Building Scalable Knowledge Retrieval Systems
Build modular, cost-efficient retrieval systems that scale to millions of documents using hybrid search, vector databases, caching, and incremental updates.

Knowledge retrieval systems are tools that connect AI models to external databases, enabling them to access and use up-to-date and domain-specific information. They address common AI limitations like outdated data and unreliable outputs by grounding responses in verified sources, often by choosing between finetuning vs. RAG based on the use case. These systems typically have four components: Ingestion Pipeline, Retrieval Engine, Generation Engine, and Orchestrator.
Key Takeaways
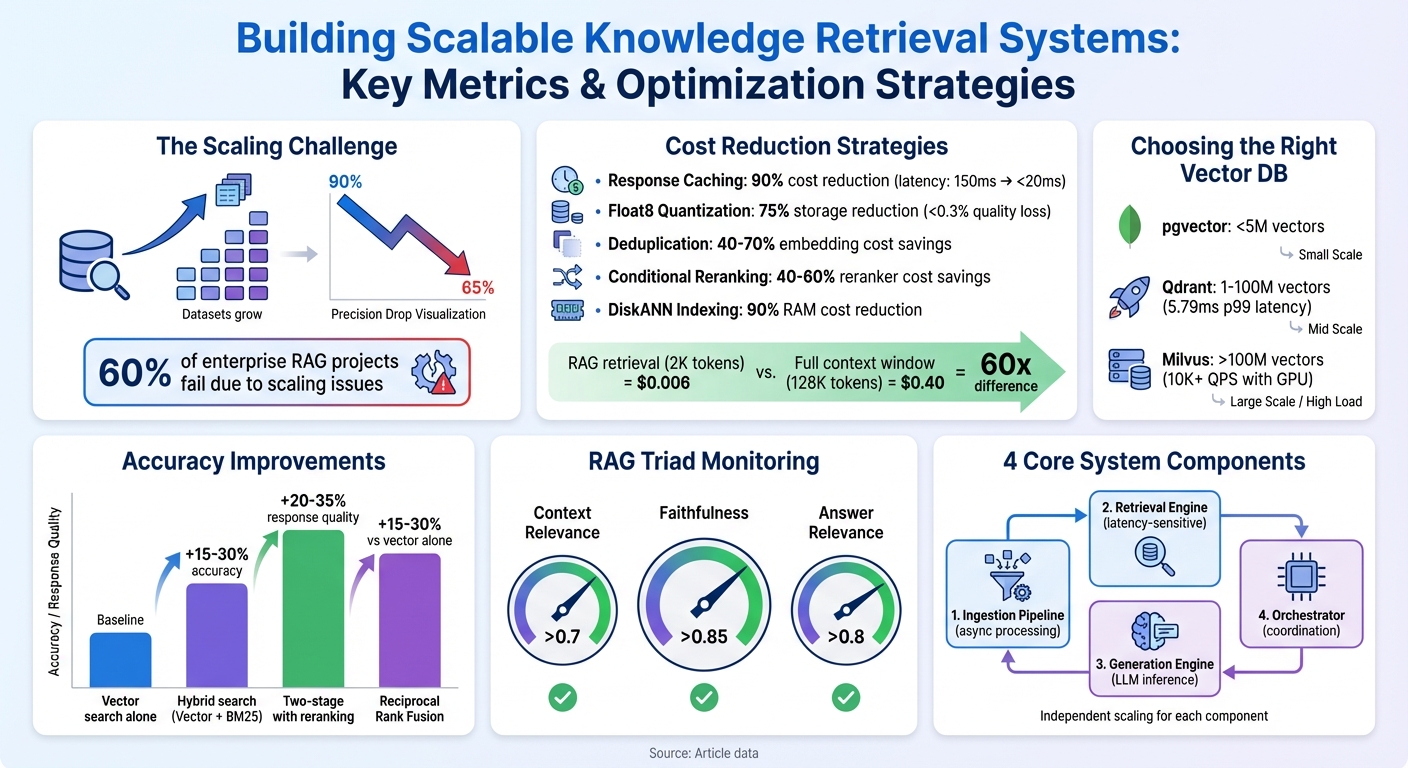
- Scalability is critical: Many systems fail due to performance drops when scaling to millions of documents. Precision can drop from 90% to 65% as datasets grow.
- Cost management: Token processing costs can escalate quickly - efficient architectures and caching strategies are essential to keep costs under control.
