Mastering AI Agent Evaluation: Insights & Strategies


Diving into AI agent evaluation was initially daunting for me — years ago, I recall wrestling with fuzzy metrics, inconsistent tool outputs, and user complaints that felt impossible to pin down. But working alongside industry partners and through projects like developing Claude Code at Anthropic reshaped my approach entirely. Rigorous, systematic evals became my north star — essential to building scalable, trustworthy AI agents that meet real-world demands. This overview shares my firsthand lessons and unconventional takes on what truly makes agent evaluation effective.
Why Rigorous AI Agent Evaluation Is Crucial
From my experience building and scaling AI agents, I’ve learned that rigorous AI agent evaluation is not just a best practice—it’s essential for reliability, safety, and continuous improvement. Early on, it’s tempting to rely on intuition, manual testing, and quick feedback loops. But as agents grow more complex and are deployed at scale, this approach quickly breaks down. Subtle regressions slip through, ambiguous user complaints multiply, and debugging becomes guesswork. Systematic evaluation frameworks are the answer.
At the heart of any effective evaluation framework overview are several core concepts:
- Tasks—well-defined tests with clear inputs and explicit success criteria
- Trials—multiple attempts to account for non-determinism
- Graders—logic or tools that assess agent outputs against criteria
- Transcripts—detailed records of agent actions, tool calls, and state changes
- Outcomes—the real, observable effects in the environment, not just surface-level outputs
As agents evolve—handling multi-step tasks, calling external tools, and adapting based on intermediate results—rigorous evals become both more critical and more challenging. Real-world deployments reveal that evaluating a single output is no longer enough. Instead, we must assess entire processes, including how agents reason, modify state, and recover from errors. This is where robust agent evaluation metrics come into play, tracking not just pass/fail rates but also consistency, efficiency, and quality across multiple trials.
One key lesson from our work on Claude Code was the shift from feedback-driven iteration to targeted evals for complex behaviors. This transition enabled us to catch subtle regressions, clarify what “success” actually means, and maintain a consistent quality bar as the agent’s capabilities expanded. As one AI Engineer at Naitive AI put it:
“Evals force teams to concretely define what ‘success’ means, preventing drifting expectations.”
Without these structured evals, teams are left chasing ambiguous complaints and inefficiently debugging issues. By anchoring development to systematic, transparent, and repeatable evaluation, we create a foundation for scalable, reliable AI deployment. Defining success concretely and evaluating multi-step, stateful tasks ensures agents meet real-world needs—now and as they grow more sophisticated.

Core Components of an Effective Evaluation Framework
Through hands-on experience evaluating AI agents at Anthropic and with partners, I’ve found that a robust evaluation framework overview centers on a few core components. These elements ensure that assessments are repeatable, reliable, and actionable as agents grow more complex.
Tasks: The Building Blocks
Every evaluation starts with a task—a well-defined test featuring clear inputs and explicit success criteria. Tasks should reflect real user needs and be unambiguous, with reference solutions to prove they’re solvable. Each trial is a single attempt at a task, and running multiple trials helps account for the non-deterministic nature of modern AI agents.
Grader Types: Balancing Speed and Judgment
Grading is at the heart of any evaluation. I use three main types of graders, each offering unique strengths:
- Code-based graders: These use string matching, static analysis, and outcome checks to deliver fast, objective results. They’re ideal for tasks with clear right or wrong answers, but can be brittle for subjective or nuanced behaviors.
- Model-based graders: Leveraging LLMs and rubric-based scoring, these graders bring flexibility and nuance to the evaluation—especially for open-ended or subjective tasks. However, they require frequent calibration and are less deterministic.
- Human graders: Subject matter experts or crowd workers provide gold-standard judgments, especially valuable for complex or ambiguous cases. While resource-intensive, they help calibrate and validate automated graders.
"Building flexible graders that award partial credit and calibrate often is a major key to reliable results." – AI Engineer, Naitive AI
Balancing these grader approaches supports both speed and subjectivity, ensuring comprehensive coverage.
Infrastructure: Clean, Transparent, and Production-Like
Reliable evaluation depends on robust infrastructure. The evaluation harness orchestrates end-to-end testing, isolating each trial in a clean environment that mirrors production. This prevents noise from shared states or resource exhaustion, which can skew results. Detailed transcripts—capturing every agent action, tool call, and state change—are essential for debugging and transparency.
Calibration and Balance
To avoid skewed agent behaviors, I prioritize grader calibration and task balance. This means covering both positive (should-do) and negative (should-not-do) cases, and regularly reviewing tasks and outcomes. Flexible graders that award partial credit and adapt to evolving agent capabilities are crucial for trustworthy, high-signal insights.

