Federated Learning for AI Agents: Privacy Design
Federated learning keeps sensitive data on-device, combining differential privacy, secure aggregation, and gradient techniques to build privacy-first AI.

Federated learning lets AI models improve without centralizing sensitive data. Instead of collecting raw data, devices like smartphones or hospital servers train models locally and share encrypted updates. This approach ensures compliance with privacy laws like GDPR and CCPA, reducing risks of data breaches while enabling smarter AI systems. Key techniques - like differential privacy and secure aggregation - protect individual data during training and transmission. Industries like healthcare, finance, and autonomous vehicles are already benefiting from this method, with improved accuracy and reduced data transfer. By addressing challenges like device diversity and connectivity issues, federated learning is shaping the future of privacy-first AI systems.
Federated Learning & Encrypted AI Agents: Secure Data & AI Made Simple
Core Components of a Federated Learning System
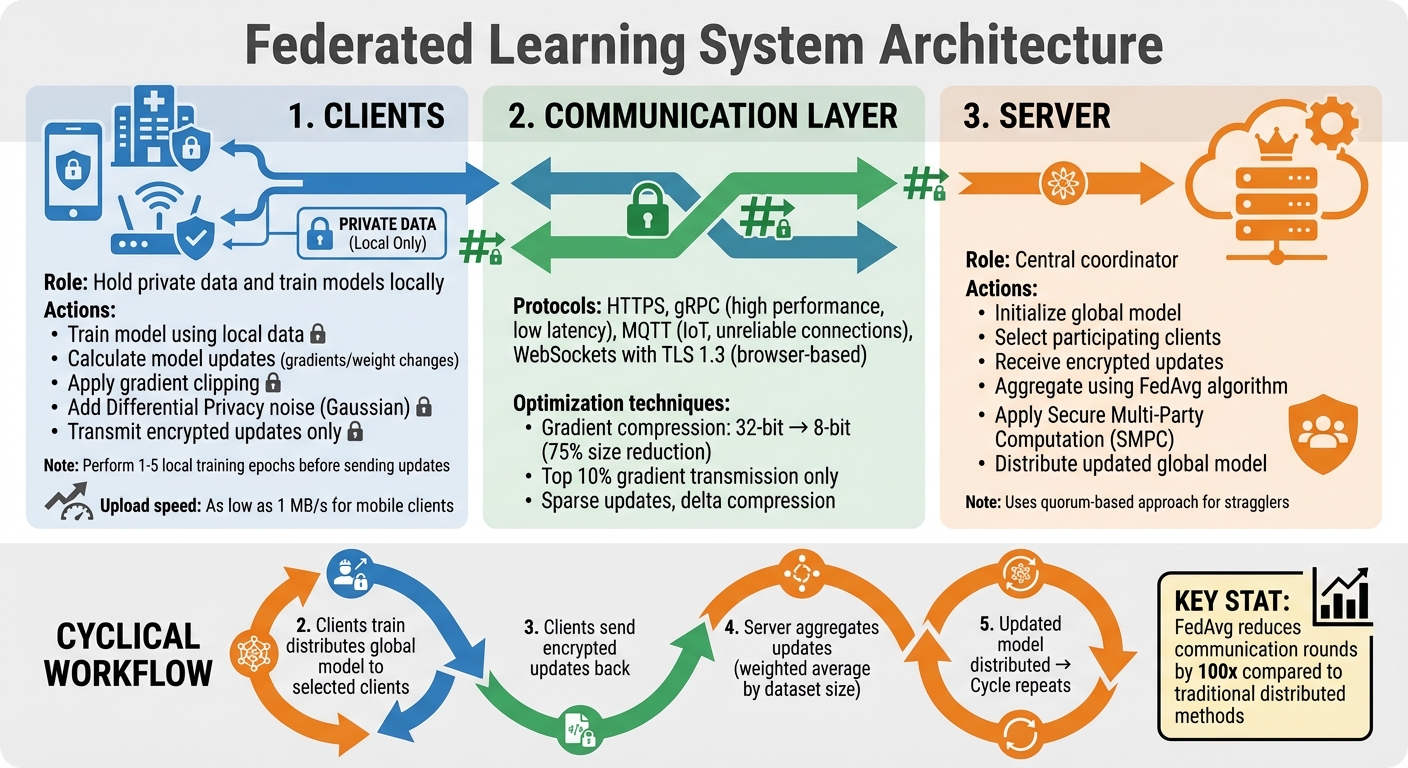
Federated Learning System Architecture and Workflow
Creating a federated learning system boils down to three key elements: the clients that handle local training, the server that oversees the entire process, and the communication layer that ties everything together.