- Hybrid retrieval improves accuracy: Combining dense vector search with sparse keyword search (e.g., BM25) enhances precision by 15–30%.
- Optimized storage: Tools like Qdrant and Milvus handle large datasets with low latency, while techniques like quantization reduce storage costs.
- Dynamic updates: Incremental indexing and real-time updates ensure knowledge bases remain current without performance issues.
Quick Tips for Success
- Use a modular architecture to allow independent scaling of components.
- Employ two-stage retrieval for better accuracy with minimal latency impact.
- Leverage deduplication and quantization to reduce costs.
- Integrate human oversight for quality checks and continuous improvement.
This article dives deeper into the architecture, tools, and strategies needed to build scalable systems that remain efficient and cost-effective.
Knowledge Retrieval Systems: Key Performance Metrics and Cost Optimization Strategies
Advanced RAG Techniques: Optimizing Retrieval for LLMs at Scale
Core Architecture of Scalable Knowledge Retrieval Systems
Building scalable systems for knowledge retrieval requires dividing responsibilities into four key services: Ingestion, Retrieval, Generation, and Orchestration. Each of these operates independently, allowing them to scale separately and handle failures more effectively. This modular design is crucial when dealing with millions of documents and thousands of queries every second. As Sitanand explains, production-level RAG systems are distributed and rely on asynchronous components, which demand thoughtful architectural design.
Document Storage and Vector Databases
A well-structured, decoupled architecture sets the foundation for scalability, but efficient storage is equally critical. Vector databases transform text into numerical embeddings, enabling similarity searches across massive datasets in just milliseconds. For smaller datasets (under 5 million vectors), pgvector - a PostgreSQL extension - offers a simple solution. However, as datasets grow beyond 10 million vectors, performance diminishes, necessitating specialized tools.
For mid-sized datasets (1–100 million vectors), Qdrant delivers excellent performance, achieving a p99 latency of just 5.79 milliseconds. For extremely large datasets (over 100 million vectors), Milvus with GPU acceleration can handle billions of vectors while maintaining throughput above 10,000 queries per second.
The choice of indexing algorithm also plays a critical role. HNSW (Hierarchical Navigable Small World) provides sub-2ms latency for mid-sized datasets but requires significant RAM - around 4GB for every 1 million 768-dimensional vectors. For more memory-efficient operations, DiskANN, used by Microsoft Bing, stores vectors on SSDs instead of RAM, cutting memory usage by 90% while maintaining high recall rates.
Cost-saving techniques like Float8 quantization can compress vectors by 4× with less than a 0.3% loss in accuracy. Additionally, deduplication via content hashing can reduce embedding and storage costs by 40–70%. For context, storing embeddings for a 10-million-document corpus with 1024 dimensions requires approximately 40 GB of vector storage.
Retriever Mechanisms for Query Matching
The retriever is responsible for converting user queries into embeddings and identifying relevant documents. Modern systems often employ hybrid retrieval, which combines dense vector search for semantic understanding with sparse keyword search (BM25) for precise lexical matching.
A two-stage retrieval process is common. In the first stage, a fast retriever identifies 50–100 candidate documents. Then, a cross-encoder reranker evaluates these candidates to select the top 10 most relevant results, improving accuracy by 20–35%. While reranking adds 100–200 ms of latency and incurs a minor cost per query, the improvement in precision is often worth it.
Metadata filtering is another essential component, ensuring security and relevance. Tools like Qdrant and pgvector support SQL-like filters, enabling features such as tenant isolation and permission controls alongside vector similarity searches.
Caching strategies can further optimize performance and reduce costs. For instance, caching results for semantically similar queries (cosine similarity above 0.95) allows rapid responses using a cache layer like Redis.
Integration of Generative Language Models
With storage and retrieval optimized, the next step involves integrating generative language models (LLMs). These models don’t just recall information - they analyze and synthesize responses based on retrieved context. Instead of relying on their entire training data, LLMs focus exclusively on the provided context. The generation engine compiles document chunks into a prompt for the LLM to create a coherent and grounded response.
To refine retrieval accuracy, the LLM can rewrite vague queries, expand acronyms, or generate hypothetical answers (HyDE), potentially improving performance by 20–35%. However, this preprocessing step adds 200–500 ms to latency.
