Real-Time Speech-to-Text for Voice AI Agents
A practical guide to low-latency real-time STT for voice AI agents—vendor comparisons, WebRTC/WebSocket integration, VAD tuning, and deployment best practices.

Real-time speech-to-text (STT) technology is the backbone of modern voice AI systems. It converts spoken words into text almost instantly, enabling applications like live captions, automated meeting transcriptions, and voice commands. With latencies as low as 300 milliseconds, STT ensures smooth interactions, especially in customer service, healthcare, and accessibility tools. Key features include speaker identification, word-level timestamps, and compatibility with various languages and accents.
Top STT APIs like AssemblyAI, Deepgram, Soniox, and OpenAI offer diverse options based on latency, accuracy, and cost. Businesses can choose solutions tailored to their needs, such as medical transcription or multilingual support. Integration involves using protocols like WebRTC or WebSocket, alongside features like Voice Activity Detection (VAD) and session management for uninterrupted performance.
For enterprises, real-time STT enhances productivity by enabling voice agents to handle tasks efficiently. These systems operate with sub-second responses, ensuring seamless communication and compliance in industries like finance, healthcare, and customer support. To succeed, businesses must prioritize latency, accuracy, and scalability when selecting and integrating STT solutions.
The Most Accurate Speech-to-text APIs in 2025
Technologies and Tools for Real-Time Speech-to-Text
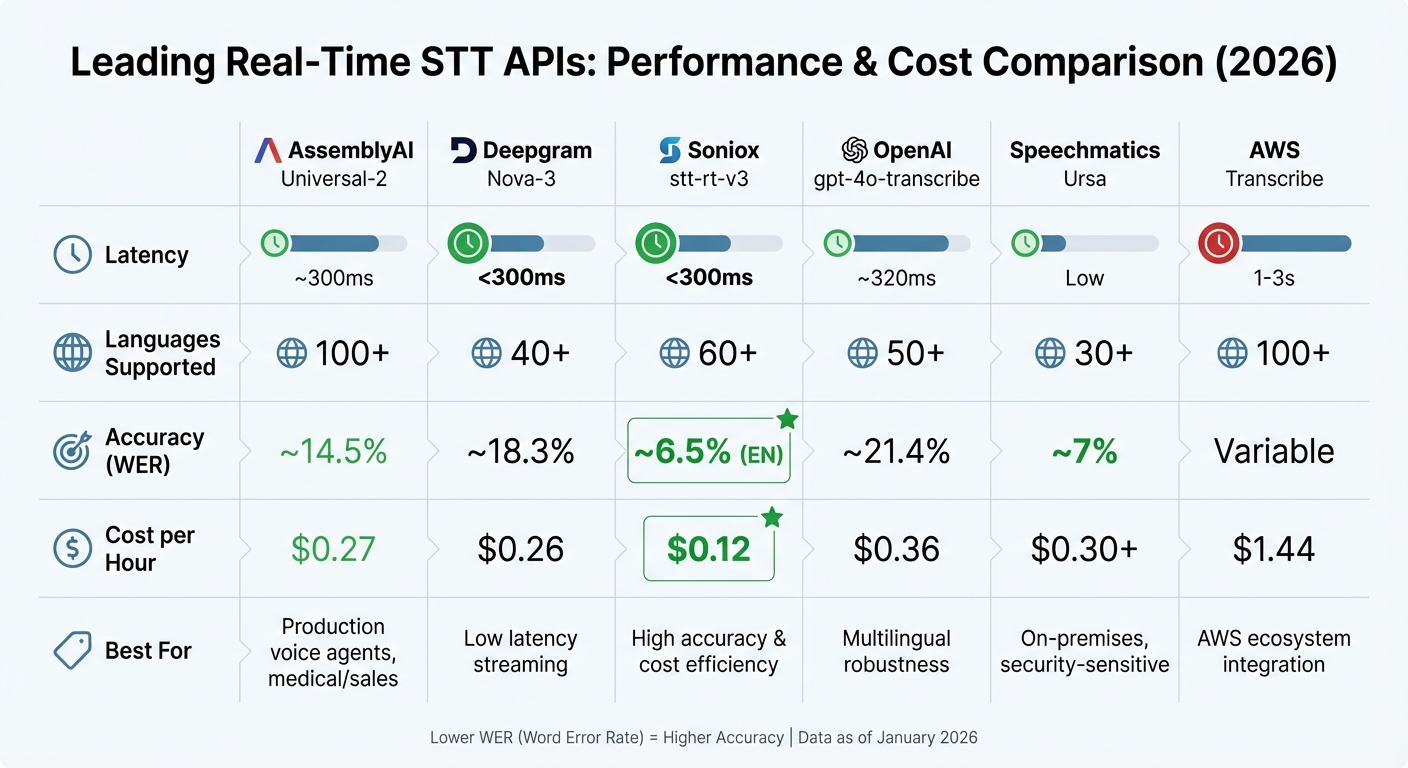
Real-Time STT API Comparison: Latency, Accuracy, Cost & Languages
Modern speech-to-text (STT) systems rely on advanced transformer-based deep learning models, trained on vast datasets comprising millions of hours of audio. These systems are designed to handle a variety of accents and languages, streaming audio via persistent WebSocket connections. By using preprocessing techniques to minimize noise and leveraging language models, they can predict contextually appropriate words with impressive accuracy.
The STT industry is projected to reach a massive US$73.00 billion by 2031. When evaluating vendors, businesses prioritize cost (64%), quality/performance (58%), and accuracy (47%). Interestingly, systems with 95% accuracy and 300ms latency often outperform those boasting 98% accuracy but with a 2-second delay. Below, we’ll explore some of the top APIs in this space and their performance metrics to help guide your selection.