Client and Server Roles
Clients are devices or systems that hold private data - think smartphones, hospital servers, or IoT sensors. Their role is to train the model locally using their own data, without ever sharing that data externally. Instead of sending raw data, clients calculate and transmit model updates (like gradients or weight changes) after training. To protect privacy, these updates undergo gradient clipping to limit sensitivity and are masked with Differential Privacy noise (e.g., Gaussian noise).
Servers act as the central coordinators. They kick off the process by initializing the global model, selecting which clients will participate in each round of training, and managing the workflow. When client updates come in, the server aggregates them - usually with the Federated Averaging (FedAvg) algorithm - to refine the global model. This updated model is then sent back to the clients for further training. To ensure privacy, servers can use Secure Multi-Party Computation (SMPC), which allows them to compute aggregate results without accessing individual client data.
As Nik Kale from Cisco Systems puts it, "Federated learning is a machine learning approach where model training occurs on decentralized data without centralizing the data itself".
A practical aspect of federated learning is that clients often perform several local training epochs before sending updates. This reduces how often communication rounds are needed - a crucial consideration since upload speeds for mobile clients can be as low as 1 MB/s. For example, FedAvg can slash communication rounds by a factor of 100 when training an LSTM language model compared to traditional distributed methods.
Communication Protocols and Data Flow
Secure communication protocols, such as HTTPS, gRPC, MQTT, or WebSockets with TLS 1.3, enable the exchange of models and updates. Each protocol has its strengths: gRPC delivers high performance and low latency, MQTT is ideal for IoT setups with unreliable connections, and WebSockets are well-suited for browser-based agents.
The workflow is cyclical: the server distributes the model, clients train locally, and updates are sent back for aggregation. To address "stragglers" - clients that are slow or offline - systems may use asynchronous updates or quorum-based approaches, moving forward once a subset of clients has responded.
Since bandwidth is a limiting factor, optimization techniques are critical. For instance, gradient compression (like converting 32-bit floats to 8-bit integers) can cut model size by 75% with minimal accuracy loss. Some systems go further, transmitting only the top 10% of gradient values to save bandwidth.
Federated Averaging Algorithm
The Federated Averaging (FedAvg) algorithm is the backbone of most federated learning systems. The process starts with the server initializing a global model and sending it to selected clients. These clients train the model locally for a few epochs (typically 1–5) and then return their updates. The server aggregates these updates into a weighted average, giving more weight to clients with larger datasets.
FedAvg stands out for its balance of simplicity and effectiveness. Research indicates that it performs on par with or better than more complex methods in tasks like medical imaging, with accuracy differences generally under 0.5%. It works well even when only 10% of clients participate in each round. For most applications, a learning rate between 0.001 and 0.01 is recommended, along with gradual learning rate decay to ensure convergence, especially when dealing with diverse data distributions.
As EmergentMind highlights, "FedAvg's simplicity and effectiveness, even under heterogeneous data distributions and partial client participation, have made it the de facto baseline for practical and theoretical study in FL".
Privacy-Preserving Mechanisms
Federated learning relies on a strong set of defenses to ensure privacy at every stage. Three key mechanisms work together to achieve this: Differential Privacy, which uses mathematical techniques to protect individual data contributions; Secure Aggregation, which keeps client updates confidential during transmission; and specific methods to counter model inversion attacks, which aim to reconstruct private data. Together, these mechanisms create a multi-layered defense system essential for ethical AI practices. Organizations looking to implement these frameworks often partner with specialized AI consulting agencies to ensure robust privacy design.
Differential Privacy
Differential Privacy (DP) is a mathematical approach that ensures adding or removing a single individual's data doesn't significantly affect the global model's behavior. This is achieved through two main techniques: clipping gradients to limit any single client's influence and adding noise (commonly Gaussian or Laplace) to obscure individual contributions.
