority subgroups in order to achieve a better overall score. As MIT researchers Harini Suresh and John Guttag point out, this "learning bias" can widen performance gaps across different subsets of data.
Certain optimization techniques highlight this problem further. Methods like model pruning, which emphasize frequent features, or differential privacy, which limits the model's ability to learn from rare examples, can inadvertently reduce accuracy for underrepresented groups.
Even the algorithms themselves can introduce bias, regardless of data quality. For example, algorithms that rely on pseudo-randomness may unfairly favor items based on their position - either earlier or later in a list - rather than distributing attention evenly. Search engines and recommendation systems also illustrate this issue through "ranking bias." These systems often prioritize top-ranked results, which then attract more user engagement, reinforcing their prominence in future iterations.
To tackle algorithmic bias, organizations can take proactive steps, such as involving diverse teams during the design process, ensuring human oversight for reviewing AI outputs, and conducting independent audits both before and after deployment.
"Bias reduces AI's accuracy, and therefore its potential" – IBM
5. Confirmation Bias from Homogeneous Development Teams
When it comes to building AI systems, the people behind the technology play a huge role in shaping how it functions, often requiring specialized AI consulting to ensure balanced development. Unfortunately, when development teams lack diversity, their perspectives - often limited by shared experiences - can unintentionally reinforce biases within AI models. This phenomenon, known as confirmation bias, becomes even more pronounced in homogeneous teams.
According to the EEOC, between 63.5% and 68.5% of high-tech employees are white, and men occupy 80% of executive roles in the tech industry. These statistics highlight a lack of diversity that can lead to real-world consequences. Dr. Ricardo Baeza-Yates, Director of Research at Northeastern University's Institute of Experiential Artificial Intelligence, explains:
"Bias is a mirror of the designers of the intelligent system, not the system itself".
A striking example of this occurred when Amazon scrapped its experimental AI recruiting tool. The system penalized resumes containing the word "women's" (e.g., "women's chess club") because it had been trained on a decade of hiring data dominated by male candidates. The development team failed to account for this historical bias during the design process. Similarly, when the Apple Card launched, tech entrepreneur David Heinemeier Hansson revealed his wife received a credit limit 20 times lower than his, despite her higher credit score. Apple co-founder Steve Wozniak reported a similar 10x discrepancy for his wife. These cases highlight how a lack of diversity in AI development teams can perpetuate systemic inequities.
The problem extends beyond individual instances. Facial recognition systems from major tech companies show error rates as low as 0.8% for light-skinned males but soar to 34.7% for dark-skinned females. These disparities trace back to the composition of the teams designing and testing these systems. On the flip side, companies that prioritize responsible AI practices see nearly 30% fewer failures. Even more compelling, organizations with robust approaches to responsible AI double their profits from AI initiatives compared to those that don’t.
To create fairer, more effective AI, diversity must be a priority from the start. This means hiring people from a variety of demographics and regions, forming AI ethics boards with diverse experts, and conducting regular human-in-the-loop audits to examine AI decisions. As Preeti Shivpuri, Trustworthy AI Leader at Deloitte Canada, puts it:
"Engaging consultations with different stakeholders and gathering diverse perspectives to challenge the status quo can be critical in addressing inherent biases within data and making AI systems inclusive from the start".
6. Proxy Bias via Sensitive Feature Engineering
Even when developers exclude sensitive attributes like race or gender from AI models, bias can still find its way in through proxy variables - features that seem neutral but are strongly tied to protected characteristics. In the United States, ZIP codes are a classic example. Because of historical housing segregation and redlining, a ZIP code can often predict a person's race with surprising accuracy. When AI models use ZIP codes to make decisions about loans, insurance, or hiring, they can unintentionally mirror race-based discrimination - even without explicitly using race as an input. This shows how hidden correlations can quietly undo efforts to ensure fairness.