Failures during the generation phase account for 15–30% of RAG system issues, often because the LLM ignores the provided context. To address this, production systems include verification layers where a secondary LLM fact-checks the primary model’s output against source documents. Explicit instructions, such as "Base your answer ONLY on the provided context", also help maintain accuracy.
To manage costs, route simpler queries to smaller models like GPT-3.5 ($0.002 per 1,000 tokens) and reserve complex tasks for GPT-4 ($0.03 per 1,000 tokens). This approach can cut generation expenses by over 80%. Additionally, retrieving 2,000 relevant tokens via RAG is about 60 times more cost-efficient than filling a 128,000-token context window with an entire knowledge base.
Preparing and Indexing Knowledge Bases
Laying the groundwork for a scalable and efficient retrieval system starts with properly preparing and indexing your knowledge base. As Arian Pasquali from Faktion points out, "If your users struggle to find information through traditional means, AI agents won't magically solve the problem - they'll likely amplify existing gaps and inconsistencies". In other words, the quality of your foundation determines whether your system can handle growth or buckles under pressure. The process begins with systematic ingestion and parsing of your documents.
Document Ingestion and Parsing
The first step is to catalog all your information sources - think technical manuals, wikis, meeting transcripts, and more. For example, in April 2025, a European telecommunications company tackled fragmented search results across multiple systems. They implemented an automated pipeline using Scrapy-based web crawlers and Azure Functions to consolidate data from public websites and on-premises SharePoint repositories. This effort resulted in a centralized, real-time searchable knowledge base, eliminating the need for manual indexing.
Parsing documents of various formats requires specific tools. PDFs, PowerPoint files, and Word documents need text extraction, while scanned files require OCR technology to capture tables and text blocks [18,19]. Scale AI provides a good example of this process in action, ingesting documents at a rate of about 500 MB per hour with fewer than 100 worker nodes. When indexing websites, using canonical URL patterns helps avoid duplicates and ensures better search quality. Once your documents are parsed, the next step is to focus on optimizing how the information is chunked and embedded.
Chunking and Embedding Optimization
How you break down your documents into chunks significantly impacts retrieval accuracy. Semantic chunking - splitting content at natural boundaries like paragraphs or sections - helps maintain the document's structure and improves recall rates from 75–80% (using fixed-size chunks) to 90–93%. For technical documents, structure-aware chunking is particularly useful. It preserves elements like tables, headers, and lists, avoiding fragmentation that could lower retrieval precision from 85% to 62% as your knowledge base grows.
Token-based splitting, with a 10–20% overlap (128–500 characters), ensures context is preserved and aligns with the limits of embedding models. For instance, OpenAI's text-embedding-3-small model has an 8,191-token limit; exceeding this threshold leads to truncation and data loss. The "Parent-Child" retrieval method is another effective strategy. It indexes smaller chunks for precise matches while retrieving larger parent chunks to provide context, achieving recall rates of 88–91%.
To manage large datasets, techniques like locality-sensitive hashing can identify near-duplicate content. OpenAI's text-embedding-3-small model, priced at $0.02 per 1 million tokens, delivers 96% of the quality of larger models but at just 15% of the cost, making it a practical choice for production. Optimizing chunking and embedding is crucial to maintain both high recall and precision as your database scales.
Indexing Strategies for Large Datasets
Efficient indexing strategies are key to handling larger datasets. A dual-index approach works well: maintain a "Main Index" for static, historical data and a "Real-Time Index" for new, dynamic data. This ensures that fresh information is accessible almost instantly without compromising system performance. Modern architectures also decouple compute and storage, allowing each to scale independently. For example, object storage solutions like AWS S3, priced at $0.06 per GB per month, can cut costs by 77–92% compared to specialized providers.
Techniques like blue-green indexing, where new indexes are built in parallel with live ones, help avoid downtime during schema updates or model changes [2,4]. Additionally, pre-warming caches with synthetic queries during deployment can reduce cold-start latency, ensuring faster response times right from the start. These strategies collectively enhance system scalability and reliability, even as datasets grow in size and complexity.
Improving Retrieval and Response Quality
After indexing your knowledge base, the next big task is making sure your system consistently delivers accurate and relevant results. High-quality retrieval separates a basic system from one that can truly scale.