A critical element of DP is privacy budgeting, which involves managing parameters like epsilon (ε) and delta (δ). For enterprise use, ε typically ranges from 1.0 to 10.0, while δ is often set to 1/n (where n is the minimum client population). Research shows that ε values between 0.1 and 1.0 generally result in less than a 5% drop in image classification accuracy.
"The random noise prevents the model from memorizing details from the training data, ensuring that the training data cannot later be extracted from the model", explain Joseph Near and David Darais at NIST.
Modern implementations often use adaptive clipping, which automatically adjusts the gradient norms, reducing the need for manual tuning. A practical approach combines pre-training on public datasets with fine-tuning on sensitive federated data using DP. For example, Salesforce adopted this strategy in 2023 for customer service AI, cutting privacy risks by 65% while retaining 98% of personalization capabilities.
While DP safeguards individual contributions, Secure Aggregation focuses on protecting data during transmission.
Secure Aggregation
Secure Aggregation (SecAgg) employs cryptographic techniques to ensure that a central server can compute the sum of client updates without accessing individual data. A common method is additive secret sharing, where each client splits its update into random shares. These shares, when combined, reveal only the aggregated result. Alternatives like homomorphic encryption provide similar security but can significantly increase bandwidth requirements - up to 64 times more for a 32-bit value.
SecAgg must also handle client dropouts effectively. By setting recovery thresholds and using reconstruction techniques, the system can accurately compute aggregates even if some participants disconnect. In 2017, Google demonstrated this at scale, using pairwise Diffie-Hellman key agreements alongside secret sharing to support millions of users.
In real-world applications, combining SecAgg with DP creates a robust defense: SecAgg protects updates in transit, while DP prevents sensitive data from leaking through the final model. For added security, Trusted Execution Environments (TEEs) like Intel SGX can manage cryptographic key exchanges when computational overhead becomes a concern. During the 2023 US-UK PETs Prize Challenges, teams like Scarlet Pets and Visa Research used additively homomorphic secret sharing, while others like PPMLHuskies and MusCAT relied on threshold homomorphic encryption.
Mitigating Model Inversion Attacks
While DP and SecAgg address privacy in transit and aggregation, additional steps are needed to counteract model inversion attacks, which aim to reconstruct private data from model updates. A key strategy is gradient mixing, such as replacing MSE loss with CEL, which increases numerical resistance without sacrificing accuracy. Another effective method involves batching similar labels together, maximizing gradient overlap and making it harder to isolate individual data points.
Techniques like input encoding - including MixUp and InstaHide - train models on composite or encrypted images, reducing privacy risks with minimal accuracy loss (usually under 6%). For detecting potential data leakage, Absolute Variation Distance (AVD) has proven more effective than MSE in identifying patterns in reconstructed images. A notable example comes from Massachusetts General Hospital, which in August 2025 used federated learning with DP across five hospitals. This approach improved diagnostic accuracy by 23% without transferring raw data between institutions.
| Defense Mechanism | Impact on Accuracy | Privacy Strength | Complexity |
|---|---|---|---|
| Differential Privacy | Moderate (3–10% loss) | High (Formal) | High |
| Gradient Mixing | Negligible | Moderate (Numerical) | Low |
| Secure Aggregation | None | High (Cryptographic) | High |
| Input Encoding | Low (<6% loss) | Moderate | Medium |
Design Challenges and Solutions
Creating federated learning systems that function effectively at scale involves tackling three key hurdles: managing large client populations, addressing the diverse capabilities of devices, and ensuring consistency in models despite unpredictable connectivity. These challenges demand engineering solutions that go beyond standard machine learning practices.
Scalability in Federated Systems
Traditional architectures often fall short when scaled to millions of devices. A hierarchical design, featuring a three-tier structure with clients at the base, intermediate combiners in the middle, and a central controller at the top, helps distribute aggregation tasks. This approach supports horizontal scaling and ensures better management of massive device populations.
Another key strategy is asynchronous aggregation. Instead of waiting for updates from all devices, the server moves forward once it receives a sufficient number of client updates. This prevents slower devices from holding up the training process. Late submissions are either discarded or assigned weights based on their timeliness. These methods are essential for maintaining efficiency as federated systems scale.