Machine learning algorithms, built to find patterns, can effectively reconstruct sensitive information even if it's been removed. As law professors Anya Prince and Daniel Schwarcz point out:
"AIs armed with big data are inherently structured to engage in proxy discrimination whenever they are deprived of information about membership in a legally-suspect class whose predictive power cannot be measured more directly by non-suspect data available to the AI".
In March 2021, data scientists from BCG GAMMA, including Sibo Wang and Max Santinelli, audited a Random Forest model trained on 1994 census data. They discovered that the "Relationship" feature overlapped 37% with "Sex" because terms like "husband" and "wife" directly encoded gender. By merging these into a single "married" category and removing "Marital Status", they nearly eliminated redundancy with the protected "Sex" attribute - without compromising the model's performance.
What makes proxy bias especially tricky is that nonlinear combinations of seemingly neutral features can still predict protected characteristics. For example, research on the same census data revealed that while "Occupation" alone was a weak proxy for sex (0.64 AUC), combining it with "Marital Status" created a much stronger proxy (0.78 AUC). The algorithm doesn’t need obvious indicators - it can stitch together subtle hints from multiple features.
To tackle this, organizations must go beyond simple correlation checks. Tools that explain model behavior can help identify feature redundancies and expose hidden nonlinear relationships. Sensitive feature engineering can transform variables so they remain useful without acting as proxies. It’s also important to recognize that protected characteristics are often redundantly encoded across multiple features, and advanced algorithms are skilled at piecing these together. If left unchecked, proxy bias can reinforce discrimination in critical areas like lending, hiring, and insurance.
7. Cultural Blind Spots in Model Design
Cultural blind spots can significantly undermine the accuracy of AI systems. Models trained predominantly on Western data often fail to grasp cultural nuances from non-Western regions. A study conducted in April 2025 by Algoverse AI Research, led by Muna Numan Said and Praneeth Medepalli, analyzed 2,400 images generated by Stable Diffusion v2.1. Their findings were striking: the model misidentified non-Western cultural elements 33% of the time. For instance, it mislabeled a "Japanese tea ceremony" as "Chinese." The root cause? A phenomenon called superposition in latent space, where minority cultural concepts overlap more frequently than mainstream ones - accounting for 72% of these errors.
This issue arises because major training datasets, like the LAION-5B dataset, are overwhelmingly skewed toward Western cultural references. For example, LAION-5B includes 18 times more Western cultural artifacts than African or Asian ones. Additionally, 78% of its English-language image-text pairs come from North America and Europe, compared to just 6% from African or Asian domains. When models lack exposure to diverse cultural contexts, they struggle to accurately represent or interpret them. This imbalance directly leads to performance gaps in recognizing cultural concepts.
The disparities are quantifiable. Marginalized cultural elements score 30–44% lower in Component Inclusion Scores (CIS) compared to mainstream ones. For example, while mainstream flags achieve an 88% accuracy rate, marginalized flags lag at 49%, reflecting a 44% gap. Similarly, models recognize mainstream monuments with 88% accuracy but drop to 61% for marginalized ones. Even vehicles show a performance gap, with mainstream examples scoring 92% versus 73% for marginalized ones. Rene Kizilcec, Associate Professor at Cornell University, succinctly captures the issue:
"The words that are on the internet are not produced equally by all cultures around the world".
This problem isn't limited to image generation models - it extends to language models as well. In September 2024, Kizilcec and doctoral student Yan Tao tested five versions of ChatGPT using data from 107 countries in the Integrated Values Survey. They found that the models inherently reflected Protestant European and English-speaking values. By employing "cultural prompting" - instructing the AI to respond as someone from a specific country - they improved cultural alignment for 71% to 81% of the countries tested. While this method offers a temporary fix, it highlights the need for models to be designed with cultural diversity in mind from the outset.
The impact of these blind spots goes beyond technical inaccuracies. When AI systems embed Western values as universal norms, they inadvertently marginalize indigenous practices and non-Western knowledge systems. To address this, organizations must prioritize diverse datasets, include cultural experts in their development teams, and rigorously test their models across various cultural contexts. NAITIVE AI Consulting Agency, for example, emphasizes these principles by integrating diverse cultural data and expert insights into its AI solutions to tackle such biases effectively.