Leading Real-Time STT APIs
The following APIs meet demanding technical requirements and support a wide range of enterprise applications:
- AssemblyAI Universal-2: Offers ~300ms latency at $0.27 per hour, making it a strong choice for applications like medical transcription and sales.
- Deepgram Nova-3: Delivers latency under 300ms across 40+ languages, priced at $0.26 per hour.
- Soniox stt-rt-v3: Known for its exceptional accuracy, it achieves a 6.5% word error rate (WER) for English and costs just $0.12 per hour.
"It just gets the words right - any language, any accent, any context. That's what accuracy is supposed to look like."
- Tony Wang, Cofounder & Chief Revenue Officer at Agora
- OpenAI gpt-4o-transcribe: Supports transcription in over 50 languages with low latency (~320ms) at $0.36 per hour.
- Speechmatics Ursa: Tailored for security-sensitive industries, it offers on-premises deployment starting at $0.30+ per hour.
- AWS Transcribe: A cost-effective option within the AWS ecosystem, starting at $0.024 per minute (~$1.44 per hour), though its latency ranges from 1 to 3 seconds.
As of January 2026, companies like CallSource and Bland AI have been leveraging sub-500ms latency STT solutions to enhance customer interactions. Some organizations are even adopting multi-model strategies, running multiple STT models simultaneously and using large language models to reconcile differences. This approach can reduce transcription errors by up to 40%.
Comparing Accuracy and Latency Across Technologies
| Provider | Latency | Languages | Accuracy (WER) | Cost per Hour | Best For |
|---|---|---|---|---|---|
| AssemblyAI Universal-2 | ~300ms | 100+ | ~14.5% | $0.27 | Production voice agents, medical/sales |
| Deepgram Nova-3 | <300ms | 40+ | ~18.3% | $0.26 | Low latency streaming |
| Soniox stt-rt-v3 | <300ms | 60+ | ~6.5% (EN) | $0.12 | High accuracy and cost efficiency |
| OpenAI gpt-4o-transcribe | ~320ms | 50+ | ~21.4% | $0.36 | Multilingual robustness |
| Speechmatics Ursa | Low | 30+ | ~7% | $0.30+ | On-premises, security-sensitive deployments |
| AWS Transcribe | 1–3s | 100+ | Variable | $1.44 | AWS ecosystem integration |
These metrics provide a clear picture of how different tools perform, helping businesses choose the right fit for their needs.