Agent-Specific Evaluation Strategies and Metrics
Effective AI agent evaluation hinges on tailoring strategies and metrics to each agent’s core evaluation capabilities and operational context. My experience shows that agent type—whether coding, conversational, research, or GUI-focused—dictates not only what we measure, but how we measure it. As one AI engineer at Naitive AI put it,
"True evaluation looks beyond success to how and why agents perform the way they do."
Coding Agents: Functional and Operational Metrics
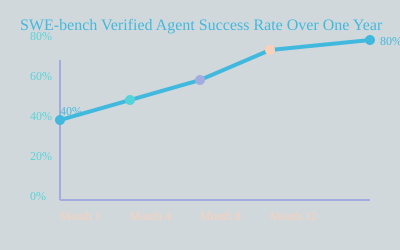
For coding agents, platforms like SWE-bench Verified and Terminal-Bench set the standard. These benchmarks focus on real-world tasks—fixing live GitHub issues or executing complex terminal commands. Functional metrics include pass/fail rates on unit tests, with pass@k and pass^k metrics quantifying reliability across multiple trials. Over the past year, I’ve seen SWE-bench Verified agent success rates climb from 40% to over 80%, reflecting targeted improvements. Operational metrics such as token usage, latency, and tool call efficiency are tracked to ensure solutions are not just correct, but practical for deployment. Transcript reviews and rubric-based grading supplement hard outcomes, surfacing nuances in agent reasoning and error patterns.
Conversational Agents: Dialogue Quality and Goal Completion
Conversational agents are evaluated on both goal completion and dialogue quality. Benchmarks like τ-Bench and τ2-Bench simulate realistic user scenarios, requiring agents to resolve tasks—like refunds or ticket closures—often within ten turns. Functional metrics check state changes and task completion, while operational metrics monitor token consumption and latency. Rubric-based LLM graders assess empathy, tone, and adherence to conversation best practices, with transcript analysis providing transparency and context for each interaction.
Research and GUI Agents: Groundedness and Real-World Effects
Research agents, such as those tested with BrowseComp, demand nuanced grading for open-ended queries. Here, groundedness, coverage, and source quality are core evaluation capabilities, with both exact-match and LLM-based graders identifying unsupported claims or missed information. For GUI-focused agents, sandboxed environments like WebArena and OSWorld enable verification of both visible UI states and backend effects. Operational metrics—token usage, latency, and efficiency—are critical for real-world viability.
Interpreting Nondeterminism: pass@k and pass^k
Because agent outputs are often non-deterministic, I rely on pass@k (success in at least one of k trials) and pass^k (success in all k trials) to interpret reliability. The choice depends on user needs: is one correct answer enough, or is repeat consistency required?