8. Stereotyping Bias in Output Generation
Stereotyping bias in AI outputs highlights how the training process can shape and reinforce visual representations, often in ways that misrepresent diversity and perpetuate harmful stereotypes.
For instance, when you ask an AI image generator for "a photo of a doctor", the result is often a White male, while prompts like "a nurse" frequently produce images of women. These patterns reflect long-standing biases embedded in the training data and design of these systems.
A 2024 study examining 8,000 images from platforms such as Midjourney, Stable Diffusion, and DALL·E 2 found troubling trends. Female representation ranged between 23% and 42%, well below the 46.8% benchmark for women in the workforce. Black individuals were represented in only 2% to 5% of images, compared to their 12.6% share of the population. In Stable Diffusion XL, males dominated 90% of images for prestigious roles like "Doctor" and "Professor".
These biases extend beyond gender and race representation. AI models often associate positive traits like "beautiful", "intelligent", and "winner" with White individuals, while linking negative terms such as "terrorist" and "criminal" with Middle Eastern and Black individuals. A 2022 study by Pratyusha Ria Kalluri at Stanford revealed stark examples: a prompt for "a photo of an American man and his house" produced an image of a pale-skinned man with a colonial-style home, while "a photo of an African man and his fancy house" generated a dark-skinned man in front of a modest mud house.
The consequences of these biases go beyond the digital realm. Research has shown that exposure to biased AI-generated images can actually heighten racial and gender biases in human viewers. For example, when Middle Eastern men are consistently depicted in stereotypical attire or women are shown as perpetually young and smiling while men appear older and more neutral, these portrayals not only reflect societal stereotypes - they amplify them.
To tackle these issues, organizations developing AI models must take proactive steps. Implementing fairness-aware training techniques, conducting regular red teaming exercises, and ensuring human oversight can help catch and address biased outputs before they reach users. NAITIVE AI Consulting Agency, for example, integrates diverse training data and uses adversarial debiasing methods to help businesses avoid reinforcing harmful stereotypes in their AI systems.
9. Prejudice Bias from Pattern Assumptions
Prejudice bias takes AI bias a step further by distorting outcomes through overgeneralized pattern assumptions. This happens when AI models latch onto broad group traits - like race, gender, or age - rather than evaluating individuals based on their actual qualifications or needs. The result? Amplified disparities and skewed real-world outcomes.
Studies bring this issue into sharp focus. For instance, a loan default prediction model trained on historical data might automatically label younger applicants as high-risk, simply because past data showed higher default rates in that age group. And it's not just hypothetical. In March 2024, Nature published research showing that large language models, including GPT-4, exhibited linguistic bias. These models recommended the death penalty more frequently for defendants using African American English compared to those using Standardized American English. Another study, conducted in June 2025 by Cedars-Sinai, revealed that language models provided less effective psychiatric treatment recommendations for African American patients when their race was indicated, with the NewMes-15 model showing the starkest disparities.
Unlike proxy bias, which arises from feature redundancy, prejudice bias stems from these sweeping assumptions. Even if sensitive data like race or gender is removed, models can still infer these traits through proxy variables. A striking example comes from healthcare, where an algorithm reduced the number of Black patients identified for extra care by over 50% because it used healthcare spending as a stand-in for medical need.
"Harmful biases are an inevitable consequence arising from the design of any large language model as LLMs are currently formulated."
- Philip Resnik, Professor, University of Maryland
To address this, organizations building AI systems must actively root out proxy features and ensure decisions are based on relevant, unbiased factors. Techniques like adversarial debiasing offer a way forward, helping models focus on meaningful data rather than harmful generalizations. Companies like NAITIVE AI Consulting Agency specialize in auditing datasets for hidden proxies and applying these debiasing strategies effectively.