How to Choose a Real-Time STT Tool
When selecting an STT tool, it’s essential to test it with real-world data that includes noise, varied accents, and any specialized terminology your business might use. For interactive voice agents, prioritize solutions that maintain latency under 500ms to ensure smooth, natural conversations. On the other hand, if transcripts are reviewed later, a slight increase in latency can be acceptable if it improves accuracy.
If your business operates in a specialized field, look for tools that offer domain-specific features like custom vocabulary uploads. For example, in March 2025, Deepgram introduced Nova-3 Medical, achieving a median WER of 3.45% for healthcare-related terms.
"Soniox's ability to accurately transcribe complex medical terminology means our physician-customers spend significantly less time editing."
- Max Malyk, Vice President at DeliverHealth
Finally, evaluate the total cost of ownership beyond the base price. Hidden expenses like data transfer fees, storage, and the engineering resources required for maintenance can add up. Features like speaker diarization, endpoint detection, and multi-language support should also be considered, as they can significantly influence implementation complexity and overall value.
How to Integrate Real-Time STT into Voice AI Agents
This section dives into how to seamlessly incorporate real-time speech-to-text (STT) into voice AI agents. The process involves selecting the right transport protocol, managing sessions effectively, and ensuring low-latency audio streaming.
Setting Up WebRTC or WebSocket Connections
The first step is deciding between WebRTC and WebSocket connections. For browser and mobile platforms, WebRTC is the preferred choice. It simplifies audio recording and playback using RTCPeerConnection and offers more stable client-side performance compared to WebSockets.
"When connecting to a Realtime model from the client (like a web browser or mobile device), we recommend using WebRTC rather than WebSockets for more consistent performance." - OpenAI
For server-side applications or telephony systems, WebSocket connections are a better fit. Unlike WebRTC, WebSockets require manual handling of raw PCM16 audio data, meaning you’ll need to manage audio chunking yourself. Transmitting audio in 20–40 ms PCM chunks ensures efficient bandwidth use and responsiveness.
To secure your connections, generate temporary tokens server-side instead of exposing API keys directly. For instance, OpenAI provides a /v1/realtime/client_secrets endpoint for ephemeral tokens, while ElevenLabs offers single-use tokens that expire after 15 minutes.
When using WebRTC, the connection process involves exchanging Session Description Protocol (SDP) data between the client and API to establish the peer connection. Once connected, configure the session with details like the model (e.g., gpt-realtime), voice parameters, and audio formats such as pcm16.
Managing Sessions and Voice Activity Detection
Voice Activity Detection (VAD) plays a crucial role in identifying when speech begins and ends, directly affecting the flow of conversations. Adjust VAD settings, such as "eagerness" and silence thresholds, to fine-tune the agent’s responsiveness. In noisy environments, these settings may need extra calibration to avoid premature interruptions or delayed responses.
For natural conversations, barge-in handling is a must. Enable the interruptResponse feature and monitor audio_interrupted events to stop audio playback instantly when a user speaks over the agent. With WebSocket setups, you’ll need to manually stop the local audio buffer when such events occur. Pre-buffering about 100 ms of text-to-speech audio before playback can help eliminate clipping issues.
Keep connections stable throughout the session by implementing heartbeats with intervals of 5 seconds or less to quickly detect disconnects. Use history_updated events to track live conversation states, enabling features like real-time transcription or action triggers based on dialogue progress. These session management techniques lay the foundation for advanced capabilities like tool execution and agent handoffs.
Adding Tool Calling and Agent Handoffs
Once session management is in place, voice agents can perform tasks like executing functions or transitioning seamlessly between specialized agents. Define functions using a tool() wrapper, which can run locally in the browser or through backend HTTP requests for sensitive operations.