Evaluating and Selecting Embedding Models
Choosing the right embedding model is crucial for delivering reliable results. The Massive Text Embedding Benchmark (MTEB) is a go-to standard for comparing model performance across tasks. Metrics like Normalized Discounted Cumulative Gain (NDCG@10), which measures how well top results align with user needs, and Mean Average Precision (MAP), which assesses ranking quality, are key indicators.
Recent benchmarks highlight Voyage-large-2 as a top performer with an MTEB score of 65.89, followed by Cohere embed-v4 at 65.2 and OpenAI's text-3-large at 64.6. Cost is another factor to weigh - OpenAI's text-embedding-3-small, for example, is priced at just $0.02 per 1 million tokens. For industries like legal or medical, fine-tuning open-source models such as BGE-M3 with domain-specific data can improve recall by 3–8%. To handle large-scale deployments efficiently, Float8 quantization offers 4× memory compression with minimal quality loss (less than 0.3%).
Once retrieval reliability is established, selecting the right embedding model becomes the next essential step in optimization.
Post-Retrieval Processing Techniques
Retrieving documents is just the first step - how you refine and present those results to your language model is equally important. Two-stage retrieval is now a standard practice for production systems. The first stage uses hybrid search (combining vector and keyword matching) to retrieve 50–100 candidates. Then, a cross-encoder reranks the top 10 for final generation. This method can improve accuracy by 20–35%, with Cohere Rerank 3.5 showing a 23.4% boost over hybrid search alone on the BEIR benchmark.
Another effective technique is Reciprocal Rank Fusion (RRF), which merges results from semantic and lexical searches. This approach typically improves accuracy by 15–30% compared to vector search alone. To manage costs, consider conditional reranking, enabling expensive rerankers only when the top candidate's confidence score is below 0.7. For example, Azure's Semantic Ranker can process fifty 2,048-token documents in just 158 ms, making real-time reranking a practical option.
To ensure context is preserved, use Parent Document Retrieval. This method avoids missing critical information in lengthy prompts by maintaining the broader context. Continuously monitor the "RAG Triad" metrics: Context Relevance (target > 0.7), Faithfulness (target > 0.85), and Answer Relevance (target > 0.8) to maintain high-quality outputs.
Maintaining Accuracy with Human-in-the-Loop Systems
While automation improves precision, human oversight is essential to catch nuanced errors. Automated metrics are useful but often fall short when dealing with ambiguous or complex queries. Subject matter experts (SMEs) play a key role in providing "ground truth" evaluations and identifying mistakes that algorithms might overlook. Human reviewers should assess factors like query relevance, factual accuracy, coherence, and task completion - areas where metrics like BLEU or ROUGE may not fully capture quality.
Dashboards can help monitor query patterns and flag areas of user dissatisfaction, allowing for targeted human intervention. Incorporating continuous feedback and self-correcting loops ensures the system remains grounded and aligned with real-world needs.
Scaling Challenges and Solutions
When scaling systems, achieving accuracy is just the beginning. Scaling introduces new challenges that require thoughtful redesign and optimization. Let’s dive into some of the biggest hurdles and practical solutions.
Handling Large-Scale Knowledge Bases
As your knowledge base expands from tens of thousands to tens of millions of documents, maintaining retrieval precision becomes a challenge. For instance, precision can drop from 85% to 62% due to issues like semantic drift and false positives. To address this, modular system design is crucial. A well-structured production system typically includes four key services:
- Ingestion: Handles asynchronous data processing.
- Retrieval: Manages latency-sensitive search operations.
- Generation: Handles large language model (LLM) inference.
- Orchestration: Coordinates processes across the system.
This modular approach allows each component to scale independently, ensuring better performance.
For datasets exceeding 100 million vectors, DiskANN becomes a game-changer. While HNSW achieves sub-2ms latency, it requires about 4GB of RAM per 1 million vectors. DiskANN, on the other hand, stores vectors on SSDs, cutting RAM costs by 90%. It does come with a tradeoff: query latency increases by 2–5 times, but this is often acceptable for extremely large datasets.
Another powerful technique is parent-child retrieval, which reduces token usage by 80–85% without losing context. For example, Uber significantly optimized their indexing process by using Amazon OpenSearch with FAISS. This reduced their ingestion time from 12.5 hours to just 2.5 hours and brought P99 latency down from 250ms to under 120ms - all through blue-green deployment strategies.
Scaling isn’t just about handling volume - it’s also about keeping your knowledge base up to date, which introduces its own set of challenges.