10. Long-Term Societal Impacts of Unmitigated Bias
When AI bias goes unchecked, it creates a dangerous cycle. Biased models produce unfair outcomes for certain groups, and these outcomes often feed back into the data used to train future systems. This creates a loop where discrimination intensifies with every iteration. Ondrej Bohdal, a researcher at the University of Edinburgh, explains:
"biased models can lead to more negative real-world outcomes for certain groups, which may then become more prevalent by deploying new AI models trained on increasingly biased data, resulting in a feedback loop".
The issue goes beyond technical flaws - it has serious societal consequences. Persistent bias systematically marginalizes vulnerable groups in areas like housing, employment, and law enforcement. For example, in 2019, researchers and the U.S. Department of Housing and Urban Development found that Facebook's ad-delivery algorithms were excluding users from housing and job ads based on race, religion, and gender. That same year, studies showed Amazon's Rekognition software struggled significantly with identifying darker-skinned women compared to lighter-skinned men.
The immediate fallout is a loss of trust. Stakeholders lose confidence in AI systems when discriminatory outcomes emerge. Ted Kwartler, Vice President of Trusted AI at DataRobot, emphasizes:
"Finding bias in models is fine, as long as it's before production. By the time you're in production, you're in trouble".
Despite this, many organizations remain overly optimistic. A 2021 survey revealed that about 75% of companies believed their models were fair, even though evidence of bias was widespread. This gap between perception and reality creates a blind spot, allowing biased systems to proliferate unchecked.
Unchecked bias doesn't just harm individuals - it poses systemic risks. As AI becomes more self-directed and capable of influencing real-world decisions, its discriminatory effects can spread quietly and deeply before anyone notices. For developers, consumers, and policymakers with varying levels of expertise, this creates a perfect storm where bias compounds across the AI pipeline. Ondrej Bohdal warns:
"if the issues persist, they could be reinforced by interactions with other risks and have severe implications on society in the form of social unrest".
To break this cycle, proactive measures are essential. These include auditing AI systems with experts, carefully labeling data, and conducting risk assessments in advance . Organizations like NAITIVE AI Consulting Agency specialize in these efforts, helping businesses uncover hidden biases and build frameworks that prioritize fairness from the outset. Without deliberate intervention, the long-term consequences could include worsening inequality and a breakdown in social trust.
Comparison Table
Bias Comparison Table
Below is a summary table that highlights various types of biases, their origins, and their real-world effects. It builds on the examples discussed earlier to provide a clearer understanding of how these biases manifest.
| Bias Type | Primary Source | How It Happens | Impact Example |
|---|---|---|---|
| Representation Bias | Data Sampling | Training data lacks sufficient examples from certain demographic groups. | In the 2018 "Gender Shades" study, facial recognition systems had error rates of 0.8% for light-skinned men but soared to 34.7% for dark-skinned women. |
| Historical Bias | Societal Factors | Data reflects past inequities and societal prejudices. | Word embeddings trained on historical texts associate "nurse" with women and "engineer" with men, reinforcing stereotypes. |
| Measurement Bias | Data Collection | Relies on flawed proxies or inconsistent methods for gathering information. | Predictive policing systems using arrest rates as a proxy for crime penalize over-policed communities instead of measuring actual criminal activity. |
| Algorithmic Bias | Optimization Logic | Models amplify disparities while aiming to maximize overall accuracy. | Optimization logic can reduce performance for minority groups when prioritizing overall metrics. |
| Proxy Bias | Feature Engineering | Neutral-seeming variables strongly linked to protected attributes act as proxies. | A 2019 analysis of a healthcare algorithm showed it underestimated Black patients' needs by using spending as a proxy for health, misallocating care. |
| Label Bias | Human Factors | Annotators' subjective beliefs and backgrounds influence data tagging. | Sentiment analysis models miss subtle language nuances because labelers only marked extreme examples during training. |
| Confirmation Bias | Human Factors | Developers favor patterns that align with their beliefs. | Homogeneous teams may overlook biases in training data, leading models to perpetuate discrimination in decisions like hiring or credit. |
| Framing Effect Bias | Human Factors | Problem definitions by stakeholders can lead to discriminatory outcomes. | Credit card companies defining "creditworthiness" to maximize profits may exclude minority applicants systematically. |
Biases in data often result in performance disparities, while those driven by human or algorithmic factors can lead to systemic discrimination. Harini Suresh and John Guttag from MIT emphasize:
"Historical bias arises even if data is perfectly measured and sampled, if the world as it is or was leads to a model that produces harmful outcomes".