Handling Heterogeneous Client Environments
Federated learning systems must accommodate a wide range of devices, from smartphones and IoT sensors to enterprise servers, each with varying levels of processing power, memory, and network speeds. A one-size-fits-all approach, like standard federated averaging, can limit the system's potential by creating bottlenecks for high-performing devices.
To address this, reinforcement learning–based client selection optimizes participation by framing it as an optimization problem. For instance, FedPRL utilizes Double Deep Q-Learning to assign quality scores to clients, balancing their training speed with their impact on global model accuracy. Adaptive model allocation also plays a role by tailoring model sizes to device capabilities. Techniques like Proximal Policy Optimization allow lightweight models for resource-constrained devices and full-size models for more capable ones.
Communication efficiency is another critical factor. Methods such as sparse updates (transmitting only significant parameter changes), 8-bit quantization, and delta compression can reduce bandwidth usage by up to 95%. These techniques not only improve efficiency but also align with privacy-first principles by minimizing data transmission. Studies reveal that heterogeneity-aware frameworks can cut overall training time by 20.9% to 40.4% while reducing latency caused by slower devices by 19.0% to 48.0%.
"In synchronous FL, the disparity in performance among heterogeneous devices often causes 'straggler problems', where high-performance devices are delayed as they must wait for lower-performance devices." – Xi Chen et al., East China Normal University
Ensuring Model Consistency Across Agents
Once device diversity is addressed, the next challenge lies in maintaining a consistent global model despite asynchronous updates. Strict coordination mechanisms are essential. For instance, staleness thresholds ensure that outdated updates are either discarded or down-weighted, preventing them from disrupting the global model.
In federated reinforcement learning, delay-adaptive lookahead techniques help manage the lag caused by varying gradient arrival times. Global knowledge distillation further supports consistency by preserving learned patterns during updates while adapting to new data from diverse sources. Research shows that employing asynchronous updates and compression in federated systems can reduce average synchronization delays by 85% and failed synchronizations by 83% compared to centralized methods.
To maintain reliability in environments with high dropout rates, threshold-based secure aggregation ensures that aggregation rounds can proceed even if a certain percentage of agents fail to participate. This approach balances privacy and reliability, making it a cornerstone of robust federated learning systems.
Implementation Workflow and Deployment Tips
Start by selecting a model framework such as PyTorch or TensorFlow, and pair it with a networking mechanism like Flower, PySyft, or TensorFlow Federated. When designing your central service, keep it stateless to handle load balancing, authentication, and training session management efficiently. For client-side operations, package the runtime into a Docker image or an installable package to facilitate local training, model loading, and secure updates. Once these foundational decisions are made, follow the steps below to build your federated learning system.
Step-by-Step Implementation Guide
- Client Registration and Dataset Metadata: Build a system for client registration that collects metadata about local datasets. This helps in selecting the right clients for training tasks.
- Secure Aggregation and Privacy Measures: Implement cryptographic protocols for secure aggregation. Add differential privacy by introducing calibrated noise after gradient clipping to protect individual data.
- Optimize Communication: Use techniques like sparse updates, 8-bit quantization, and delta compression to reduce communication overhead. For instance, model quantization can shrink the model size by up to four times.
- Deployment: Once the system is ready, deploy it using established patterns to ensure scalability and functionality.
Deployment Patterns for Federated Systems
Adopt a phased rollout approach to minimize risks. Start with a small pilot group to validate system performance. Afterward, scale up gradually, incorporating privacy measures and monitoring client participation throughout. Maintain consistent environments for Development, Staging, and Production to simplify troubleshooting and updates.
To address client delays (stragglers), set a quorum to process updates from the fastest 80% of clients, rather than waiting for all participants. Additionally, schedule client uploads during periods of low activity, such as idle hours, Wi-Fi usage, or low-power states, to reduce disruptions and save energy.
Monitoring and Maintaining Federated Systems
Effective monitoring ensures long-term performance and privacy compliance. Track global accuracy metrics, client failure rates, data distribution trends, and client drift in each training round. Early detection of anomalies can prevent larger issues.