Managing Dynamic Knowledge Updates
Keeping your knowledge base fresh while maintaining performance is no small feat. In fact, around 60% of enterprise retrieval-augmented generation (RAG) projects fail because they struggle to keep data current at scale. As David Richards, a technology expert, explains:
"The problem is that most RAG implementations treat knowledge bases as static rather than continuously updated systems."
One solution is incremental indexing, which processes only the modified portions of documents. This approach can cut update times from hours to seconds. For systems requiring real-time updates, a dual-index approach works well: maintain a large "Main Index" for historical data and a smaller "Real-Time Index" for recent updates. Queries are then federated across both indexes.
However, updating embedding models can lead to embedding drift. If you update a model without re-indexing, you risk "version skew", where new queries and old documents exist in incompatible vector spaces. To avoid this, build a new index in parallel with the live one, validate it thoroughly, and only switch over when confidence is high.
For near real-time (NRT) capabilities, streaming ingestion is key. Data flows into a message queue (e.g., Apache Kafka) and through a stream processor (e.g., Apache Flink) for real-time embedding and indexing. This ensures new data becomes searchable within seconds or minutes. To monitor freshness, track metrics like "Maximum Staleness" and "Update Lag".
Once dynamic updates are under control, the next hurdle is managing costs while maintaining performance.
Balancing Performance and Cost
Scaling can quickly drive up token costs - from $500 to $50,000 per month if left unchecked. To manage this, you need a multi-layered approach that balances cost savings with system quality.
Multi-tier caching is a great starting point. Production RAG systems report cache hit rates of 60–80%, reducing median latency from 150ms to under 20ms. Caching works across three levels:
- Embedding caches: Save 40–70% of processing time.
- Retrieval caches: Achieve 60–80% hit rates.
- Response caches: Cut generation costs by 90%.
Another cost-saving measure is vector quantization. By applying Float8 quantization, you can compress vectors by 4x with less than 0.3% quality loss. For instance, storing 1 million 1,536-dimensional vectors drops from 6.1GB to just 1.5GB - a 75% reduction. Combining this with 50% PCA dimension reduction offers an 8x compression with minimal impact on accuracy.
Conditional reranking is another effective strategy. Instead of applying expensive cross-encoder rerankers to every query, use them only when the top candidate’s confidence score falls below 0.7. This approach saves 40–60% on reranking costs while maintaining 90% of accuracy improvements.
To further cut costs, deduplicate data during ingestion. By hashing document content before embedding, you can eliminate duplicates. Production systems report deduplication rates of 40–70%, significantly lowering embedding expenses. For batch processing tasks like initial indexing, OpenAI's batch API can save up to 50% on embedding costs.
Finally, implement model tiering to allocate resources wisely. Use faster, cheaper models like GPT-3.5 for straightforward queries, reserving premium models like GPT-4 for complex tasks. For context, filling a 128K context window costs about $0.40 in input tokens, while retrieving 2K relevant tokens via RAG costs just $0.006 - a 60x difference.
| Strategy | Cost Impact | Performance Impact |
|---|---|---|
| Response Caching | Cuts generation costs by 90% | Latency drops from ~150ms to <20ms |
| Float8 Quantization | Reduces storage costs by 75% | <0.3% quality degradation |
| Deduplication | Lowers embedding costs by 40–70% | No impact on retrieval quality |
| Conditional Reranking | Cuts reranker costs by 40–60% | Preserves 90% of accuracy gains |
| DiskANN Indexing | Reduces RAM costs by 90% | 2–5x increase in query latency |
Conclusion
Summary of Best Practices
Building an enterprise-scale knowledge retrieval system takes more than simply connecting a vector database to a large language model (LLM). The key lies in adopting a decoupled microservices architecture. This means designing your system as a collection of independent services - each handling tasks like ingestion, retrieval, generation, and orchestration - rather than relying on a linear pipeline. Such an approach ensures that each part of the system can scale independently and manage failures more effectively.
For retrieval, a hybrid search strategy that combines dense vectors with BM25 keyword matching is a strong starting point. To enhance results, a two-stage process using cross-encoders for reranking can improve accuracy by 15–30% and boost response quality by 20–35%. Interestingly, how you structure or split documents can have a more significant impact on performance than the choice of embedding model.