For tasks requiring user consent, enable the needsApproval: true flag to trigger a tool_approval_requested event. This ensures the user confirms before the agent proceeds. To maintain a smooth experience, agents can announce upcoming actions or use filler phrases to prevent awkward silences during processing.
Agent handoffs allow transitions between agents specialized in different areas, such as switching from billing inquiries to technical support. Use a handoffs array to manage these transitions while preserving the conversation’s context and history. For complex reasoning tasks, delegate them to backend models, ensuring the full conversation history is passed along for continuity.
Finally, implement outputGuardrails to review transcripts every 100 characters, halting responses if any rules are violated, such as mentioning restricted terms. This ensures your voice agents maintain appropriate behavior, even during real-time interactions.
Improving Accuracy and Performance in Real-Time STT Systems
Once your voice AI agent is up and running, it’s essential to ensure it can handle challenges like noise, accents, and interruptions effectively. Fine-tuning transcription accuracy is key to maintaining the smooth interactions that users expect from voice AI. Below are strategies to help refine and adapt these systems to meet various operational demands.
Handling Noise, Accents, and Interruptions
Good audio quality is the foundation of accurate transcription. Aim to record audio at 16,000 Hz or higher, and use lossless codecs like FLAC or LINEAR16 for the best results. If you’re working with limited bandwidth, consider using AMR_WB or OGG_OPUS instead of lossy codecs like MP3. Position microphones close to the speaker to minimize background noise and echoes.
Turn off local noise reduction or Automatic Gain Control (AGC) before sending audio to the API. Today’s speech-to-text (STT) engines are designed to handle raw audio, even if it’s noisy, and pre-processing can sometimes interfere with recognition accuracy. Instead, use built-in features like "near-field" for close-range microphones or "far-field" for room-based devices.
To improve recognition of specialized terms, incorporate industry-specific vocabulary through phrase sets or word hints. Adjust Voice Activity Detection (VAD) parameters - such as threshold levels, prefix padding, and silence duration - to strike the right balance between responsiveness and error reduction. For general voice agents, a silence detection period of around 400 ms works well, while live captioning with multiple speakers may require extending this to roughly 560 ms.
For phone-based audio, use telephony models designed for native 8,000 Hz audio. If higher-quality transcription is needed, select models optimized for wider frequency ranges.
Supporting Multiple Languages and Adaptive Responses
To serve a global audience, enable the system to detect and switch between languages automatically by using alternativeLanguageCodes. This allows the system to identify the correct language at the start of a conversation.
"Explicitly adding language information to multilingual ASR models during training has been shown to improve their performance." - Amazon Science
Keep in mind that language models can sometimes misinterpret incorrect language labels. Introducing a small amount of label noise during training can help make the system more resilient to unexpected language switches. For complex conversational flows, state-based prompting - where conversation states are encoded in JSON within the system prompt - can provide clear instructions and smooth transitions.
Advanced speech systems can also analyze audio to detect emotions and intent, enabling agents to adapt their responses based on both tone and words. This capability enhances the agent’s ability to engage meaningfully with users.
While refining language handling is important, consistent monitoring of performance metrics is equally critical to ensure the system remains accurate and responsive.
Tracking Performance Metrics
Confidence scores (ranging from 0.0 to 1.0) and log probabilities are useful indicators of transcription reliability. Monitoring these metrics can help determine when to trigger agent responses.
Latency is another critical factor. Real-time WebSocket connections typically achieve latencies between 300 ms and 800 ms. Using a frame size of around 100 ms strikes a good balance between processing efficiency and timely responses.
For multi-speaker scenarios, implement speaker diarization to correctly attribute spoken content to individual speakers. If multiple speakers are being recorded, use separate audio channels for each to prevent overlapping. Additionally, use is_final=true flags to mark completed utterances, and half-close streams before starting new ones to ensure no audio data is lost during fast-paced exchanges.