For large-scale operations, leverage tools like NVIDIA FLARE's FL Simulator or FATE's web-based dashboards to manage workflows. Use exponential backoff for retrying transient failures, gradually increasing delays (e.g., 1s, 2s, 4s). For version control, export workflows as JSON and store them in Git, enabling quick rollbacks - often within five minutes.
In industries with strict regulations, frameworks such as Substra can enhance auditability by logging all platform operations on an immutable ledger. This approach not only ensures compliance but also builds trust in the system's transparency.
Conclusion
The Role of Federated Learning in Privacy-First AI
Federated learning is reshaping how AI models are trained, focusing on local processing to safeguard sensitive information. This method addresses the challenge of balancing advanced AI capabilities with the need for privacy. As Nuria Rodríguez-Barroso from the University of Granada explains, "Trustworthiness is no longer a static property of a trained model but a temporal and lifecycle-dependent condition that can degrade due to concept drift, client churn, or autonomous system decisions". By 2025, the widespread adoption of intelligent edge IoT devices has made on-device training a routine practice, cutting latency and bandwidth costs while prioritizing privacy. This shift toward embedding privacy into design not only ensures compliance with regulations but also fosters user trust through greater transparency. This secure approach sets the stage for outlining critical design principles.
Key Design Principles for Success
For federated learning systems to succeed, several principles are essential. First, keeping local data segregated ensures that raw user data remains on the device or within an organization's boundaries, with only encrypted updates being transmitted. Second, differential privacy adds controlled noise to aggregated updates, providing mathematical protections against reverse-engineering individual data contributions. Third, secure aggregation uses cryptographic methods to ensure that only combined updates from multiple users are visible to the central server, safeguarding individual data. Additionally, effective systems must accommodate diverse client environments, utilize gradient clipping before adding privacy noise, adopt threshold-based aggregation to handle client dropouts, and implement strong encryption protocols. With these foundational principles in place, the focus shifts to practical deployment and ongoing improvement.
Next Steps for Implementing Federated Learning
To implement federated learning effectively, start by assessing your specific use case and the sensitivity of your data. Determine how this approach can help mitigate compliance risks, reduce data transfer costs, or enable secure collaboration across organizations without exposing proprietary information. Begin with a small-scale pilot project to test and refine system performance before expanding. A phased rollout, as discussed earlier, can help ensure smooth scaling. Regularly test for vulnerabilities like data poisoning, model inversion, and prompt injection attacks as part of your maintenance strategy.
For tailored solutions, NAITIVE AI Consulting Agency (https://naitive.cloud) offers expertise in designing, building, and managing privacy-focused AI systems. Their consulting services can guide you through the complexities of federated learning, ensuring your implementation meets industry standards and regulatory demands.
FAQs
Does federated learning fully prevent sensitive data leaks?
Federated learning helps reduce the risk of sensitive data leaks by keeping raw data on local devices and only sharing model updates. However, it's not foolproof. Vulnerabilities and privacy attacks remain possible, so while it lowers exposure, it doesn't provide complete privacy protection.
How do I choose privacy settings like epsilon without harming accuracy?
When deciding on privacy settings, such as epsilon in federated learning, it's important to strike a balance between protecting user data and maintaining model accuracy. One effective approach is using adaptive differential privacy techniques, which allow for dynamic adjustments to the privacy budget (epsilon) throughout the training process. This flexibility helps achieve a better trade-off between privacy and performance.
Additionally, methods like secure aggregation and calibrated noise injection can enhance data protection while keeping accuracy losses minimal. The real key lies in iterative tuning - fine-tuning these settings based on the specific requirements of your use case to find the best balance between privacy and accuracy.
What are the biggest deployment pitfalls for federated AI agents?
Federated learning comes with its share of challenges, including security vulnerabilities, privacy concerns, and implementation hurdles. In IoT environments, these systems can be particularly susceptible to cyber-attacks. Privacy risks also emerge if model updates are not properly secured, potentially exposing sensitive data.
Beyond security and privacy, there are technical obstacles like dealing with incomplete or inconsistent labels, adapting to changing environments, and finding the right balance between protecting privacy and maintaining model accuracy. Successful implementation hinges on strong governance, robust identity management, and context-aware controls to safeguard privacy, enhance security, and build trust in the system.