To maintain system performance, automated frameworks like RAGAS and ARES are invaluable for monitoring metrics such as Context Relevance, Faithfulness, and Answer Relevance. Cost control measures - like semantic caching, vector quantization, conditional reranking, and deduplication - can reduce token costs by 80–90% when compared to basic implementations. These practices underscore the importance of expert insights to ensure your system’s success.
The Role of AI Consulting in System Design
One of the biggest pitfalls in Retrieval-Augmented Generation (RAG) systems is their high failure rate - up to 90% within the first three months - often due to underestimated scaling challenges. This is where specialized AI consulting firms like NAITIVE AI Consulting Agency (https://naitive.cloud) play a crucial role. These experts help navigate the "complexity tax", which includes challenges like non-linear cost scaling, multi-tenant isolation, and distributed system failures that can derail production systems.
Consulting agencies offer critical benchmarking expertise, guiding you in selecting the right vector database for your needs. For instance, pgvector is suitable for simpler setups, while Milvus is ideal for managing billions of vectors. They also implement enterprise-grade security features, such as PII redaction, role-based access control, and SOC 2/HIPAA compliance. Moreover, they help prevent common mistakes like missing key content, overlooking top-ranked documents, or providing overly broad or narrow results. Working with experts not only helps avoid these pitfalls but also sets the stage for future advancements.
Future Trends in Knowledge Retrieval
The future of knowledge retrieval is moving beyond static retrieve-and-generate pipelines toward more dynamic systems. Emerging agentic RAG architectures are a game-changer. These systems use autonomous agents to plan multi-step retrieval tasks, validate their findings, and adaptively use tools instead of following rigid workflows.
New techniques are also shaping the field. GraphRAG is becoming popular for handling relationship-heavy queries, while late interaction methods like ColBERT offer the precision of cross-encoders with reduced latency. Additionally, "small-to-big" retrieval strategies - where smaller "child" chunks are indexed for precision but larger "parent" documents are retrieved for context - are gaining traction. Even with expanding context windows, RAG remains the go-to approach for scalability, offering a cost advantage of roughly 60× compared to filling massive context windows for every query.
FAQs
How do hybrid retrieval methods improve the performance of knowledge retrieval systems?
Hybrid retrieval methods elevate the performance of knowledge retrieval systems by blending different search techniques to strike a balance between precision and recall. For instance, they combine semantic search, which interprets the meaning and context behind queries, with keyword-based methods, which are effective at matching exact terms. This mix helps ensure the system delivers results that are both relevant and thorough, while cutting down on irrelevant matches.
These approaches often include reranking processes, where an initial batch of results is fine-tuned using advanced models to improve accuracy even further. By drawing on the strengths of various techniques, hybrid retrieval systems offer a more dependable and scalable solution. This makes them particularly well-suited for enterprise settings, where accuracy plays a key role in driving decisions and maintaining efficiency.
How can I reduce costs when managing large-scale knowledge retrieval systems?
Reducing expenses for large-scale knowledge retrieval systems requires a mix of thoughtful design and smart optimization techniques. One impactful strategy is architectural optimization. For example, using message queues to separate system components allows for independent scaling, reduces bottlenecks, and boosts efficiency - all of which can help cut operational costs.
Another practical approach is caching responses from large language models (LLMs). Reusing previous outputs not only trims down API call expenses but also eliminates redundant computations, making the system more cost-efficient. On top of that, incorporating high-performance vector databases with low latency and strong recall rates can further streamline retrieval costs.
Lastly, using hybrid search methods - a blend of semantic and traditional search - alongside techniques like reranking and query transformation, can improve retrieval accuracy while minimizing unnecessary processing. These strategies ensure your system stays scalable, efficient, and capable of meeting enterprise demands without overspending.
Why is modular architecture essential for scaling enterprise knowledge retrieval systems?
A modular architecture plays a crucial role in scaling enterprise knowledge retrieval systems by offering flexibility, efficiency, and streamlined management. By dividing the system into separate components - such as data ingestion, embedding, retrieval, and response generation - each part can be fine-tuned individually. This approach ensures the system can handle increasing data volumes and user demands without compromising performance.
This design also supports the integration of specialized tools, like advanced vector databases or custom ranking methods, enhancing the system's scalability and reliability. On top of that, modular architecture simplifies tasks like troubleshooting, system updates, and ensuring compliance with enterprise security and governance requirements. In short, it provides a strong framework for building systems that can manage millions of queries efficiently and cost-effectively.