NAITIVE AI Consulting for Custom Real-Time STT Solutions
NAITIVE AI Consulting Agency offers tailored, enterprise-level solutions for real-time speech-to-text (STT) integrations, building on the strategies highlighted earlier.
Custom Real-Time STT Integration for Businesses
NAITIVE AI Consulting Agency specializes in creating end-to-end speech-to-text systems that meet unique enterprise needs. Whether your business requires traditional STT-LLM-TTS pipelines for precise control or direct Speech-to-Speech setups for reduced latency and nuanced emotional responses, NAITIVE has you covered.
The process begins with selecting the most suitable STT provider for your specific use case. For example, healthcare applications needing HIPAA compliance benefit from specialized models like Deepgram's Nova-2 Medical. For global businesses, solutions may include Cartesia's Ink Whisper, which supports 98 languages, or Deepgram's Nova-2, tailored for conversational and phone-based interactions across 33 languages. The team evaluates providers based on essential factors like accuracy, speed, language coverage, and regulatory compliance.
Each custom solution also features advanced Voice Activity Detection, fine-tuned to match your workflows. Real-time safety measures are implemented, scanning transcripts every 100 characters to flag compliance violations or banned content. For businesses with complex workflows, NAITIVE integrates multi-agent orchestration to enable seamless conversation transfers while maintaining context.
These solutions are deployed on Kubernetes, offering integrated monitoring, cost management, and detailed observability through transcripts and traces. NAITIVE ensures reliable, low-latency connectivity by customizing integrations, whether through WebRTC for browser-based applications or SIP/VPC setups for telephony using providers like Twilio or Telnyx.
Enterprise Phone and Autonomous Voice Agents
Beyond STT integration, NAITIVE delivers autonomous voice agents that redefine how businesses communicate.
These voice agents aren’t your typical chatbots - they act as virtual employees capable of managing multi-step conversations and handling tasks like appointment scheduling or refund inquiries. They adapt their responses dynamically based on real-time context, offering a human-like interaction experience.
For call centers and customer support, these solutions integrate seamlessly with existing telephony systems, managing thousands of concurrent conversations while maintaining data privacy and compliance. Accurate audit trails ensure regulatory adherence. The agents analyze live conversations for tone, sentiment, and compliance issues, providing real-time prompts to human agents when necessary. In healthcare, virtual assistants triage patient inquiries using HIPAA-compliant systems equipped to recognize clinical terminology. In financial services, they streamline processes like KYC verification, automated onboarding, and investment-related Q&A, all while ensuring secure encryption and compliance.
To keep interactions natural, every component in the voice pipeline - STT, LLM, and TTS - processes data in under one second. NAITIVE achieves this through GPU-accelerated inference, optimized streaming infrastructure, and efficient interruption handling. For instance, when a user interrupts the agent, the system immediately triggers audio_interrupted events to halt playback, maintaining the flow of conversation. This high-performance setup ensures that voice AI agents deliver real-time, adaptive interactions, exceeding enterprise expectations. These agents operate 24/7, offering unmatched responsiveness and flexibility for transforming business operations.
Conclusion
Real-time speech-to-text technology forms the backbone of modern voice AI systems, enabling lightning-fast responses that keep users engaged. In fact, every millisecond matters - studies show that customers are 40% more likely to hang up if a voice agent takes longer than one second to reply. That’s why achieving ultra-low latency, typically between 300–800 milliseconds, is critical for maintaining a smooth and engaging experience.
Successful voice AI implementations require meticulous attention to detail. From picking the best speech-to-text (STT) provider to ensuring robust fail-safes and real-time monitoring, every piece of the puzzle plays a vital role in delivering reliable performance.
"Silence is death. If an API hangs for 5 seconds, the user thinks the call dropped." - Shekhar Gulati, Developer
Navigating these complexities demands specialized expertise. Whether it’s ensuring HIPAA compliance for medical transcription, supporting multiple languages for global operations, or enabling autonomous agents to perform tasks during live calls, every decision - like selecting between WebRTC and WebSocket transports or fine-tuning Voice Activity Detection - can significantly affect performance and reliability.