Conclusion
After exploring the roots of bias in AI and its societal ripple effects, the next step is ensuring ongoing mitigation and vigilant oversight.
Bias in tailored AI models goes beyond a technical issue - it's a societal obligation. Left unchecked, biases can amplify historical inequalities, erode trust, and even transform into what Cathy O’Neil famously described as "weapons of math destruction" - opaque, scalable models that exacerbate social harm. Industry experts agree: detecting bias during development is far easier than dealing with its consequences after deployment.
The way forward demands diverse teams, robust testing, and continuous oversight. A systematic review of 48 healthcare AI studies revealed that half were at high risk of bias due to unbalanced datasets or flawed designs. This highlights the necessity of embedding bias mitigation throughout the AI lifecycle - from the initial design phase to post-deployment monitoring. Preeti Shivpuri, Trustworthy AI Leader at Deloitte Canada, puts it succinctly:
"Engaging consultations with different stakeholders and gathering diverse perspectives to challenge the status quo can be critical in addressing inherent biases within data".
Building trustworthy AI hinges on both technical expertise and a steadfast commitment to fairness. This involves assembling cross-disciplinary teams, employing human-in-the-loop systems, and setting up automated checks to monitor performance across diverse demographic groups. Companies that embrace these practices not only sidestep ethical pitfalls but also create AI systems that serve all users equitably.
These principles are central to NAITIVE AI Consulting Agency's methodology. NAITIVE focuses on integrating bias mitigation from the ground up. By offering comprehensive consulting services, they help businesses adopt fairness-focused design, rigorously test models across varied populations, and implement ongoing monitoring systems. Their approach ensures AI systems not only achieve technical excellence but also deliver fair and measurable outcomes while adhering to ethical standards.
While many leaders express confidence in the fairness of their AI models - about 75% believe their systems are reliable - evidence suggests that bias often remains hidden until long after deployment. Tackling this issue head-on is critical to building AI systems that are not only effective but also equitable and trustworthy.
FAQs
What’s the difference between representation bias and historical bias?
Bias in AI can take different forms, and two key types are representation bias and historical bias.
- Representation bias happens when the data used to train AI reflects imbalances or disparities in society. For instance, if certain groups are underrepresented in the data, the AI's outcomes may end up skewed or unfair.
- Historical bias stems from pre-existing biases in past data. This type of bias often reinforces inequalities or stereotypes already present in society, perpetuating them through AI systems.
Both forms of bias can undermine the fairness and accuracy of AI, leading to unintended consequences and reinforcing societal inequities.
How can I detect proxy bias if my model doesn’t use race or gender?
Detecting proxy bias without directly relying on race or gender involves identifying features that indirectly serve as stand-ins for these protected attributes. To do this, you can apply methods such as causal explanations, structural bias analysis, or conducting audits for indirect influence. These techniques are designed to uncover hidden patterns and dependencies that might not be immediately obvious.
For instance, certain seemingly neutral features might still mirror or perpetuate societal inequalities. By scrutinizing these relationships, you can better understand how biases are embedded within the data or decision-making processes, even when race or gender is not explicitly used.
What should I monitor after deployment to prevent bias feedback loops?
To avoid bias feedback loops after deployment, it's crucial to keep a close eye on the AI system's performance in real-time. This means consistently checking the quality of data being fed into the system and ensuring it meets fairness standards. Pay attention to patterns that could amplify biases over time. Regularly reviewing the system's outputs and analyzing how users interact with it can help spot and fix any problems before they grow.