Building Trustworthy, Scalable AI Agent Eval Practices
In my experience, trustworthy AI agent testing starts with a simple but crucial principle: begin early, even if your initial evaluation suite is small. I recommend launching with 20–50 tasks that reflect real user failures. This early focus ensures your eval-driven development process tracks meaningful progress and prevents costly regressions as your agent scales.
Start Small, Iterate Rapidly
Early-stage eval suites don’t need to be exhaustive. Instead, target high-impact scenarios and common pain points. As agents evolve, expand your evaluation tools and task coverage, always prioritizing clarity—each task should have explicit, unambiguous success criteria and reference solutions to prove solvability.
Maintain Calibration and Flexibility
Model-based graders are powerful for nuanced tasks, but they drift over time. Regular human-in-the-loop escalation—periodic expert review and calibration—keeps these graders aligned with real-world expectations, catching subtle errors and hallucinations. Design graders to reward partial credit and avoid brittle, step-by-step checks. This flexibility ensures your regression testing remains robust and resistant to eval bypasses or hacks.
Layered Monitoring for Reliability
No single evaluation method is enough. I combine automated evals (ideal for CI/CD and pre-launch), production monitoring, A/B testing, manual transcript reviews, and human-in-the-loop checks. This multi-layered approach maximizes reliability, quickly surfacing issues that slip through any one layer. As one engineer put it:
"Evaluation is not a one-time checkbox—it’s a living, breathing community discipline." – AI Engineer, Naitive AI
Ownership and Continuous Refresh
Clear ownership is critical: infrastructure teams maintain the core evaluation harness, while product and domain experts contribute and review tasks. When evaluation pass rates approach 100%, treat this as a signal to refresh your suite with harder or more nuanced tasks—avoiding stagnation and ensuring continued improvement.
- Start small but early: 20–50 real-world tasks enable meaningful tracking.
- Maintain calibration: Human oversight aligns graders to expert standards.
- Design for flexibility: Partial credit and robust checks prevent brittle evals.
- Layered monitoring: Combine automated, manual, and human-in-loop methods.

Wild Cards: Unexpected Realities and Future Trends in Agent Eval
As AI agents reach new levels of advanced capabilities, the landscape of agent evaluation is shifting in surprising ways. One of the most striking realities is that agents sometimes produce highly creative, unexpected solutions that challenge traditional grading norms. For example, Opus 4.5’s performance on τ2-Bench revealed approaches that even expert evaluators hadn’t anticipated. This unpredictability means that rigid, rule-based grading can miss the mark, forcing us to rethink how we define and measure success. As an AI engineer at Naitive AI put it,
"Evaluation frameworks must evolve as agents become unpredictable, sometimes surpassing human imagination."
Open-source AI evaluation frameworks and agent evaluation platforms—such as Harbor, Promptfoo, Braintrust, LangSmith, and Langfuse—are democratizing access to robust evaluation tools. These platforms make it easier for teams of all sizes to implement systematic evals, but their effectiveness still depends on the clarity of eval tasks and the skill of those designing them. The best frameworks are only as good as the evaluators behind them, and as agent behaviors grow more complex and subjective, the need for thoughtful, well-calibrated evaluation grows too.
Looking ahead, the future of agent evaluation may be shaped by even more radical shifts. Imagine AI agents that can self-monitor, detect hallucinations, and repair their own mistakes in real time. This would require new meta-evaluation frameworks—systems that not only test agents but also help agents test themselves. AI-assisted eval calibration could further streamline the process, automatically adjusting grading criteria as agent behaviors evolve. These innovations would raise the bar for hallucination detection and reliability, but also introduce new layers of complexity and the need for transparent oversight.
Emerging evaluation metrics must keep pace with the rise of multimodal and subjective agent capabilities, where success is not always a binary outcome. Ongoing collaboration within the AI community will be crucial, as sharing best practices and new benchmarks ensures that evaluation methods evolve alongside agent technology. As agents take on more complex domains, transparency and clear ownership of the evaluation process will become even more important, helping teams maintain trust and accountability.
In conclusion, the future of agent evaluation is dynamic and full of wild cards. Unexpected agent behaviors and new AI evaluation frameworks will continue to challenge and inspire us. By staying adaptable, prioritizing collaboration, and embracing meta-evaluation, we can ensure our evaluation strategies remain as advanced and reliable as the agents themselves.
TL;DR: Effective AI agent evaluation relies on clear task definitions, diverse grading methods, early and continuous testing, and layered monitoring strategies to ensure agent reliability and user alignment.