NAITIVE AI Consulting Agency specializes in turning these advanced STT techniques into fully customized, production-ready voice AI solutions. Instead of offering generic chatbots, NAITIVE delivers tailored pipelines - integrating STT, large language models (LLMs), and text-to-speech (TTS) - or direct Speech-to-Speech solutions designed to meet your specific latency and workflow needs. Their team manages everything, from choosing the right STT provider for your industry to deploying Kubernetes-based infrastructure with built-in monitoring and cost control.
Empower your business with voice AI capable of handling thousands of simultaneous conversations, maintaining context effortlessly, and responding in under a second. Visit naitive.cloud to explore how real-time STT solutions can enhance efficiency and elevate customer engagement.
FAQs
What should I consider when selecting a real-time speech-to-text (STT) API for my business?
When selecting a real-time speech-to-text (STT) API, start by focusing on latency and accuracy. If you're working on tasks like live captions or instant command recognition, look for APIs that deliver sub-second latency and maintain high accuracy, even in noisy settings. For less urgent needs, such as voicemail transcription, a slight delay might be acceptable.
You’ll also want to consider language support, pricing, and data privacy. Many APIs charge based on audio usage, so calculate costs against your expected needs. For instance, handling 10 hours of audio daily at $0.006 per minute would amount to about $4.32 per day. If safeguarding sensitive data is critical, explore options that offer on-premise hosting to retain full control over recordings.
Lastly, examine the integration process. Opt for APIs with straightforward documentation, SDKs in your preferred programming languages, and advanced features like custom vocabularies or model fine-tuning. If you need expert advice, NAITIVE AI Consulting Agency can assist in finding the right solution, conducting performance evaluations, and managing deployment to ensure your voice AI systems run smoothly and effectively.
What should I consider when adding speech-to-text to a voice AI agent?
When adding speech-to-text (STT) capabilities to a voice AI agent, there are three key areas to focus on: model selection, latency, and system integration.
Model selection involves choosing the right tool for your needs. Open-source models like Whisper and Wav2Vec 2.0 offer flexibility and control but might require more technical setup. On the other hand, cloud-based APIs deliver excellent accuracy and low latency but come with ongoing costs. Your choice should consider factors like the target language, audio quality, and your budget constraints.
To ensure smooth real-time performance, keeping latency low is critical. This can be achieved by processing audio in small chunks, typically 10–20 milliseconds, and optimizing for quick responses. Don't overlook audio preprocessing - noise suppression and consistent sampling rates (like 16 kHz PCM 16-bit) are crucial, especially in environments with background noise.
Lastly, think about integration complexity and scalability. Tools like SDKs or APIs can simplify development and make scaling easier as your user base grows. Fine-tuning models for specific vocabulary or deploying on edge devices can enhance both accuracy and efficiency. For expert guidance, NAITIVE AI Consulting Agency can help you navigate these choices and implement a secure, high-performance solution tailored to your business.
How can I enhance speech-to-text accuracy in noisy environments?
To boost speech-to-text (STT) accuracy in noisy environments, start by using a high-quality external microphone placed about 6–12 inches from the speaker’s mouth. This setup ensures a cleaner audio signal by minimizing interference. Whenever possible, record audio in lossless formats like WAV instead of compressed ones, and aim for a sampling rate of at least 16 kHz to capture more audio detail. Leveraging AI-driven noise reduction tools can also help filter out background sounds like traffic or nearby conversations.
Good speaking habits play a big role too. Speak clearly, maintain a steady pace, avoid mumbling, and keep your volume consistent. For industries with specialized terminology, fine-tuning the STT system with domain-specific vocabularies can significantly cut down on errors. If you’re looking for a tailored approach, NAITIVE AI Consulting Agency offers solutions designed to optimize voice AI systems, ensuring dependable performance even in noisy or complex settings.
